NIPS23 Combinatorial Optimization with Policy Adaptation using Latent Space Search
基于潜在空间搜索的策略自适应组合优化
来自InstaDeep
代码和数据集: https://github.com/instadeepai/compass
(我没读代码,理解的不是很透彻,没有附录感觉讲的也不是很清楚,需要很多统计机器学习和进化算法的前置知识,前置知识有点匮乏)
摘要
组合优化支撑着许多现实世界的应用,然而,设计高性能的算法来解决这些复杂的、典型的np困难的问题仍然是一个重大的研究挑战。强化学习(RL)为在广泛的问题领域中设计启发式提供了一个通用的框架。然而,尽管取得了显著进展,RL尚未取代工业解决方案作为首选解决方案。当前的方法强调构建解决方案的预训练启发式,但通常依赖于具有有限方差的搜索过程,例如从单个策略中随机抽样大量解决方案,或者在单个问题实例上使用计算代价高昂的策略微调。基于在预训练期间应该预期推理时间的性能搜索的直觉,作者提出了COMPASS,这是一种新的强化学习方法,它将基于连续潜在空间的多种和专门策略的分布参数化。作者通过三个典型问题——TSP、CVRP、JSP来评估COMPASS,并证明作者的搜索策略(i)在11个标准基准测试任务中的9个中优于最先进的方法,(ii)泛化得更好,在一组18个程序转换实例分布上超过所有其他方法。
介绍
神经方法一次构造很难构造出很好的解,需要添加额外的搜索辅助。迭代式的方法需要一定的搜索时间和实际限制。这两种方法都没有以一种能够实现快速有效的推理时间搜索的方式对策略进行预训练:而当前的方法通常完全将两者解耦。当测试实例不在用于训练策略的分布(OOD)中时,缺乏有效的搜索策略甚至更加有害,因为这可能导致学习到的策略和导致最优解决方案的策略之间存在很大差异。
在这项工作中,作者的目标是克服目前在强化学习中使用的搜索策略在应用于CO问题时的局限性。作者的方法是学习一个可以在推理时探索的多种策略的潜在空间,以便为给定实例找到最佳表现的策略。这更新了当前的范例,允许在推理时从策略空间进行采样,而不是不断地随机采样相同的策略(或一组策略)。本文引入了COMPASS -组合优化方法,并利用潜在空间搜索进行策略自适应。COMPASS通过使用单一的条件策略并从连续的潜在空间中采样条件,有效地创建了无限组不同的求解器。训练过程鼓励潜在空间的子区域专门针对实例的子分布,并且在推理时使用这种多样性来解决新遇到的实例。
贡献:
(1)引入COMPASS,利用多样化和专门化策略的潜在空间,有效解决CO问题。
(ii)表明COMPASS允许在不重新训练或牺牲zero-shot性能的情况下有效地适应特定于实例的策略。
(iii)在实验中,作者的方法被发现在所有作者考虑的问题类型中代表了基于rl的CO方法的最新技术,在29个任务中的27个任务中实现了卓越的性能。
(iv)发布了方法和它的主要竞争对手的快速和高性能的实现,用JAX编写。作者还提供了所有的测试集,包括作者的程序转换问题实例,以便在未来的工作中更容易进行比较。(JAX是deepmind的一个数值计算库,深度学习是其中一个部分,他可以加速学习,这个实验室针对强化学习对JAX改进过)
相关工作
- CO的构造方法
- 推理时候的改进方案:POMO及其改进、EAS、MDAM、Poppy、CVAE-Opt。
方法
预备知识
马尔科夫决策过程
COMPASS
没有一个策略能够在一次推理中可靠地解决NP-hard CO问题的所有实例。解决这个问题的两种主要方法是包含推理时间搜索和部署多种策略集,以增加部署接近最优策略的机会。这项工作旨在通过训练一组无限大的多样化和专业化策略来统一和扩展这些方法,这些策略随后可以在推理时进行搜索。
为了实现这一目标,作者提出一组策略参数不仅取决于当前的观测值,还取决于从连续潜在空间中提取的样本。然后,训练目标鼓励策略的潜在空间多样化(泛化)和专门化(这些行为针对来自训练分布的不同类型的问题实例进行优化)。然后可以在推理过程中有效地搜索这个潜在空间,为给定的问题实例找到最高效的策略。
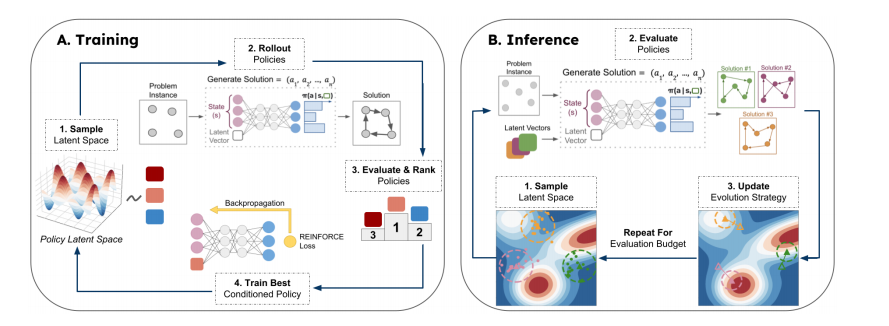
优势:
- 训练单个条件策略原则上可以提供无限数量策略的连续分布
- 减轻了与训练代理群体相关的显著训练和内存开销
- 训练过程产生了一个结构化的潜在空间,允许在推理期间进行原则搜索
潜在空间
定义了模型可以约束自身的一组策略。
COMPASS不学习这个空间的分布,而是选择一个先验分布在训练中抽样的空间上。在实践中,使用一个16维的隐空间,边界在-1到1之间,并使用均匀采样先验。
If I have to describe latent space in one sentence, it simply means a representation of compressed data.
潜在变量(隐变量):数据分布可能是由多个子模型混合的,比如高斯混合模型可以看成是 $K$ 个单高斯模型组合而成的模型,这 $K$ 个子模型就是混合模型的隐变量。
深度学习是一种表征学习,学习过程不是靠一些分布来拟合给定数据的分布,而是通过空间转换来学习数据的特征,从数据分布空间到任务的目标空间。
比如一个CNN网络,输入数据是高维数据,通过卷积网络会压缩到一个低维向量,这个过程是会损失精度的,最后再将这个低维向量转换成输出。中间那个低维向量就是潜在空间的表示。我们可以这样理解潜在空间,人类很难理解三维以上的维度信息,但是可以将高维信息映射到低维,从而使得我们可以理解。高维信息我们无法直接判断两个样本之间的相似度,而低维信息之间我们可以直观地判断。
网络结构
和COMPASS没关系,在附录里面。
训练
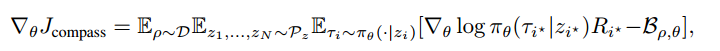
- $\mathcal{D}$ 是问题分布,$\rho$ 是问题的一个实例
- $\mathcal{P}_z$ 是一个潜在空间,$z_i$ 是从潜在空间中采样的向量
- $\tau_i$ 是 $z_i$ 是一个解,$\pi_\theta(\cdot\mid z_i)$ 是一个条件概率,给定 $z_i$ 下策略 $\theta$ 得到的解
- $\tau_{i^\ast},z_{i^\ast},R_{i^\ast}$ 分别是 $N$ 个采样向量中的最佳解、最佳采样、最佳reward
- $\mathcal{B}_{\rho,\theta}$ 是baseline
关键超参数是 $N$。
文章没有讲清楚,我也不是特别理解这个从潜在空间中采样。
我个人的理解是,将 $\rho$ 转换成特征向量后,从特征向量中采样。
推理时候的搜索
采用进化策略。
使用协方差矩阵自适应CMA-ES。CMA-ES使用多元正态分布对向量进行采样,并迭代更新分布的均值,以提高采样向量的预期性能(即每个向量对应的策略找到的解决方案的质量)。协方差也随着时间的推移而调整,要么用于探索(高值,广泛采样),要么用于开发(小值,集中采样)。
对于给定的问题实例,可能存在多个高性能策略,因此并行使用多个独立的CMA-ES组件。为了确保这些分量探索空间的不同区域(或至少采取不同的路径),计算潜在空间的Voronoi embedding,并使用相应的质心初始化CMA-ES分量的均值。该方法具有鲁棒性好、易于调优、速度快、占用内存和计算预算少等优点,是在推理时进行有效自适应的理想选择。
CMA-ES简单来说,根据原样本分布生成100个样本,在这100个样本中选取最好的40个样本,然后再用这40个样本的分布继续生成100个样本,一直迭代,最后会收敛到最优样本。
具体的数学理论可以看:[1604.00772] The CMA Evolution Strategy: A Tutorial (arxiv.org)
实验
问题:TSP、CVRP、JSSP
baseline:EAS、SOTA强化学习(POMO)、Poppy、Concorde求解器(TSP)、L2D(JSSP)、OR-Tools
训练
从POMO的预训练模型开始训练
JSSP选择的是Bonnet的注意力模型
问题规模:100
推理
做了1600次搜索尝试
不使用数据增强
结果
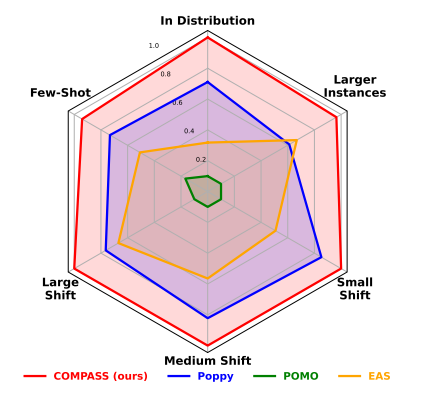
方法性能雷达图
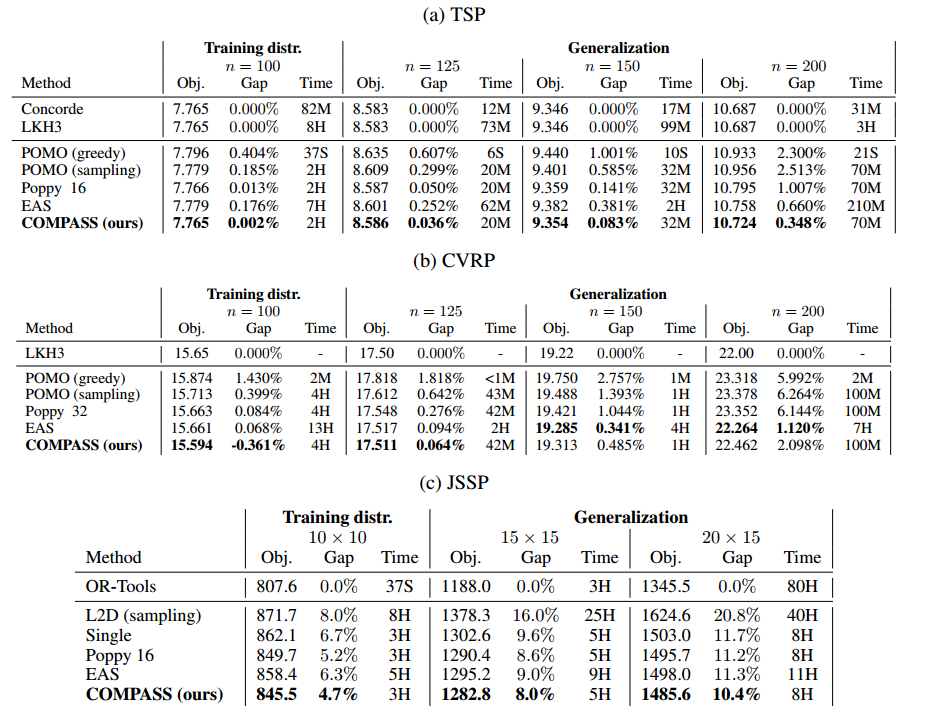
只有一个跑不过,其他都是最优的。
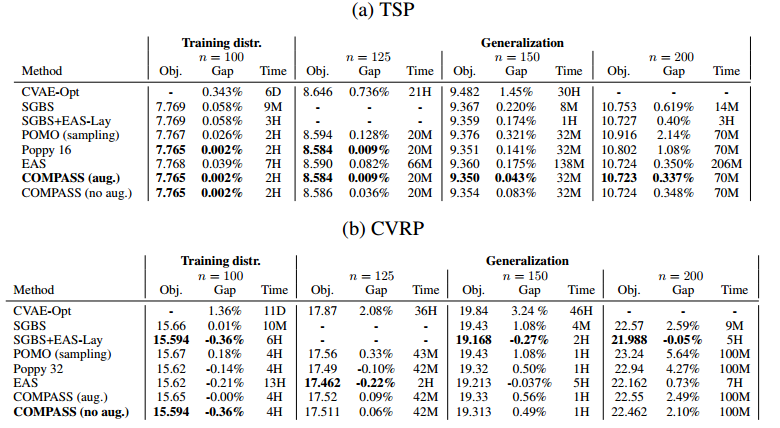
报告了使用数据增强的结果,结果标明,COMPASS不使用数据增强也很好,显示了在潜在空间中实例和发现多样性的能力。
鲁棒性和泛化能力
使用了9种不同的突变操作符(爆炸、内爆、聚类、旋转、线性投影、轴投影、扩展、压缩和网格)。
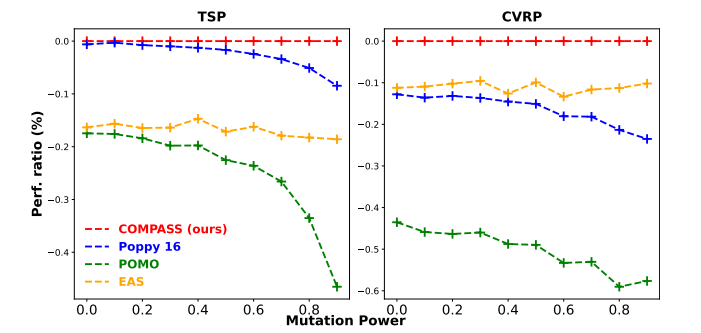
perf. ratio越低越不行,泛化能力很强。
搜索策略分析
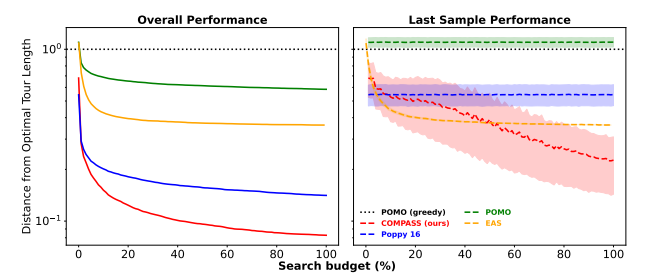
推理的时候搜索的时候,最后一次尝试的均值和标注差。
结论:
(i)自适应方法(COMPASS, EAS)表现良好,因为与随机抽样方法(Poppy, POMO)相比,它们能够随着时间的推移提高其解决方案的平均性能。这也凸显了COMPASS的潜在空间是可以多元化的,是可以开发的。
(ii)高度集中(低方差)的搜索并不总是优于随机探索。具体地说,虽然EAS快速适应了比Poppy平均性能更好的策略(右图),但Poppy的多个不同策略的额外方差意味着它产生了更好的整体解决方案(左图)。
(iii) COMPASS能够将前面讨论的两个方面结合起来,以实现高性能的搜索过程。通过使用自适应协方差机制及其多个组件来导航潜在策略空间的多个区域,它将搜索重点放在有希望的策略(更好的平均性能)上,同时保持宽波束(更高的方差)。
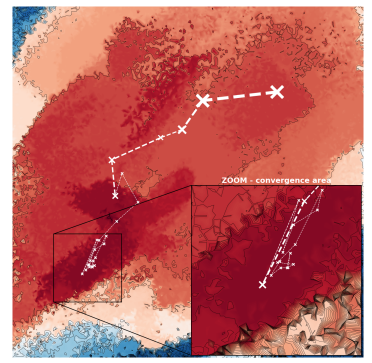
在某个实例上,CMA-ES在二维潜在空间上搜索的轨迹。
一开始搜索的方差很大,后面慢慢收敛。
未来展望
两个限制:
潜在空间所包含的政策的多样性与从培训分布中可以获得的专门化密切相关,因此可能受到限制。我们想检查是否可以通过使用额外的无监督多样性奖励,或通过程序上多样化所使用的分布来获得更广泛的政策范围。
我们的方法的另一个限制是我们的潜在空间缺乏结构。虽然我们证明了它足以通过进化策略成功地探索,但我们假设一个更好定义的空间可以更快地搜索。我们希望在训练阶段检查正则化项的使用来实现这一点