问题的特点
机器翻译有两个特点:
- 输入和输出的长度是不固定的。在机器翻译中,输入的源语言的长度往往是不固定的,而输出的结果也是如此。
- 输入和输出的序列之间往往有顺序关系。对于语言学上的一个句子,词语之间的前后往往是有顺序关系的,存在上下文语境的关联。
框架
根据机器翻译的这两个特点,基于循环神经网络的机器翻译,采用从序列到序列(seq2seq)的框架:
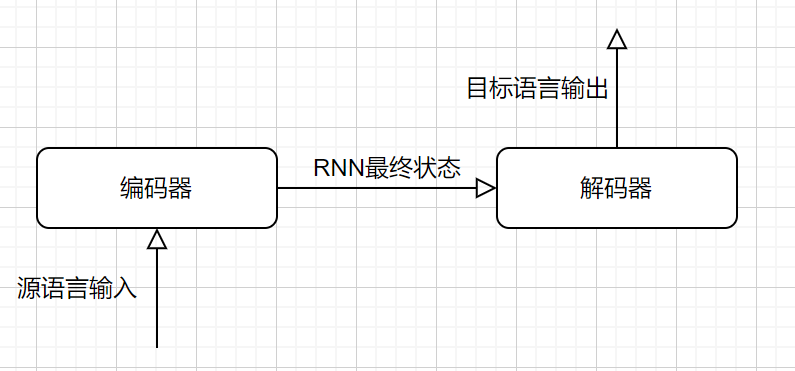
翻译的基本原理
我们首先解决第一个问题:
以序列到序列模型为框架的神经机器翻译的原理.
考虑中英翻译,首先我们有一个源语言句子,不妨假设是:“广州是一座城市。”对于该句子,我们可以以单个字作为划分标准,也可以以词语作为划分标准。考虑以词语作为划分标准。
我们展开上述的框架:
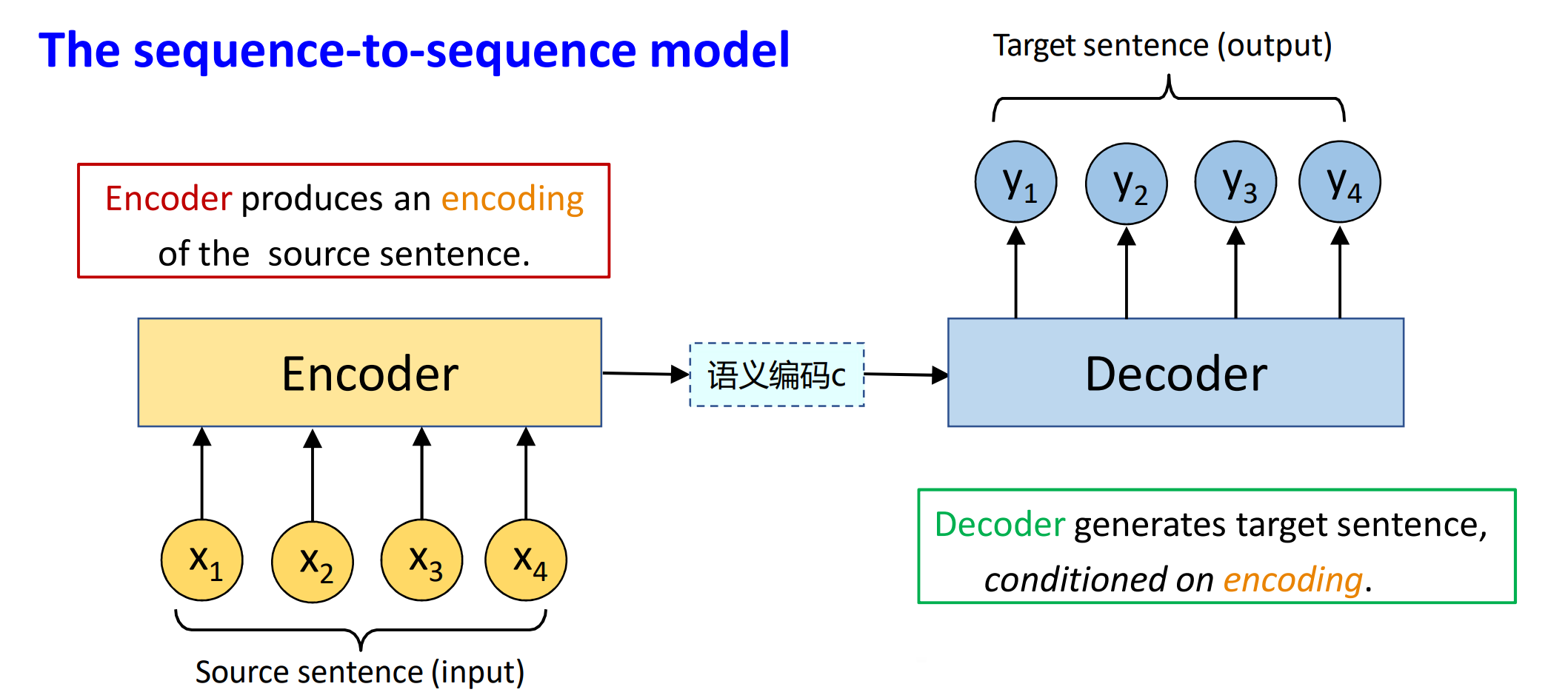
编码器对应于输入序列,将输入序列的信息编码到上下文变量中;解码器对应输出序列,将语义编码解码成输出序列。
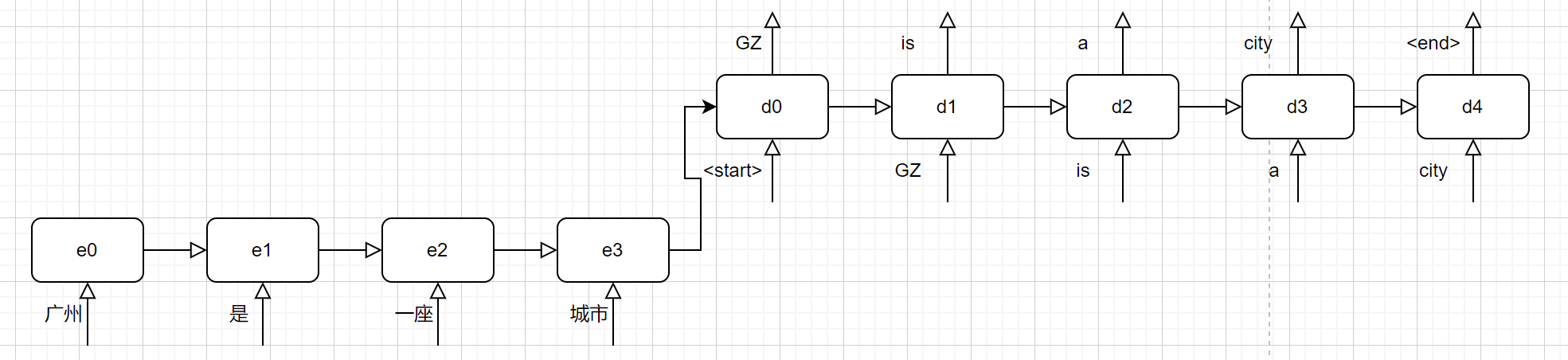
编码器
我们关注这样一个问题:
解释编码器的作用.
很简单的解释,编码器的作用就是将一个不定长的输入序列,通过一系列的矩阵向量运算,转变成为一个定长的语义编码。该语义编码包含了整个序列上下文的信息。
其工作方式也很简单,首先对输入的句子进行编码,方式有很多,可以采用word2vec,也可以采用其他方法。每个词语编码成为一个向量后,得到一个序列$[x_1,x_2,..,x_T]$。其中$x_i$表示第$i$个词语编码后的词向量,按顺序输入进入编码器当中。
编码器由循环神经网络(RNN)构成,在此先简单介绍最简单的循环神经网络。网络结构如下:
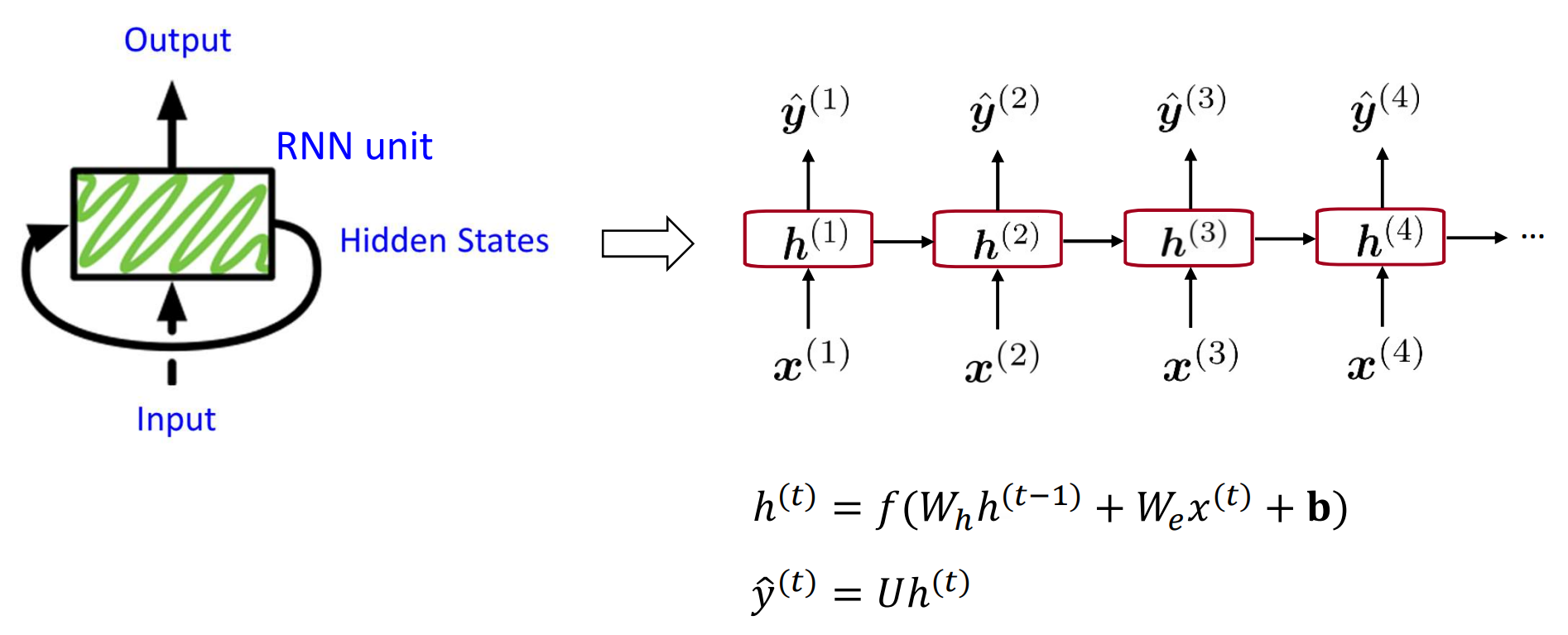
左侧部分是单个的RNN单元,右侧部分是RNN展开后的结构。普通RNN的原理其实很简单,上图已经描述得非常清楚了。$x^{(i)}$是输入的词向量,$h^{(i)}$是当前RNN单位的隐状态,$\hat{y}^{(i)}$是当前单元的输出,包含了从句子的开头到这个单词位置的这部分句子的上下文信息。将整个句子的信息输入到该编码器后,得到的$\hat{y}^{(T)}$即为一个包含了整句话信息的矩阵,即语义编码。
计算公式如下:
\[\begin{aligned} &h^{(t)}=f\left(W_{h} h^{(t-1)}+W_{e} x^{(t)}+\mathbf{b}\right) \\ &\hat{y}^{(t)}=U h^{(t)} \end{aligned}\]其中,$W_h$、$W_e$和$U$是需要训练的参数,$\mathbf{b}$是偏置项,函数$f$表达循环神经网络隐藏层的变换。
最后的语义编码$c$即为$\hat{y}^{(T)}$,即最后一个词语输入后的上下文输出。
解码器
解释解码器的作用.
解码器的作用为,将语义编码解码成输出序列,完成目标语言的翻译。
解码器和编码器的结构是一样的。解码器的隐状态输入$h^{(0)}$为编码器输出的语义编码,而$x^{(i)}$为解码器解码出来的上一个单词的词向量,$y^{(i)}$为当前单元输出的各个单词可能选取的概率向量,向量的维度为词表的大小。特别值得注意的是,第一个RNN单元的词向量的输入是一个特殊的单词<start>,表示句子的开始。翻译结束的标志是,编码出一个特殊的单词<end>,该标记表示句子的结束。
刚刚已经介绍,编码器输出的语义编码 $\boldsymbol{c}$ 编码了整个输入序列 $x_{1}, \ldots, x_{T}$ 的信息。解码器 通过将语义编码 $\boldsymbol{c}$ 中的信息解码生成输出序列。给定训练样本中的输出序列 $y_{1}, y_{2}, \ldots, y_{T^{\prime}}$ ,对解码阶段每个时间步 $t^{\prime}$ ,解码器输出 $y_{t^{\prime}}$ 的条件概率将基于之前的输出序列 $y_{1}, \ldots, y_{t^{\prime}-1}$ 和语义编码 $\boldsymbol{c}$ ,即 $\mathbb{P}\left(y_{t^{\prime}} \mid y_{1}, \ldots, y_{t^{\prime}-1}, \boldsymbol{c}\right)$ 。用下面的公式表示输出序列的联合概率函数: \(\mathbb{P}\left(y_{1}, \ldots, y_{T^{\prime}} \mid x_{1}, \ldots, x_{T}\right)=\prod_{t^{\prime}=1}^{T^{\prime}} \mathbb{P}\left(y_{t^{\prime}} \mid y_{1}, \ldots, y_{t^{\prime}-1}, \boldsymbol{c}\right)\) 根据计算公式可以发现,之前的输出序列 $y_{1}, \ldots, y_{t^{\prime}-1}$ 和语义编码 $\boldsymbol{c}$ ,即为上一个RNN单元传递过来的隐状态$h^{(i-1)}$。
对于当前状态,解码的结果是一个词表大小维度的概率向量,表示当前这一步翻译出每个单词的概率。那么,根据该概率向量,怎么解码出对应的单词呢?
介绍三种不同的神经机器翻译解码策略(decoding strategies).
最简单的一种方法,就是贪心地选取概率最大的单词。这种方法很直观,效率也很高,并且有一定的效果。但是这个方法存在一个问题,观察下面这个例子:

当我们翻译出“a”的时候,实际上已经出现了翻译错误了,而我们是无法进行撤销操作的,这样就会导致错误的结果。
这个问题如何解决呢?我们观察我们的目标:
\[\mathbb{P}\left(y_{1}, \ldots, y_{T^{\prime}} \mid x_{1}, \ldots, x_{T}\right)=\prod_{t^{\prime}=1}^{T^{\prime}} \mathbb{P}\left(y_{t^{\prime}} \mid y_{1}, \ldots, y_{t^{\prime}-1}, \boldsymbol{c}\right)\]我们的目标是使该条件概率尽可能地大。我们对等式两边取$log$,这不改变函数的性质:
\[\operatorname{score}\left(y_{1}, \ldots, y_{t}\right)=\log P_{\mathrm{LM}}\left(y_{1}, \ldots, y_{t} \mid x\right)=\sum_{i=1}^{t} \log P_{\mathrm{LM}}\left(y_{i} \mid y_{1}, \ldots, y_{i-1}, x\right)\]我们定义取$log$后的结果为当前翻译序列的得分,得分越高,那么该序列更可能代表翻译的结果。
那么我们引出了一个方法,我们保留所有可能出现的序列,计算其$sorce$,选取得分最高的一个序列,也叫穷举搜索。这个方法下,我们能够精确地选取出最优的翻译结果。但是这个方法有一个更加严重的问题:复杂度爆炸。
我们假设词表的大小为$N$,翻译序列的长度为$T$。对于第一个单元,我们保留所有$N$个单词及其分数;对于第二个单元,我们根据第一个状态的$N$个单词,分别计算条件概率,上一个状态的每一个单词需要计算词表大小$N$次条件概率,那么我们进行了$N^2$的运算,此时存储的序列大小为$2N^2$。经过$T$轮,最终得到$N^T$个序列,我们选取得分最高的一个(其实不是,下面会解释)为翻译结果。
根据上述分析,时间复杂度为和空间复杂度均为$O(N^T)$,这是我们无法接受的复杂度。
这两种方法实际上代表了两种极端,前者效率高而效果一般,后者效果好但是效率太低,我们考虑两种方法的折中,命名为beam search。
我们同样考虑让$score$尽可能的大,但是我们不保存所有可能出现的序列。对于每个状态,我们只保留得分最高的$k$个序列。下面举一个例子:
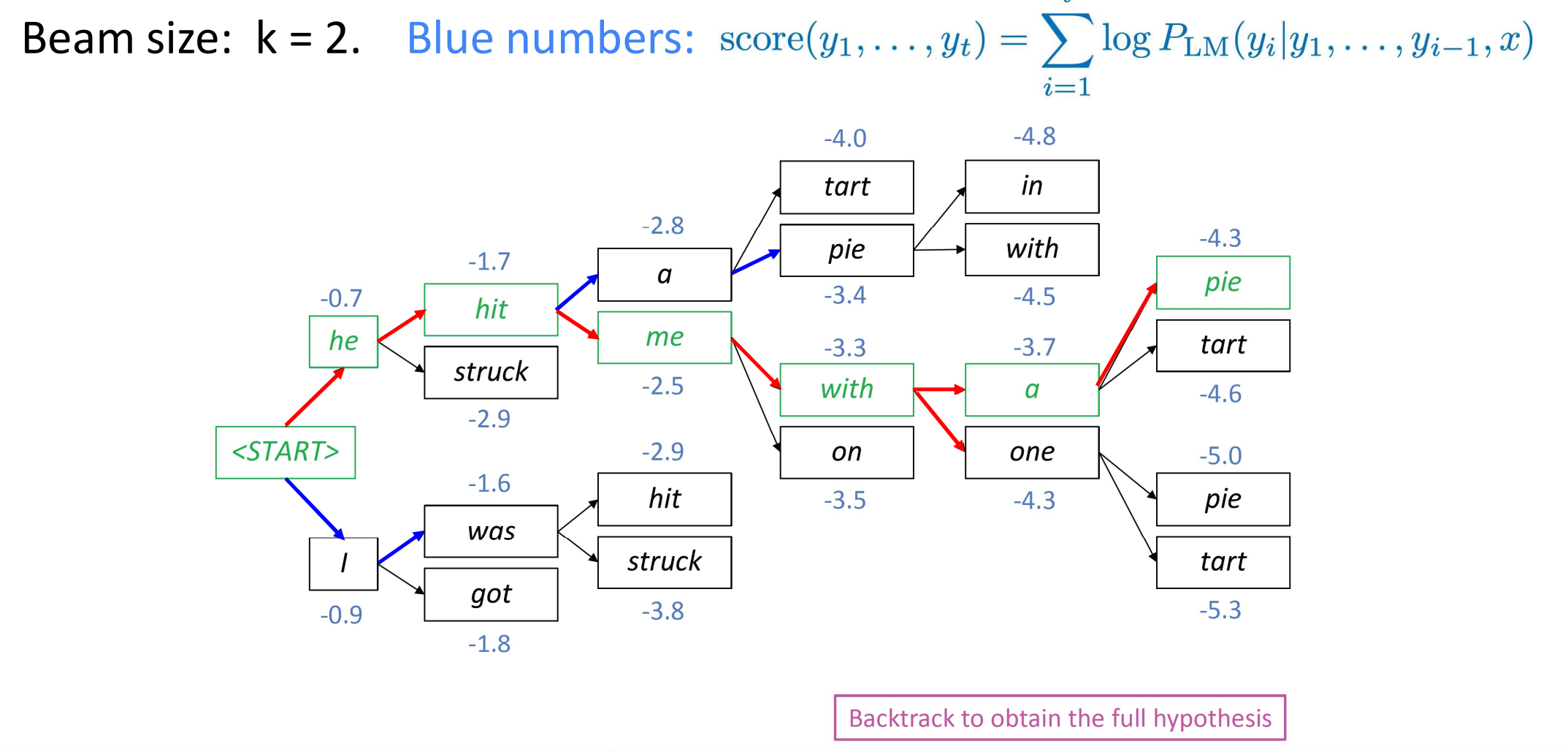
不妨假设$k$为2,对于当前状态,我们保存了上一个状态得到的得分最高的两个序列。对于每一个序列,计算条件概率,保留得分最高的两个序列,因此一共得到4个序列,在这四个序列中保存得分最高的两个序列。这个方法在尽可能保留更多的序列以使得全局条件概率尽可能高的同时,通过贪心使得复杂度降低。
考虑这个过程的结束条件。在贪心的策略中,编码出<end>即为序列编码结束。而在beam search的过程中,在当前时间步中,最优的$k$个序列中,也可能已经出现了结束标记,不妨假设出现了$a$个,$a\leq k$。这个时候,我们需要将这些序列保存为最终的待选答案之一,并将$k$的大小减小$a$,继续进行计算,直到$k$的大小为0。
最终得到的$k$个序列,我们单纯贪心地选择得分最高的序列吗?
考虑一个对概率$log$后函数的性质,对概率取对数后,得分是一个负数。那么,当序列的长度越长的时候,得分实际上会越低。如果单纯地选择得分最高的序列,那么每次都有很大概率会选取长度更短的序列,这样显然会有问题。采取一种取平均的方案,即对于一个序列最终的得分,为$score$除于序列的长度。我们在最终得分中,选择最高的,即为解码的结果。公式表达如下:
\[\frac{1}{t} \sum_{i=1}^{t} \log P_{\mathrm{LM}}\left(y_{i} \mid y_{1}, \ldots, y_{i-1}, x\right)\]网络训练部分
整个网络工作的原理已经清晰了,我们思考这样一个问题:
如何训练神经机器翻译?
首先要准备一个平行语料库和双语的词典。平行语料库是由源语言文本及其平行对应的目标语言文本构成,每个句子在两种语言中成对出现。对语料库进行文本清晰后,将该语料库划分为训练集、测试集和验证集,其中训练集用于训练、测试集用于调试参数、验证集用于验证机器翻译的效果。
首先加载语料库和词汇表,初始化模型的参数。在训练的时候,将源语言进行编码,padding成同样长度的向量。输入编码器中,解码器解码出对应的目标文本。根据解码出来的词典大小的向量,通过计算模型的损失函数,反向传播,采用梯度下降的方法更新模型的参数。梯度下降的方法在期中报告中已经解释过原理,不再赘述。
怎样在训练阶段计算模型的损失(误差)?
我们的目标是最大化公式(3)中的条件概率函数,因此我们定义损失函数:
\[\log \mathbb{P}\left(y_{1}, \ldots, y_{T^{\prime}} \mid x_{1}, \ldots, x_{T}\right)=-\sum_{t^{\prime}=1}^{T^{\prime}} \log \mathbb{P}\left(y_{t^{\prime}} \mid y_{1}, \ldots, y_{t^{\prime}-1}, \boldsymbol{c}\right)\] 训练的目标是最小化损失函数。图解如下:
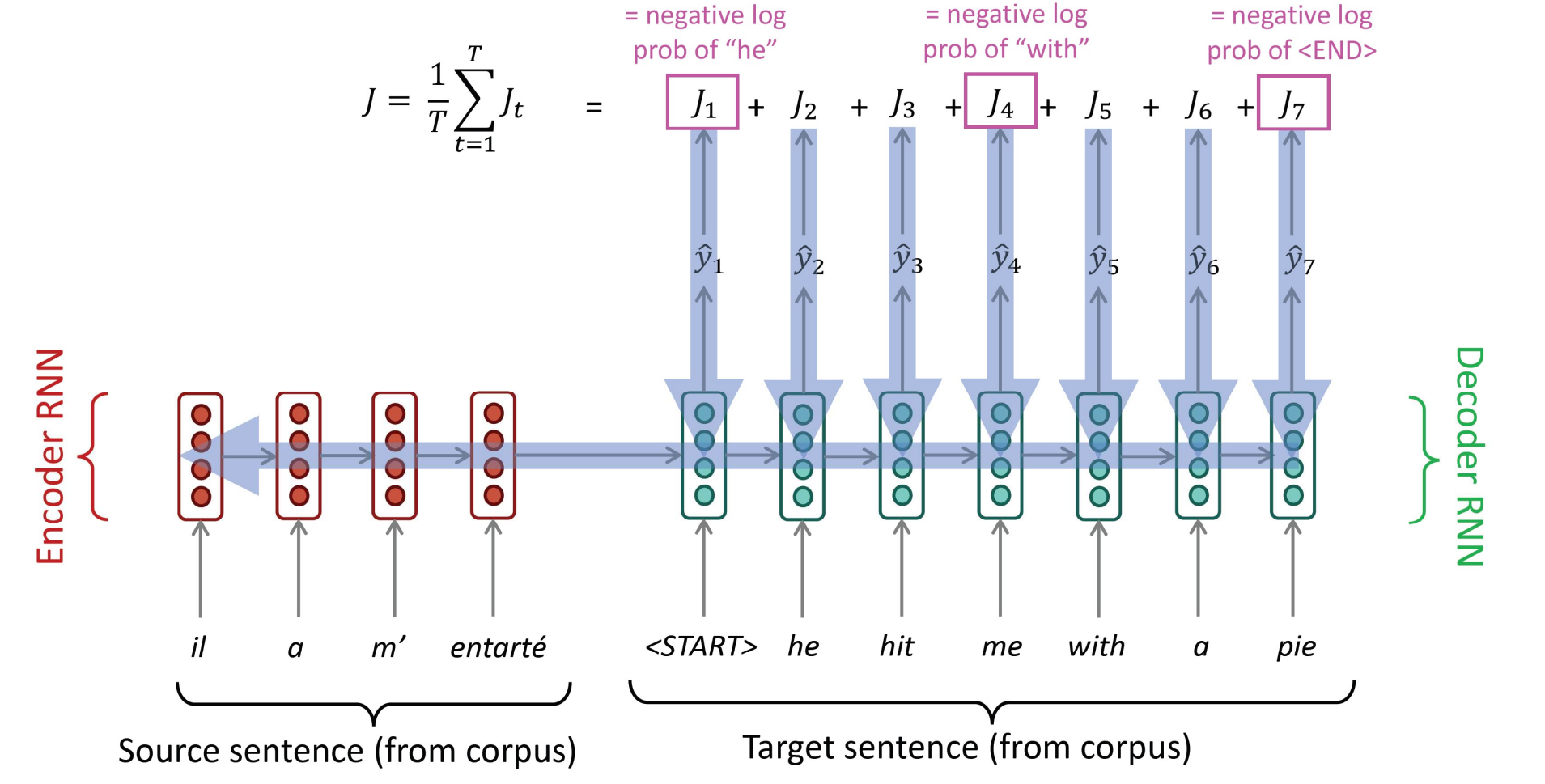
$J_t$是每一步的损失函数,我们的目标是最小化$J$。
在seq2seq中,考虑到,训练和测试是两个不一样的过程。训练的过程我们是知道整个数据集的,而测试的过程中,我们是完全不知道测试集的。这样说有点抽象,我们考虑另外一个问题:观察到RNN模型的过程,在解码器中,当前状态的输入是上一个状态解码后的结果。那么,如果上一个状态解码出错误的信息,那么后面的状态基于错误的状态继续进行训练,那么错误会逐步累积。这种情况会导致,训练过程中,模型的收敛速度会很慢。而且,在这种情况下训练,模型可能会不稳定。
正是因为RNN的这个特点,在解码器中,产生了两种训练模式。
什么是free-running模式和teacher-forcing模式?
free-running模式即为,在解码器中
- 训练过程中:当前状态的输入为上一个状态预测的结果
- 测试过程中:当前状态的输入为上一个状态预测的结果
free-running模式就会产生上述的两个问题:模型的收敛速度会很慢,而且缺少了纠错的能力,使得模型不稳定。
teacher-forcing模式即为,在解码器中
- 训练过程中:当前状态的输入为上一个状态在训练集中正确的结果
- 测试过程中:当前状态的输入为上一个状态预测的结果
teacher-forcing模式解决了free-running模式出现的问题,不仅模型收敛得更快,而且模型更加稳定。但是这又导致了新的问题,由于训练过程中,总是通过正确的结果进行训练,模型不具备纠正错误的能力,也就是说,模型对这种错误不具备鲁棒性。
网络结构进阶
在实际的网络模型中,编码器和解码器部分我们不会采用简单RNN模型,一般会引入注意力机制。
为什么要在神经机器翻译中引入注意力机制(attention)?
普通的RNN模型存在两个问题:
- 把整个输入序列$\mathbf{X}$压缩到一个固定长度的语义编码$c$,忽略了输入序列的长度,当输入句子长度很长,特别是比训练集中最初的句子长度还长时,模型的性能急剧下降。
- 把输入序列$\mathbf{X}$编码成一个固定的长度,对于句子中每个词都赋予相同的权重,这样做是不合理的,比如,在机器翻译里,输入的句子与输出句子之间,往往是输入一个或几个词对应于输出的一个或几个词。因此,对输入的每个词赋予相同权重,这样做没有区分度,往往使模型性能下降。
解决这个问题最好的方法,就是引进attention。使用了attention后,seq2seq模型翻译的时候会再看一遍整个句子的状态,这样就解决了遗忘的问题。attention还会告诉decoder应该关注encoder的哪些状态,这样就能解决第二个缺点。
当我们encoder工作结束后,decoder和attention同时开始工作。不同于seq2seq模型的是,encoder的所有状态都要保留。具体工作原理如下图所示:
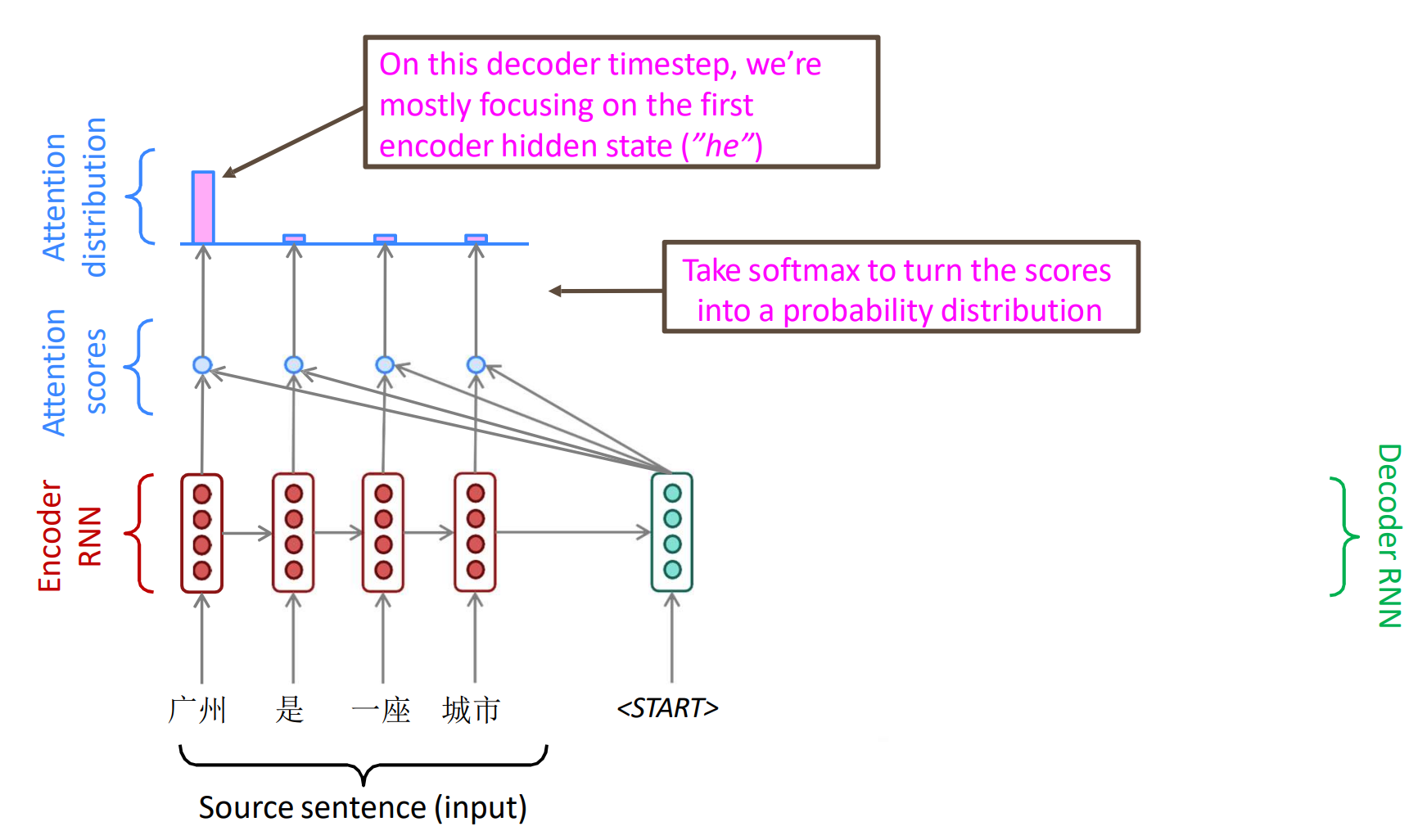
我们将解码器当前的输入$x^{(i)}$与编码器每一步的编码结果$\mathbf{Y}$做点积,得到当前输入对编码器每个状态编码信息的注意力权重(当然计算方法有很多,这里介绍的是点积模型)。因此,对于当前输入,我们得到该输入对于源句子每个词语的注意力权重$\hat{y}^{(i)}$,最后对所有$\mathbf{Y}$做一次softmax操作,即将所有的$\hat{y}^{(i)}$进行归一化,使得$\sum\hat{y}^{(i)}=1$。
\[\operatorname{softmax}(z)=\left[\frac{\exp \left(z_{1}\right)}{\sum_{i=1}^{k} \exp \left(z_{i}\right)}, \frac{\exp \left(z_{2}\right)}{\sum_{i=1}^{k} \exp \left(z_{i}\right)}, \ldots, \frac{\exp \left(z_{k}\right)}{\sum_{i=1}^{k} \exp \left(z_{i}\right)}\right]\] 归一化后,我们就得到该输入的注意力分布情况。注意力分布可以解释为在上下文查询时,第 i 个信息受关注的程度。那么,我们最后的编码输入即为,所有隐向量与注意力分布的加权平均。公式表达如下:
编码器的隐状态 $h_{1}, \ldots, h_{N} \in \mathbb{R}^{h}$。
在时间 $t$,解码器隐状态 $s_{t} \in \mathbb{R}^{h}$ 。
我们得到每一步的注意力分数为 $e^{t}$ :
\[\boldsymbol{e}^{t}=\left[\boldsymbol{s}_{t}^{T} \boldsymbol{h}_{1}, \ldots, \boldsymbol{s}_{t}^{T} \boldsymbol{h}_{N}\right] \in \mathbb{R}^{N}\] 对注意力分数进行softmax操作得到注意力分布每一步的 $\alpha^{t}$,其中$\sum a^t=1$
\[\alpha^{t}=\operatorname{softmax}\left(\boldsymbol{e}^{t}\right) \in \mathbb{R}^{N}\] 我们使用 $\alpha^{t}$ 对编码器隐状态做加权平均,得到 $\boldsymbol{a}_{t}$:
\[\boldsymbol{a}_{t}=\sum_{i=1}^{N} \alpha_{i}^{t} \boldsymbol{h}_{i} \in \mathbb{R}^{h}\] 最后将 $\boldsymbol{a}{t}$ 跟解码器隐状态进行合并, $\left[\boldsymbol{a}{t} ; \boldsymbol{s}_{t}\right] \in \mathbb{R}^{2 h}$ ,后面的操作跟普通RNN模型相同。
评估指标
如何评价机器翻译的结果呢?考虑从人的角度出发:
- 翻译结果在目标语言中,更加清晰、可读和自然;
- 翻译结果更加准确;
- 翻译结果能够包含源语言中更多的表达信息;
BLEU是机器翻译领域最悠久、最常用、最经典的指标。大部分机器翻译论文甚至只使用这一个指标作为系统的评价标准。
解释机器翻译的评价指标BLEU.
用一句通俗的话来解释,如果神经机器翻译的结果和专业的人工翻译的结果越接近,那么翻译的效果就越好。“接近”的程度是通过计算翻译结果中词语和短语对人工翻译结果的命中度来评价的,也就是说BLEU的核心是对翻译结果准确度的度量。
考虑最朴素的一个想法,假如翻译出来的每一个词,如果它在某一个人工翻译结果中出现,那么计数值+1,最后用计数值除以总数,可以得到准确度。但这个方法很显然行不通,假如人工翻译结果为“Guangzhou is a city”,而机器翻译出来”is is is is is”。这个准确度虽然高达100%,但是这个结果显然是不正确的。因此,考虑这个方法的改进版本,如果人工翻译结果中的一个词语已经匹配的机器翻译出来的词语,那么该词语应该被删除。这种方法称为修正的一元语法准确度。即其计数值为:
\[\text{count-in-reference}_{clip}=\text{min}(count,max\_ref\_count)\]根据这种计算方式,上述例子的准确度会降低到$\frac{1}{5}$。
修正的一元语法准确度很容易拓展到修正的n元语法准确度。这样计算的准确度满足了两个方面:一是翻译结果和人工翻译结果使用同样的词语,满足翻译的正确性;二是更长的n元(n-gram)词组匹配满足了翻译的通顺性。
我们用公式来表达具体的计算方法:
$$ \text { precision }{n}=\frac{\sum{C \in \text { corpus } \mathrm{n}-\text { gram } \in C} \text { count-in-reference }{\text {clip }}(\mathrm{n}-\text { gram })}{\sum{C \in \text { corpus } \mathrm{n}-\text { gram } \in C} \text { count }(\mathrm{n}-\text { gram })}
$$ 即如果测试集包含多个句子,则先逐句计算匹配的n-gram数量,将各句的$\text{count-in-reference}{clip}$相加,再除以生成结果的总n-gram的数量。通过设定不同的$n$,可以得到不同的$\text { precision }{n}$ 。对这些$\text { precision }_{n}$,使用几何平均值得到总的BLEU值。
但是这个方法同样存在问题,存在的问题同beam search出现的问题类似,如果产生的句子比较段,那么其BLEU值就会比较高。同样的,我们引入一个惩罚因子,这个惩罚因子使得译文在保证上述条件的情况下, 需要和人工翻译结果的长度匹配。具体计算如下:
\[\text { brevity-penalty }=\min \left(1, \frac{\text { output-length }}{\text { reference-length }}\right)\]$\text { output-length }$是机器翻译结果的长度,$\text { reference-length }$是人工翻译结果的长度。我们最终计算的BLEU结果需要乘上该惩罚因子。最终计算公式为:
\[\mathrm{BLEU}-n=\min \left(1, \frac{\text { output-length }}{\text { reference-length }}\right) \prod_{i=1}^{n} \text { precision }_{i}\]综合评价
神经机器翻译(NMT)有什么优缺点?
与传统的基于统计的机器翻译相比,神经机器翻译有很多优点:
- 更好的性能:翻译结果更加清晰、可读、自然,更好地利用上下文的信息;
- 只有单个神经网络,用于优化端到端模型没:有需要单独优化的子组件;
- 需要更少的人力资源:无特征工作,对所有语言使用相同的方法。
当然,与传统的基于统计的机器翻译相比,神经机器翻译也有一些缺点:
- 神经机器翻译缺乏可解释性,即很难去进行调试;
- 神经机器翻译很难进行控制:无法提供一些简单的特例和一些翻译的指引,也存在一些安全问题。
参考资料
- 《Sequence to Sequence Learning with Neural Networks》
- 《ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS!》
- Luong, et al. Effective Approaches to Attention-based Neural Machine Translation. EMNLP 2015.
- o Bahdanau, et al. Neural Machine Translation by Jointly Learning to Align and Translate. ICLR 2015.