一、实验准备
1.1 熟悉Vivado的仿真功能(行为仿真);
1.2 熟悉课堂上讲的状态机的设计流程(用于实现控制器);
1.3 理解多周期处理器的处理流程,以及控制器的设计流程。
二、实验目的:
2.1 掌握多周期CPU数据通路及其设计方法;
2.2 掌握状态机的设计方法并实现多周期CPU控制器;
2.3 掌握多周期CPU的实现方法,代码实现方法;
2.4 掌握测试多周期CPU的方法。
三、实验设备
3.1 ThinkPad E575 (操作系统:windows10)
3.2 Basys3开发板
3.3 Xilinx Vivado 2015.4
四、实验任务
4.1 实现Datapath,其中主要包含alu和寄存器堆、存储器、PC和controller(其中 Controller包含两部分,分别为main_decoder,alu_decoder),mux2、mux4、signext、sl2、flopr。基于单周期处理器 CPU 的数据通路代码进行改造,在各个需要插入寄存器组IR,MDR,aluA,aluB,aluout(系统框图红色部分), 注意其中IR和PC寄存器都需要进行使能控制。用于控制在当前指令没有结束的时候,禁止下一条指令导入。
4.2 实现指令存储器inst_mem(Single Port Rom),数据存储器data_mem(Single Port Ram),使用BlockMemory Generator IP构造指令,注意考虑 PC 地址位数统一。
4.3 将上述模块依指令执行顺序连接,并编写top文件与mips文件实现模块化。
4.4 实验给出仿真程序,最终以仿真输出结果判断是否成功实现要求指令。
五、实验原理
5.1 多周期CPU基本原理
多周期 CPU 指的是将整个 CPU 的执行过程分成几个阶段,每个阶段用一个时钟去完成,然后开始下一条指令的执行,而每种指令执行时所用的时钟数不尽相同,这就是所谓的多周期CPU。CPU在处理指令时,一般需要经过以下几个阶段:
(1) 取指令(IF):根据程序计数器pc中的指令地址,从存储器中取出一条指令,同时,pc根据指令字长度自动递增产生下一条指令所需要的指令地址,但遇到“地址转移”指令时,则控制器把“转移地址”送入pc,当然得到的“地址”需要做些变换才送入 pc。
(2) 指令译码(ID):对取指令操作中得到的指令进行分析并译码,确定这条指令需要完成的操作,从而产生相应的操作控制信号,用于驱动执行状态中的各种操作。
(3) 指令执行(EXE):根据指令译码得到的操作控制信号,具体地执行指令动作,然后转移到结果写回状态。
(4) 存储器访问(MEM):所有需要访问存储器的操作都将在这个步骤中执行,该步骤给出存储器的数据地址,把数据写入到存储器中数据地址所指定的存储单元或者从存储器中得到数据地址单元中的数据。
(5) 结果写回(WB):指令执行的结果或者访问存储器中得到的数据写回相应的目的寄存器中。
5.2 多周期CPU总体框架
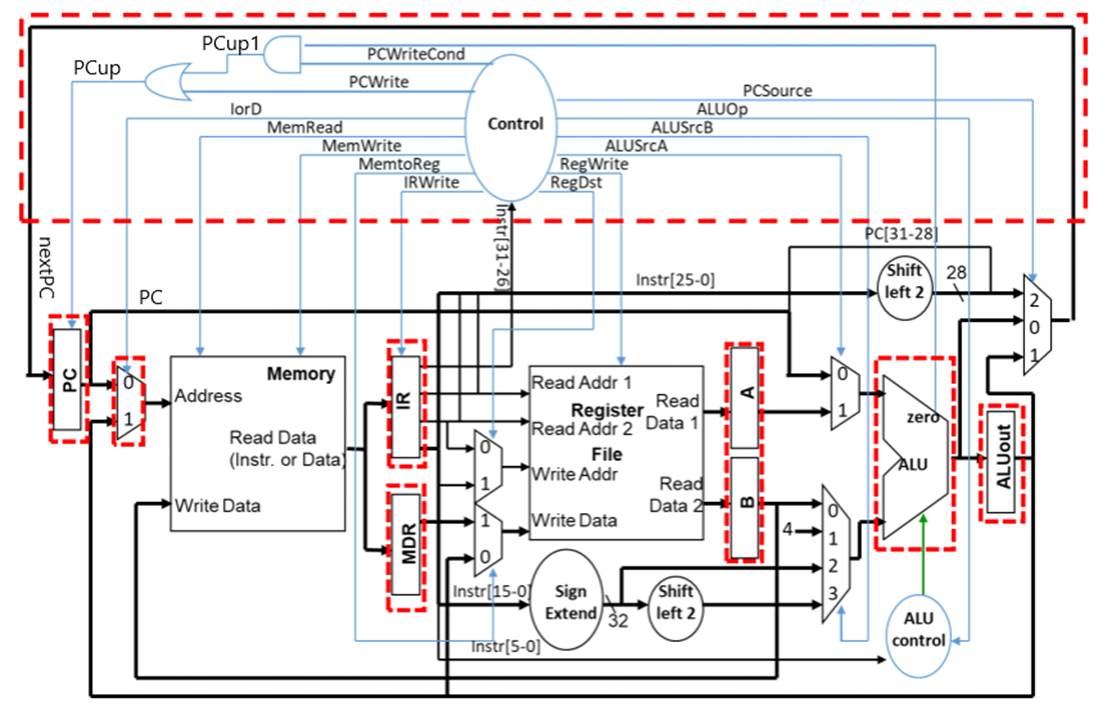
图上增加IR指令寄存器,目的是使指令代码保持稳定,pc写使能控制信号,是确保 pc 适时修改,原因都是和多周期工作的 CPU 有关。A、B、ALUout四个寄存器不需要写使能信号,其作用是切分数据通路,将大组合逻辑切分为若干个小组合逻辑,大延迟变为多个分段小延迟。
5.3 控制器处理
多周期 CPU 是把5个不同的执行阶段放到5个单独的 clk 里面,不同指令在不同的周期(stage)也有不同的输出控制信号。具体信号的作用如下:
| 控制信号名 | 作用 |
|---|---|
| PCWrite | PCWrite=0,PC 不更改;PCWrite=1, PC更改; |
| ALUSrcA | ALUSrcA=0,ALU的输入来自 PC; ALUSrcA=1,ALU的输入来自寄存器堆; |
| ALUSrcB[1:0] | ALUSrcB=00,ALU的输入来自寄存器堆; ALUSrcB=01,ALU的输入等于4;用于做PC+4; ALUSrcB=10,ALU的输入来自与立即数; ALUSrcB=11,ALU的输入来自与立即数迁移,主要用于beq指令; |
| MemtoReg | MemtoReg=0,来自ALU的输出写入registerfile,例如R-type指令; MemtoReg=1,来自Memory出写入registerfile, 例如lw指令; |
| RegWrite | Registerfile写入控制信号,0为读,1为写入; |
| RegDst | RegDst=0,寄存器写入地址是rd; RegDst=1,寄存器写入地址是rt; |
| MemWrite | M读写指令和存储存储器; |
| IRWrite | IRWrite=0,IR(指令寄存器)不更改; IRWrite=1,IR寄存器写使能。向指令存储器发出读指令代码后,这个信号也接着发出,在时钟上升沿,IR 接收从指令存储器送来的指令代码。与每条指令都相关。 |
| ExtOp | ExtOp=0,无符号扩展; ExtOp=1,有符号扩展。 |
| PCSrc[1:0] | 00:pc<-pc+4; (相关指令:add、addiu、sub、and、andi、ori、xori、slt、slti、sll、sw、lw、beq、bne、bltz) 01:pc<-pc+4+(sign-extend)immediate×4; (相关指令:beq、bne、bltz) 10:pc<-{pc[31:28],addr[27:2],2’b00}; (相关指令:j、jal) |
| ALUOp[1:0] | ALU的8种运算功能选择(000-111)。 |
| PCWriteCond | beq信号的PC更新旁路信号。 |
| lorD | 选择选指令存储器还是数据存储器。 |
| MemRead | 指令存储区或数据存储器的读使能信号。 |
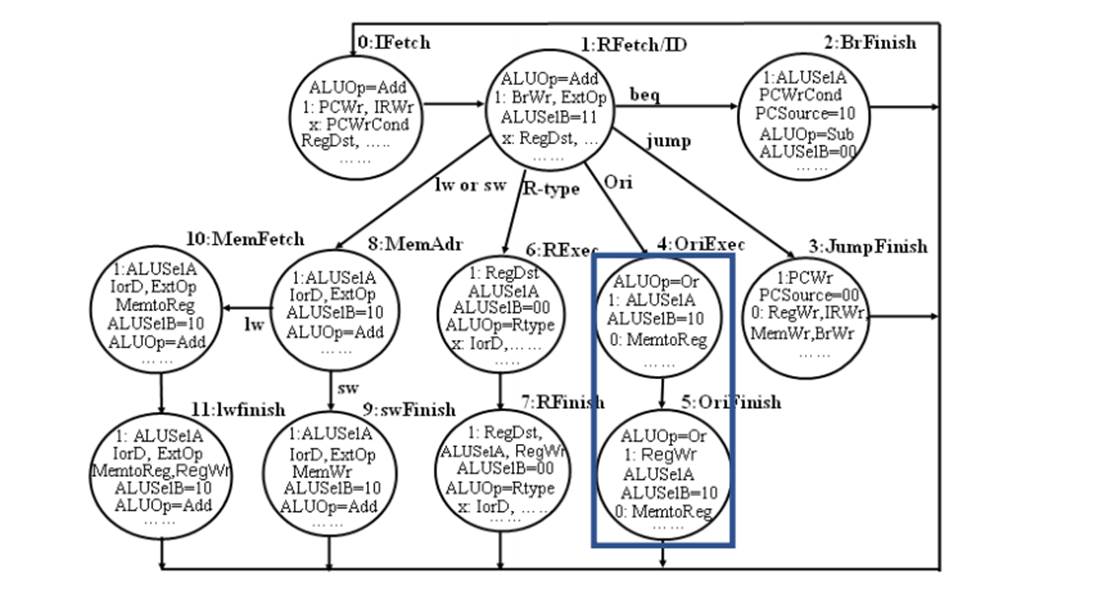
各信号在状态机中的取值如下表:
| 控制信号名 | IFetch | RFetch | BrFinish | JumpFinish | OriExec | OriFinish | RExec | RFinish | MemAdr | swFinish | MemFetch | lwFinish |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PCWrite | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ALUSrcA | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| ALUSrcB[1:0] | 01 | 11 | 00 | 01 | 10 | 10 | 00 | 00 | 10 | 10 | 10 | 10 |
| MemtoReg | x | x | x | x | 0 | 0 | 0 | 0 | x | x | 1 | 1 |
| RegWrite | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| RegDst | x | x | x | x | 0 | 0 | 1 | 1 | x | x | 0 | 0 |
| MemWrite | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| IRWrite | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ExtOp | 0 | 1 | x | 0 | 1 | 0 | x | x | 1 | 1 | 1 | 1 |
| PCSrc[1:0] | 00 | xx | 01 | 10 | xx | xx | xx | xx | xx | xx | xx | xx |
| ALUOp[1:0] | 00 | 00 | 01 | xx | 00 | xx | 10 | xx | 00 | xx | 10 | 10 |
| PCWriteCond | x | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| lorD | 0 | x | x | x | x | x | x | x | 1 | 1 | 1 | 1 |
| MemRead | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
不同的指令有不同的周期数,不同指令在不同的周期(stage)也有不同的输出控制信号。多周期的控制器需要依赖于状态机设计实现。具体的状态机设计如下:
六、实验步骤
实验模块结构如下:
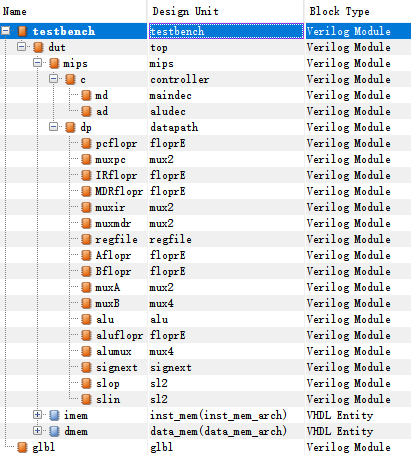
6.1 根据信号表与状态机设计表,实现maindec(译码器)模块,并将maindec(主译码器)和aludec(ALU译码器)连接,实现controller(控制器);
6.2 根据多周期CPU框架图,设计各个模块,包括floprE(D触发器)、mux2(二路选择器)、mux4(四路选择器)、regfile(寄存器堆)、signext(符号扩展)、sl2(左移);
6.3 连接各个模块,完成datapath(数据通路);
6.4 加载ip核中的Single Port ROM作为指令存储器与Single Port RAM作为数据存储器;
6.5 连接datapath与存储器,实现模块化mips文件,完成顶端文件top的设计。
七、实验代码
7.1 maindec(译码器)模块
`timescale 1ns / 1ps
module maindec(
input wire clk,rst,
input wire[5:0] op,
output wire PCWrite,ALUSrcA,
output wire [1:0] ALUSrcB,
output wire MemtoReg,RegWrite,RegDst,MemWrite,MemRead,
output wire IRWrite,ExtOp,
output wire [1:0] PCSrc,
output wire [1:0] ALUOp,
output wire PCWriteCond,lorD
);
localparam IFetch=0,RFetch=1,BrFinish=2,JumpFinish=3,OriExec=4,OriFinish=5;
localparam RExec=6,RFinish=7,MemAdr=8,swFinish=9,MemFetch=10,lwFinish=11;
reg [16:0] outcontrol;
reg [3:0] state,nextstate;
assign {PCWrite,ALUSrcA,ALUSrcB,MemtoReg,RegWrite,RegDst,MemWrite,IRWrite,
ExtOp,PCSrc,ALUOp,PCWriteCond,lorD,MemRead}=outcontrol;
always@ (negedge clk or posedge rst)
begin
if (rst==1)
state <= IFetch;
else
state <= nextstate;
end
always@ (*)
begin
nextstate=state;
case (state)
IFetch:
begin
nextstate=RFetch;
outcontrol=17'b1001x0x0100000x01;
end
RFetch:
begin
outcontrol=17'b0011x0x001xx000x0;
if (op==6'b000100)
begin
nextstate=BrFinish;
end
if (op==6'b000010)
begin
nextstate=JumpFinish;
end
if (op==6'b001000)
begin
nextstate=OriExec;
end
if (op==6'b000000)
begin
nextstate=RExec;
end
if (op==6'b100011 || op==6'b101011)
begin
nextstate=MemAdr;
end
end
BrFinish:
begin
nextstate=IFetch;
outcontrol=17'b0100x0x00x01011x0;
end
JumpFinish:
begin
nextstate=IFetch;
outcontrol=17'b1101x0x00010xx0x0;
end
OriExec:
begin
nextstate=OriFinish;
outcontrol=17'b0110000001xx000x0;
end
OriFinish:
begin
nextstate=IFetch;
outcontrol=17'b011001000xxxxx0x0;
end
RExec:
begin
nextstate=RFinish;
outcontrol=17'b010000100xxx100x0;
end
RFinish:
begin
nextstate=IFetch;
outcontrol=17'b010001100xxxxx0x0;
end
MemAdr:
begin
outcontrol=17'b0110x0x001xx000x0;
if (op==6'b101011)
begin
nextstate=swFinish;
end
if (op==6'b100011)
begin
nextstate=MemFetch;
end
end
swFinish:
begin
nextstate=IFetch;
outcontrol=17'b0110x1x101xxxx011;
end
MemFetch:
begin
nextstate=lwFinish;
outcontrol=17'b0110100001xx10011;
end
lwFinish:
begin
nextstate=IFetch;
outcontrol=17'b0110110001xx10010;
end
endcase
end
endmodule
7.2 datapath等其他文件见附录
八、实验结果
coe文件:
memory_initialization_radix = 16;
memory_initialization_vector =
20020005,
2003000c,
2067fff7,
00e22025,
00642824,
00a42820,
10a7000a,
0064202a,
10800001,
20050000,
00e2202a,
00853820,
00e23822,
ac670044,
8c020050,
08000011,
20020001,
ac020054
执行指令总览:

8.1 指令1:20020005
该机器码为addi $2,$0,5指令,为R-type指令中的立即数加法。
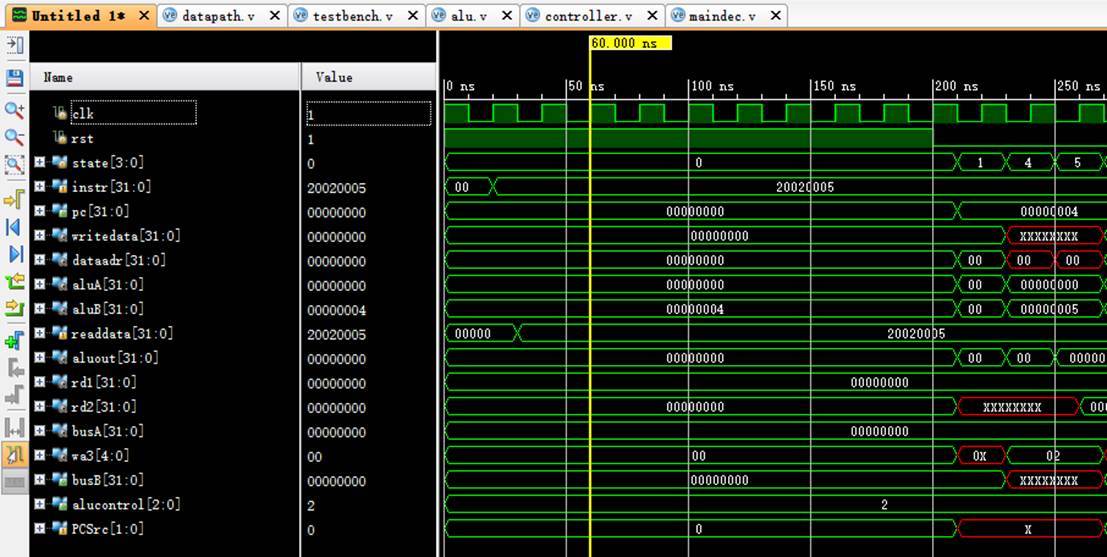
阶段0:
instr正确读取指令20020005;
阶段1:
pc从0变化到4;
rd1读取$0中的数值0;
阶段4:
rd1传入aluA中进行计算;
aluB获取立即数5;
aluout计算出结果:aluA与aluB的和5;
阶段5:
成功将计算结果存入wa3即$2寄存器中。
8.2 指令2:2003000c
该机器码为addi $3,$0,12指令,为R-type指令中的立即数加法。
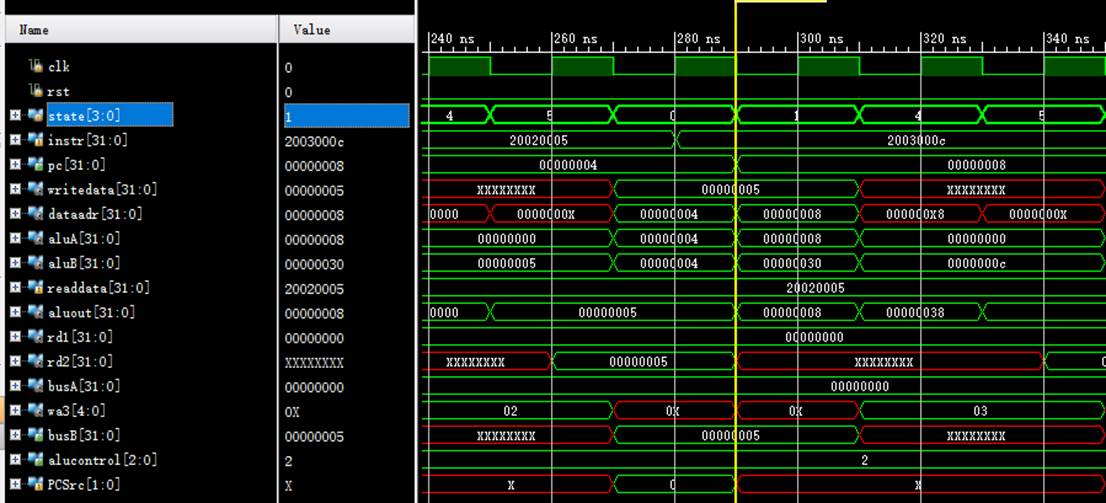
阶段0:
instr正确读取指令2003000c;
阶段1:
pc从4变化到8;
rd1读取$0中的数值0;
阶段4:
rd1传入aluA中进行计算;
aluB获取立即数c;
aluout计算出结果:aluA与aluB的和c;
阶段5:
成功将计算结果存入wa3即$3寄存器中。
8.3 指令3:2067fff7
该机器码为addi $7,$3,-9指令,为R-type指令中的立即数加法。
阶段0:
instr正确读取指令2067fff7;
阶段1:
pc从8变化到c;
rd1读取$3中的数值c;
阶段4:
rd1传入aluA中进行计算;
aluB获取立即数-12(fffffff7);
aluout计算出结果:aluA与aluB的和3;
阶段5:
成功将计算结果存入wa3即$7寄存器中。
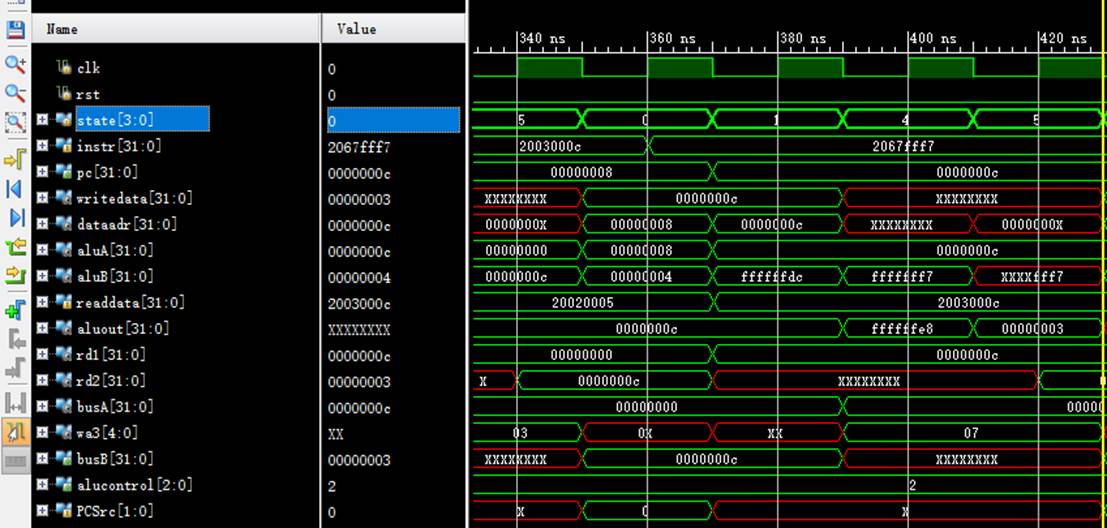
8.4 指令4:00e22025
该机器码为or $4,$7,$2指令,为R-type指令中的或运算。

阶段0:
instr正确读取指令00e22025;
阶段1:
pc从c变化到10;
rd1读取$7中的数值3;
rd2读取$2中的数值5;
阶段6:
rd1传入aluA中进行计算;
rd2传入aluB中进行计算;
aluout计算出结果:3 or 5=7;
阶段7:
成功将计算结果存入wa3即$4寄存器中。
8.5 指令5:00642824
该机器码为and $5,$3,$4指令,为R-type指令中的与运算。
阶段0:
instr正确读取指令00642824;
阶段1:
pc从10变化到14;
rd1读取$3中的数值c;
rd2读取$4中的数值7;
阶段6:
rd1传入aluA中进行计算;
rd2传入aluB中进行计算;
aluout计算出结果:c and 7=4;
阶段7:
成功将计算结果存入wa3即$5寄存器中。
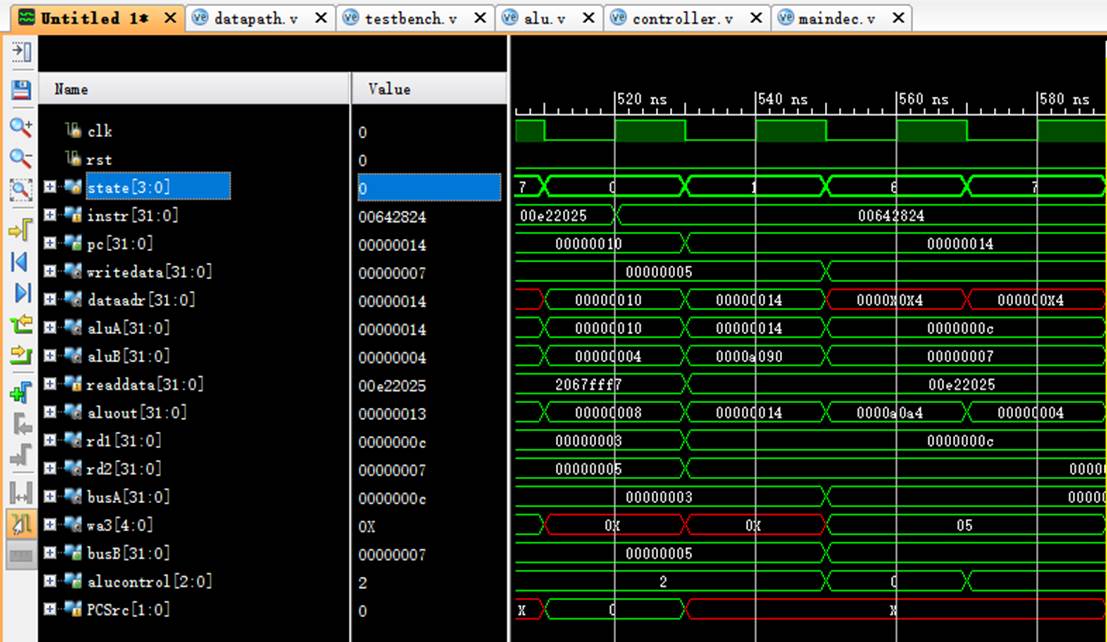
8.6 指令6:00a42820
该机器码为add $5,$5,$4指令,为R-type指令中的加法运算。
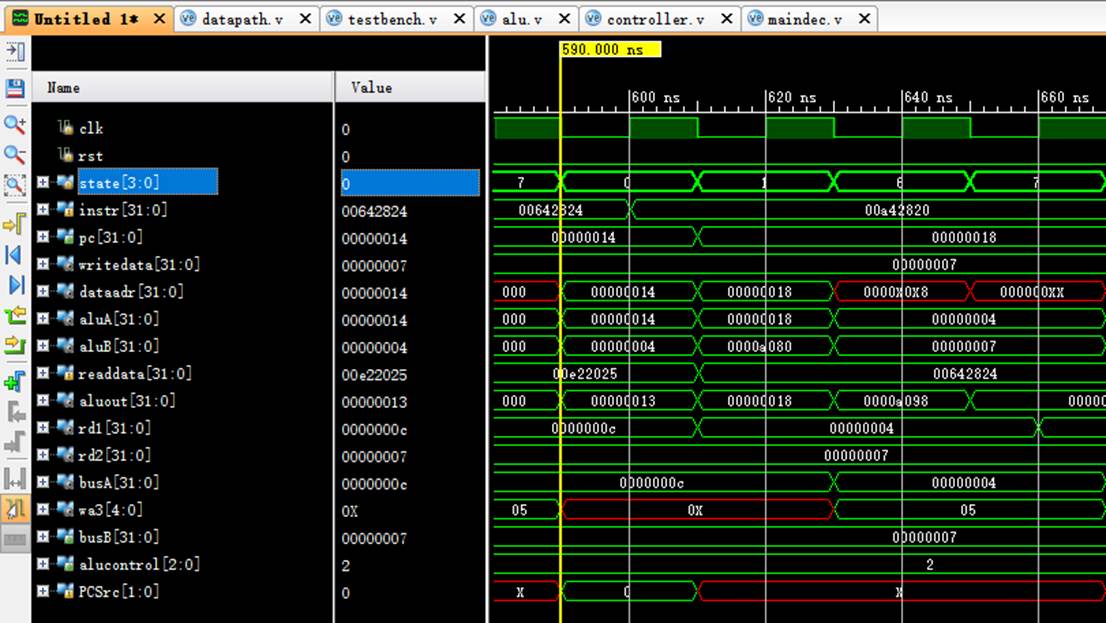
阶段0:
instr正确读取指令00a42820;
阶段1:
pc从14变化到18;
rd1读取$5中的数值4;
rd2读取$4中的数值7;
阶段6:
rd1传入aluA中进行计算;
rd2传入aluB中进行计算;
aluout计算出结果:4+7=b;
阶段7:
成功将计算结果存入wa3即$5寄存器中。
8.7 指令7:10a7000a
该机器码为beq $5,$7,end指令,为branch指令。
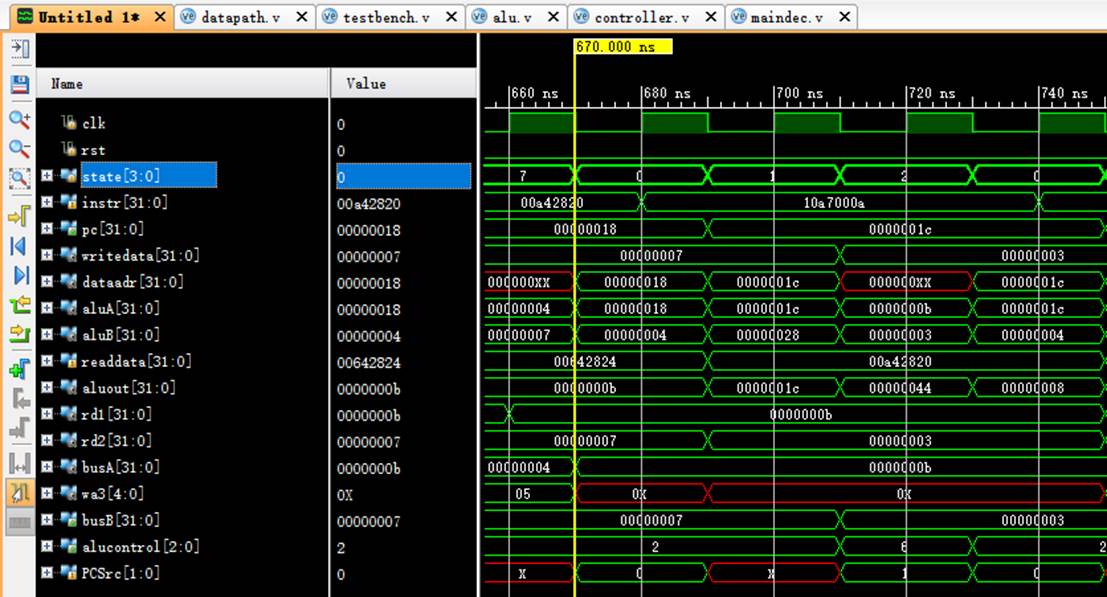
阶段0:
instr正确读取指令10a7000a;
阶段1:
pc从18变化到1c;
rd1读取$5中的数值b;
rd2读取$7中的数值3;
阶段2:
rd1传入aluA中进行比较;
rd2传入aluB中进行比较;
b不等于3,pc未变化。
8.8 指令8:0064202a
该机器码为slt $4,$3,$4指令,为R-type指令中的比较指令。
阶段0:
instr正确读取指令0064202a;
阶段1:
pc从1c变化到20;
rd1读取$3中的数值c;
rd2读取$4中的数值7;
阶段6:
rd1传入aluA中进行计算;
rd2传入aluB中进行计算;
aluout计算出结果:c<7=0;
阶段7:
成功将计算结果存入wa3即$4寄存器中。
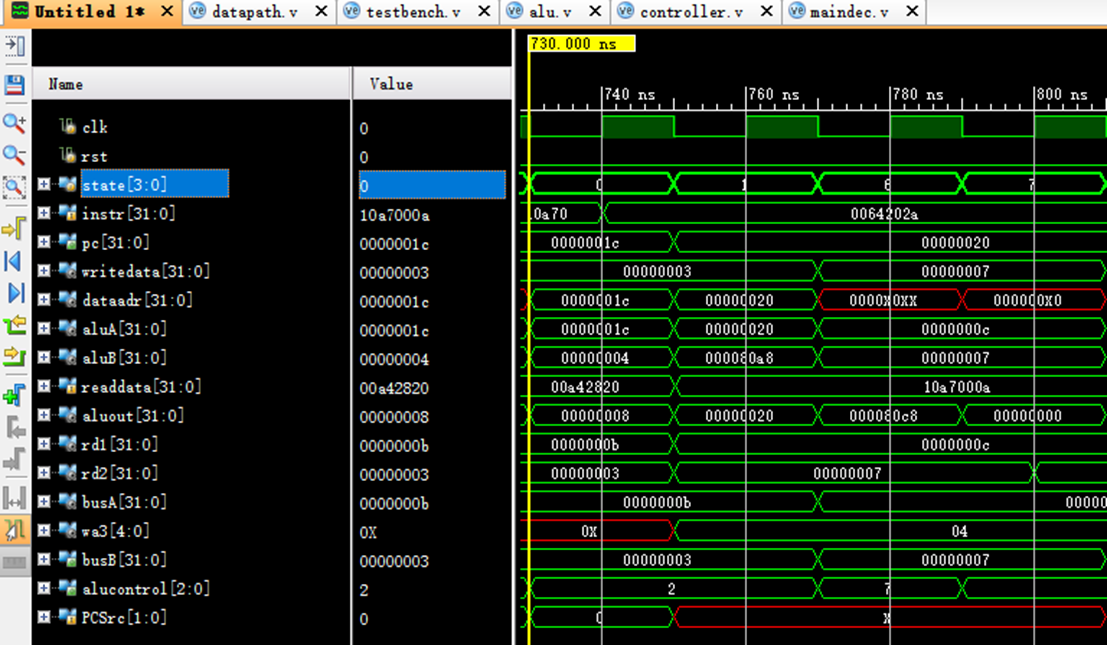
8.9 指令9:10800001
该机器码为beq $4,$0,around指令,为branch指令。
阶段0:
instr正确读取指令10800001;
阶段1:
pc从20变化到24;
rd1读取$4中的数值0;
rd2读取$0中的数值3;
阶段2:
rd1传入aluA中进行比较;
rd2传入aluB中进行比较;
0=0,aluout得到around的位置next_pc,pc更新。
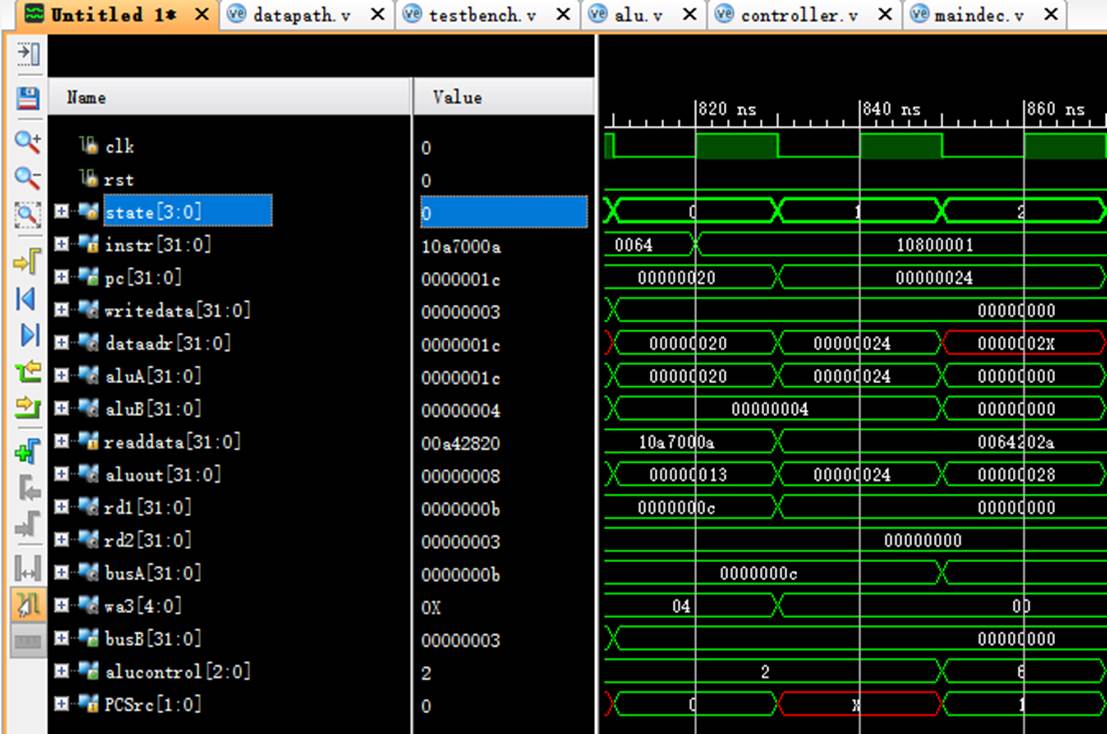
8.10 指令10:20050000
被跳过,未执行
8.11 指令11:00e2202a
该机器码为slt $4,$7,$2指令,为R-type指令中的比较指令。
阶段0:
instr正确读取指令00e2202a;
阶段1:
pc从28变化到2c;
rd1读取$7中的数值3;
rd2读取$2中的数值5;
阶段6:
rd1传入aluA中进行计算;
rd2传入aluB中进行计算;
aluout计算出结果:3<5=1;
阶段7:
成功将计算结果存入wa3即$4寄存器中。
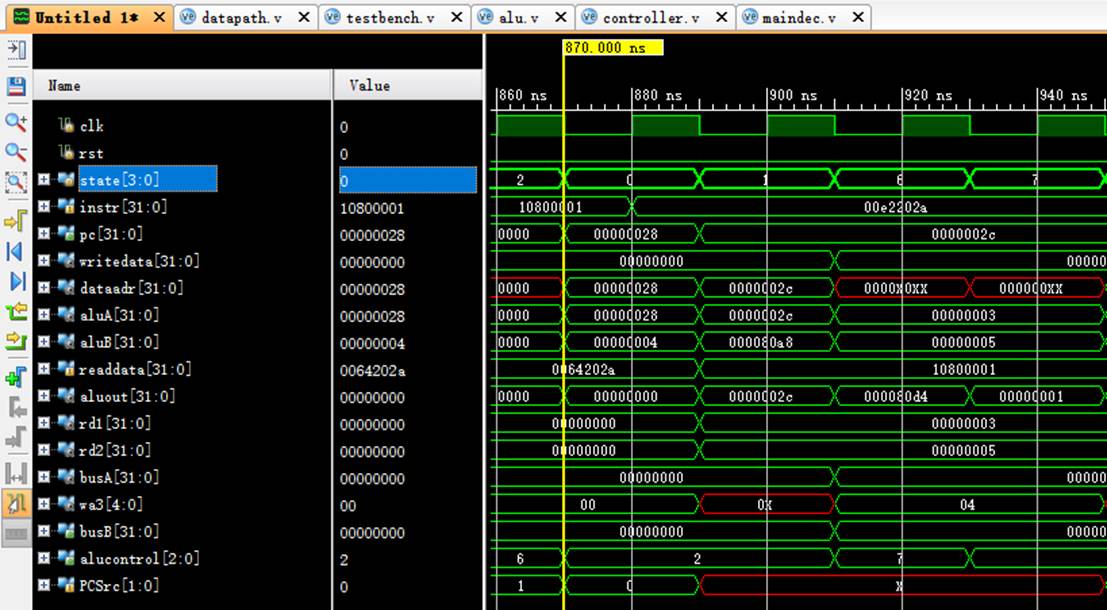
8.12 指令12:00853820
该机器码为add $7,$4,$5指令,为R-type指令中的加法运算。
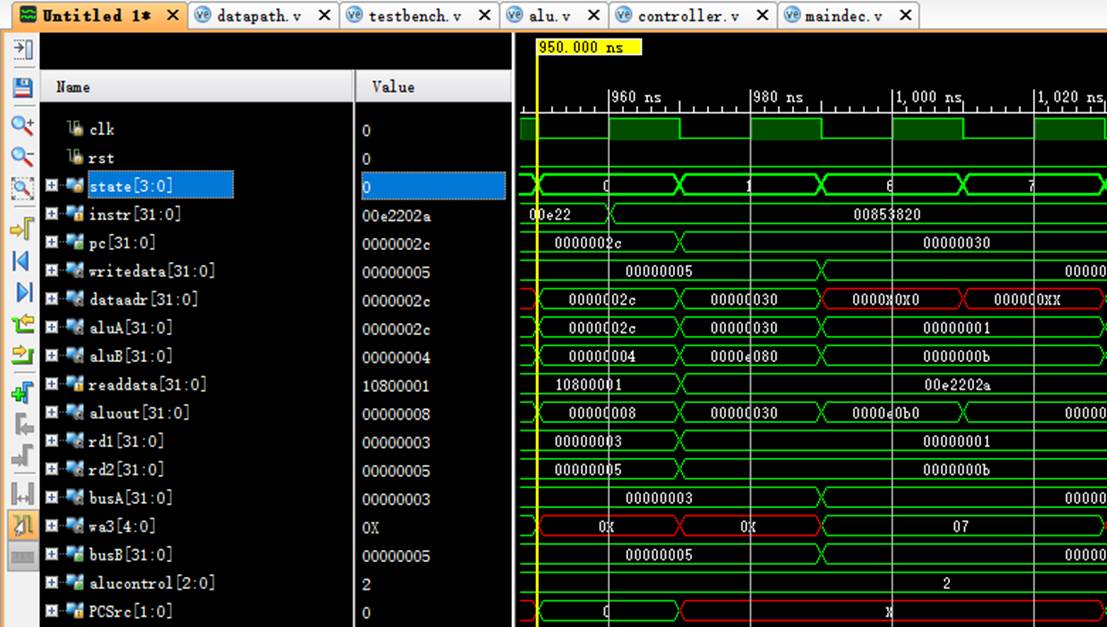
阶段0:
instr正确读取指令00853820;
阶段1:
pc从2c变化到30;
rd1读取$4中的数值1;
rd2读取$5中的数值b;
阶段6:
rd1传入aluA中进行计算;
rd2传入aluB中进行计算;
aluout计算出结果:1+b=c;
阶段7:
成功将计算结果存入wa3即$7寄存器中。
8.13 指令13:00e23822
该机器码为sub $7,$7,$2指令,为R-type指令中的减法运算。
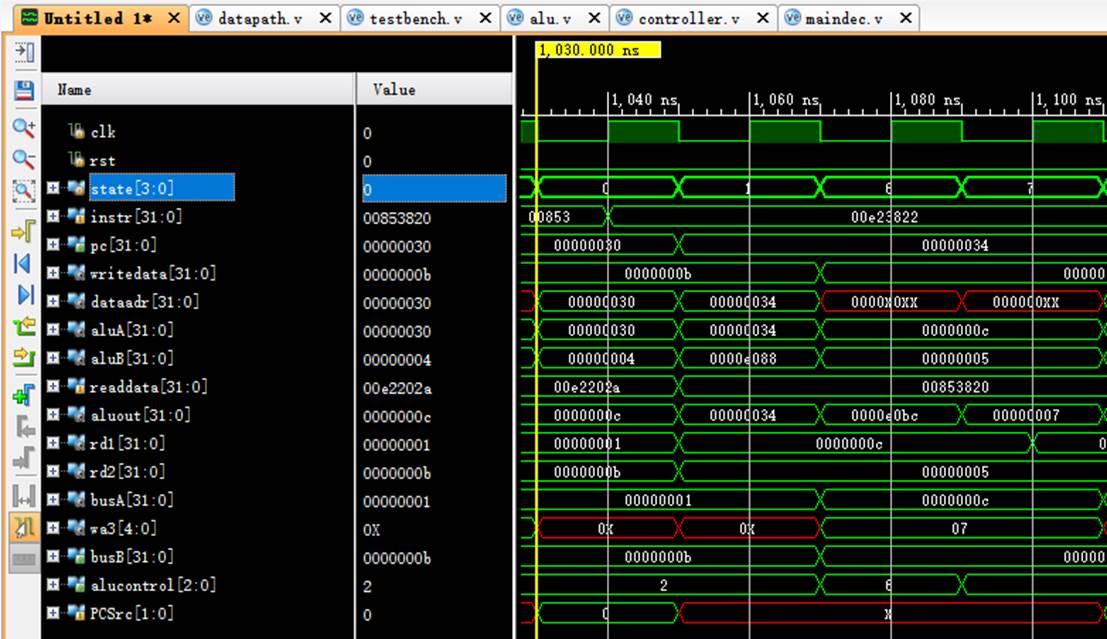
阶段0:
instr正确读取指令00e23822;
阶段1:
pc从30变化到34;
rd1读取$7中的数值c;
rd2读取$2中的数值5;
阶段6:
rd1传入aluA中进行计算;
rd2传入aluB中进行计算;
aluout计算出结果:c-5=7;
阶段7:
成功将计算结果存入wa3即$7寄存器中。
8.14 指令14:ac670044
该机器码为sw $7,68($3)指令,为sw指令。
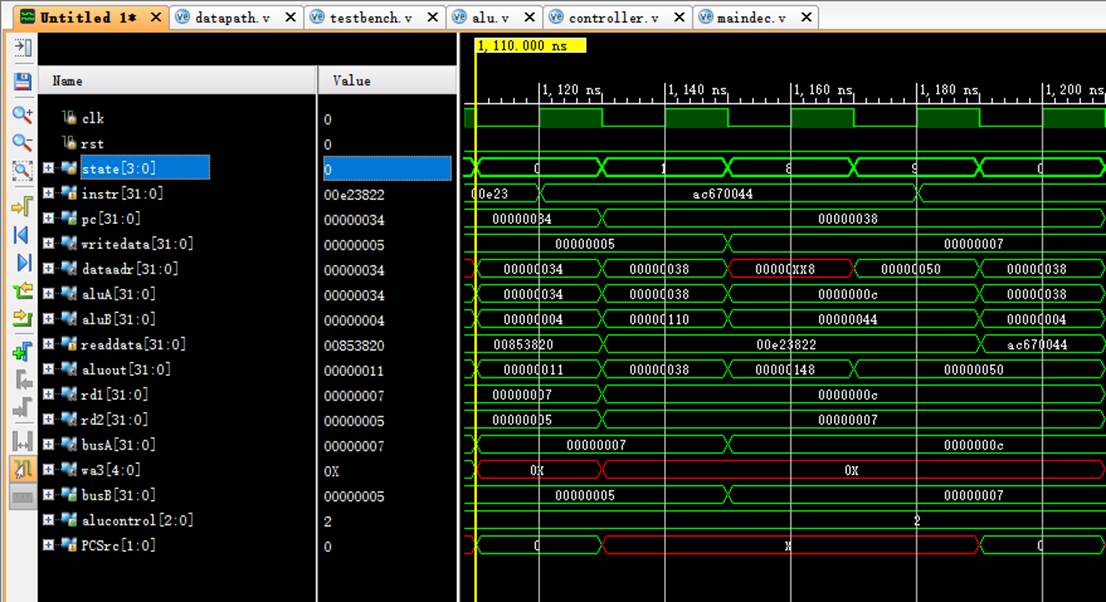
阶段0:
instr正确读取指令ac670044;
阶段1:
pc从34变化到38;
rd1读取$3中的数值c;
阶段8:
rd1传入aluA中进行计算;
aluB中读取立即数68(16进制下是44);
aluout计算出sw的地址68+12=[80](16进制下是50);
阶段9:
dataadr=50,存储进数据存储器。
8.15 指令15:8c020050
该机器码为lw $2,80($0)指令,为lw指令。
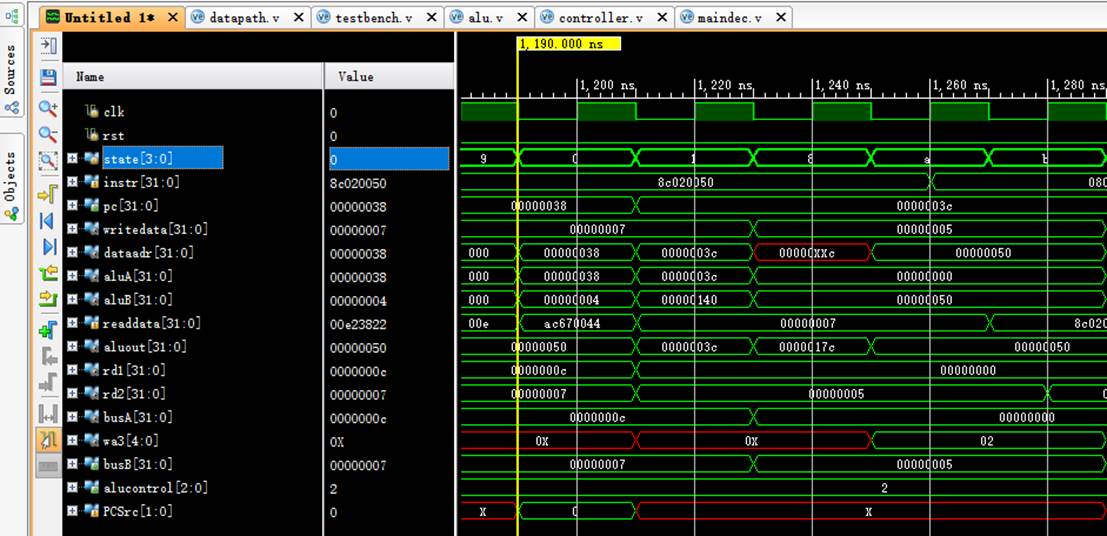
阶段0:
instr正确读取指令8c020050;
阶段1:
pc从38变化到3c;
rd1读取$0中的数值0;
阶段8:
rd1传入aluA中进行计算;
aluB中读取立即数80(16进制下是50);
aluout计算出lw的地址80+0=[80](16进制下是50);
阶段10:
dataadr=50,定位数据存储器中数据的位置。
阶段11:
readdata读取到储存在[80]位置中的7,验证得sw与lw指令正常运作。
8.16 指令16:08000011
该机器码为j end指令,为跳转指令。
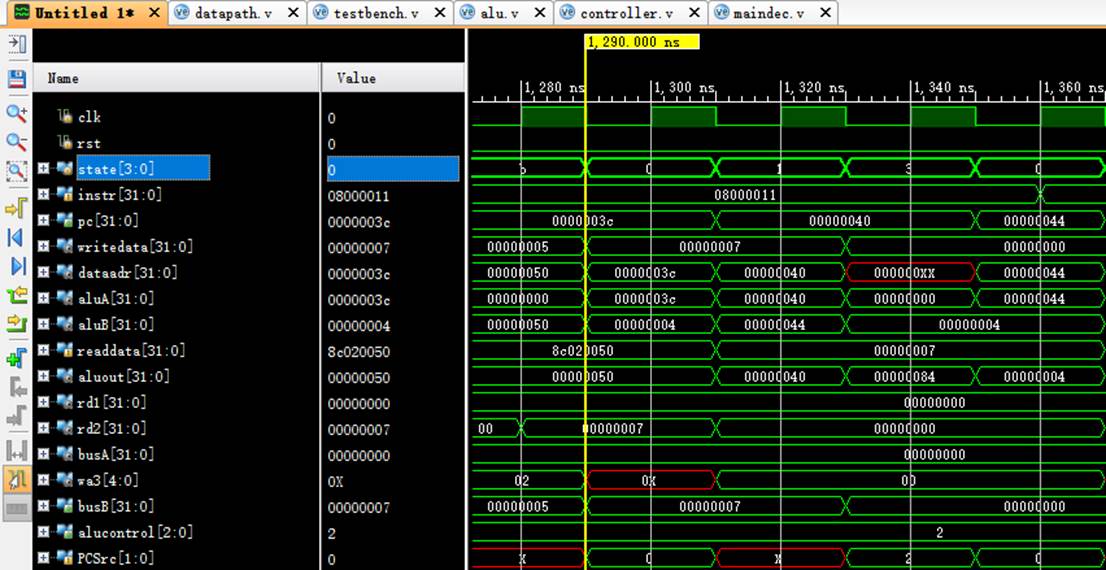
阶段0:
instr正确读取指令08000011;
阶段1:
pc从3c正确跳转到40;
阶段3:
nextPC从指令中提取出end指令;
pc从40跳转到44。
8.17 指令17:20020001
被跳过,不执行
8.18 指令18:ac020054
该机器码为sw $2,84($0)指令,为sw指令。
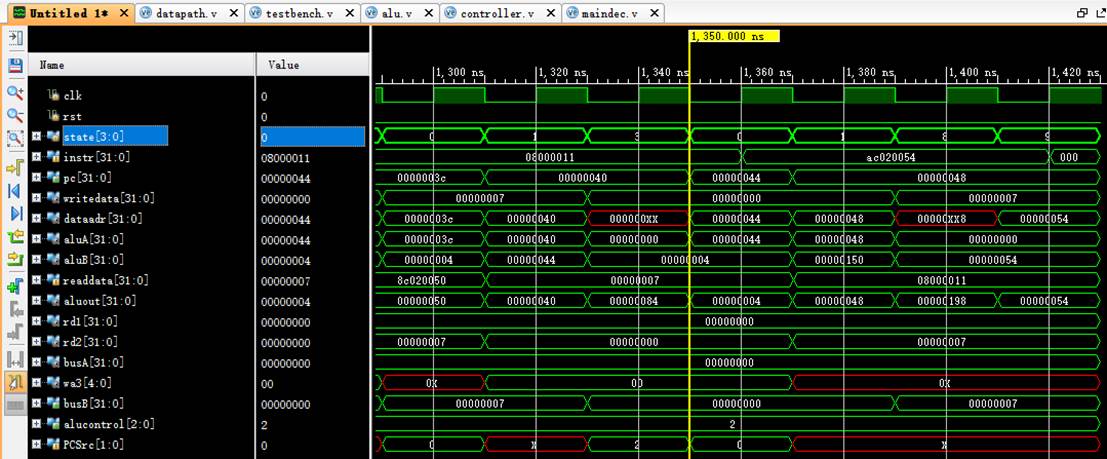
阶段0:
instr正确读取指令ac020054;
阶段1:
pc为44;
rd1读取$0中的数值0;
阶段8:
rd1传入aluA中进行计算;
aluB中读取立即数84(16进制下是54);
aluout计算出sw的地址0+84=[84](16进制下是54);
阶段9:
dataadr=54,存储进数据存储器。
8.19 指令完成
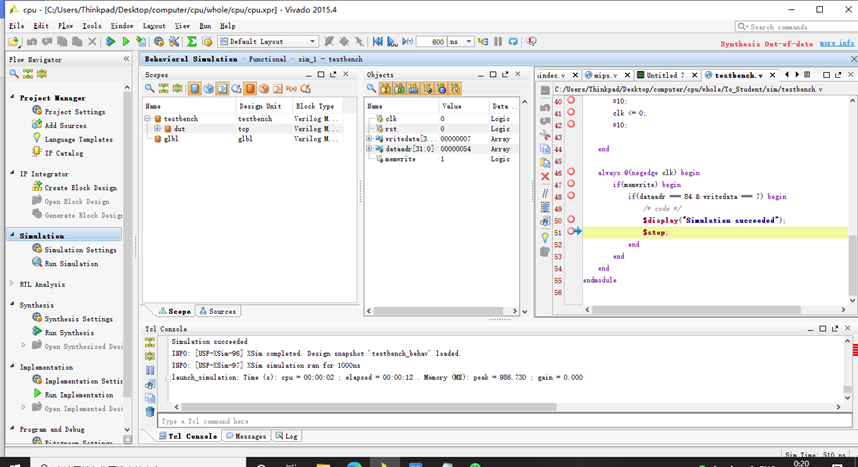
展示“simulation succeeded”;
仿真顺利结束。