Neural Combinatorial Optimization with Heavy Decoder: Toward Large Scale Generalization
重解码器的神经组合优化:面向大规模泛化
来自南方科技大学和香港城市大学
开源:https://github.com/CIAM-Group/NCO_code/tree/main/single_objective/LEHD
摘要
神经组合优化(NCO)是一种很有前途的基于学习的方法,用于解决具有挑战性的组合优化问题,而无需专家专门设计算法。然而,大多数建设性的NCO方法不能解决大规模实例大小的问题,这大大降低了它们在实际应用中的实用性。在这项工作中,我们提出了一种具有强大泛化能力的新型轻型编码器和重型解码器(LEHD)模型来解决这一关键问题。LEHD模型可以学习动态捕捉所有可用节点之间不同大小的关系,这有利于模型推广到各种规模的问题。此外,我们为所提出的LEHD模型制定了数据高效的训练方案和灵活的解构建机制。通过在小规模问题实例上的训练,LEHD模型可以生成最多1000个节点的旅行推销员问题(TSP)和有能力车辆路线问题(CVRP)的近最优解,并且可以很好地推广到解决现实世界中的TSPLib和CVRPLib问题。这些结果证实了我们提出的LEHD模型可以显著提高建设性非政府组织的最先进性能。代码可在https://github.com/CIAM-Group/NCO_code/tree/main/single_objective/LEHD上获得。
介绍
对于大规模问题,直接训练
- 监督学习满意获得高质量的标签
- 强化学习会遇到稀疏奖励和设备内存限制
因此一个可行的办法是在小规模上训练然后泛化到大规模。但目前基于学习的构造方法的泛化能力都很差。
目前的构造NCO模型都是重编码器和轻解码器的,这是泛化能力差的潜在原因。重型编码器能够一次学习所有节点的嵌入,然后通过轻型解码器构造解决方案,这在小规模实例上表现良好。
贡献:
- 提出一种广义的神经组合优化方法的轻编码器重解码器(LEHD)模型。通过小规模实例的训练泛化到大规模的问题上。
- 为LEHD定制了数据高效的训练方法和灵活的解决方案构建机制。训练方法通过监督学习高效训练,构建解决方案的时候可以通过定制推理预算不断提高解的质量。
- 该方法在求解各种规模的TSP和CVRP都达到最先进的性能,并且在标准数据集上也能够推广。
相关工作
具有平衡编码器-解码器的构造NCO
- 指针网络
- 具有相同层数RNN的编码器和解码器
只能解决规模不超过100的小规模实例,泛化能力较差。
重编码器轻解码器的构造NCO
- Transformer:AM、POMO、EAS、SGBS
非构造性NCO
热图:热图引导beam search、MCTS、DP、local search
模型架构
编码器
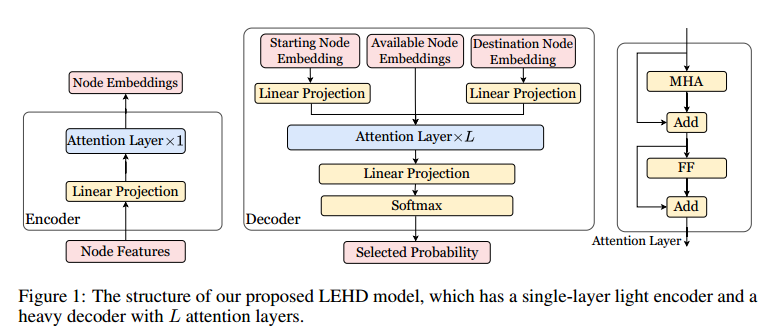
对于一个有 $n$ 个节点 $(s_1,\cdots,s_n)$ 的实例 $S$,用参数化 $\theta$ 的构造模型以自回归的方式生成解。编码器有一个注意力层,解码器有 $L$ 个注意力层。
编码器输入 $(s_1,\cdots,s_n)$,通过Linear Projection转化成 $(h_1^{(0)},\cdots,h_n^{(0)})$,然后经过注意力层变成 $H^{(1)}=(h_1^{(1)},\cdots,h_n^{(1)})$。
解码器
在第 $t$ 轮,当前的局部解可以写成 $(s_1,\cdots,s_{t-1})$,当前所有可行节点的信息可以表示成 $H_a=\lbrace h_i^{(1)}\mid i\in\lbrace 1,\cdots,n\rbrace\setminus\lbrace x_1,\cdots,x_{t-1}\rbrace\rbrace$。 $L$ 层的解码器计算为
\[\begin{aligned} \widetilde{H}^{(0)}&=\mathrm{Concat}(W_1\mathbf{h}_{x_1}^{(1)},W_2\mathbf{h}_{x_{t-1}}^{(1)},H_a),\\ \widetilde{H}^{(1)}&=\mathrm{AttentionLayer}(\widetilde{H}^{(0)}),\\ &\cdots\\ \widetilde{H}^{(L)}&=\mathrm{AttentionLayer}(\widetilde{H}^{(L-1)}),\\ u_i&=\begin{cases}W_O\widetilde{\mathbf{h}}_i^{(L)},&i\ne1\text{or}2\\-\infty,&\text{otherwise}\end{cases},\\ \mathbf{p}^{t}&=\mathrm{softmax}(\mathbf{u}) \end{aligned}\]Learn to 构造局部解
构造方法每一次预测一个节点都需要调用一次解码器,LEHD会比HELD的计算成本更好。而且RL的巨大内存开销、计算成本、稀疏奖励的问题没有得到解决。
数据增强(DA)可以减少监督学习标签的数量,而且求解的准确性和泛化性高于RL。
基于 multiple optimality 和 optimality invariance 是NCO中最常用的DA方法。
作者采用了基于optimality invariance,开发了一种高效的基于DA的监督训练方法。
根据 optimality invariance,最优解的部分解也必须是最优的。作者从每个标记的数据中随机抽取不同大小和不同方向的标记偏解,丰富数据集。
在训练阶段生成部分解决方案
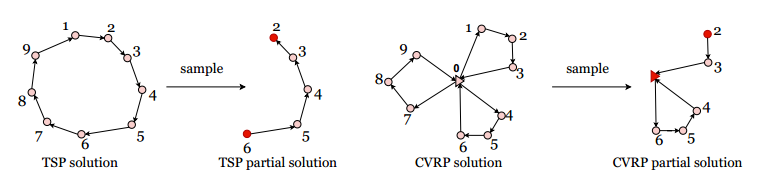
局部解的长度 \(\text{Unif}([4,\mid V\mid])\),均匀分布。
Learn to 构造部分解通过监督学习
交叉熵
\[loss=-\sum_{i=1}^y y_i \log(p_i)\]$y_i=0\ \text{or}\ 1$ 表示当前是否要选择 $s_i$,$p_i$ 是选中的概率。
推理阶段生成完整解
greedy
随机重建以进一步改进
因为推理阶段是greedy选择的,因此构造出最优解是很难的。因此提出是随机重构。
从初始解开始,选择一个部分解,然后重构,看看新的解会不会更好,会就取代原来的解。
实验
对比实验
基于TSP100和CVRP100训练。
TSP测试集包括10000个规模100、128个规模200+500+1000。CVRP也是一样。
TSP的标签用concorde求解器,CVRP的标签用HGS。
解码器的注意力层有6层。
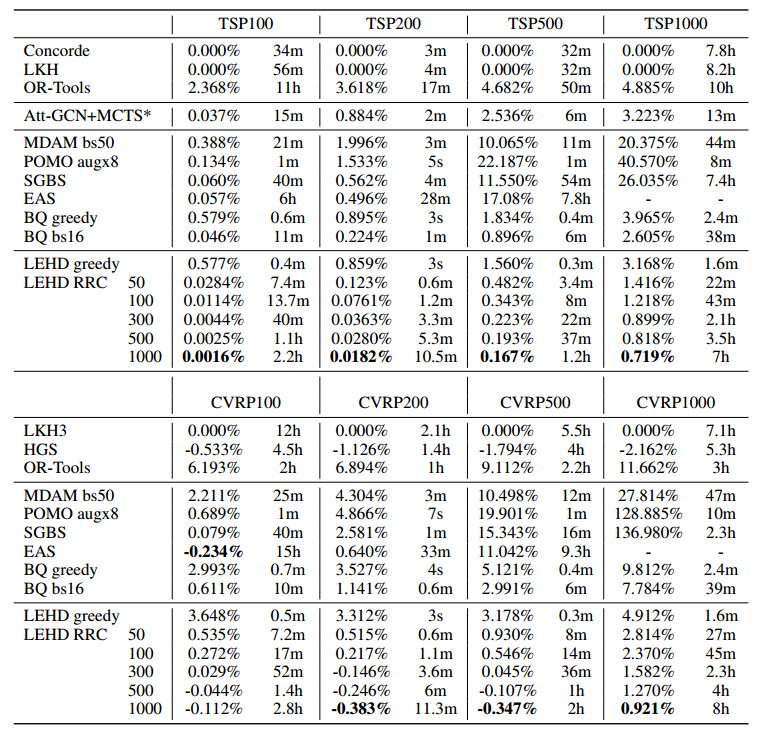
(原始greedy方法确实效果不太好,但迭代改进也太慢了吧)
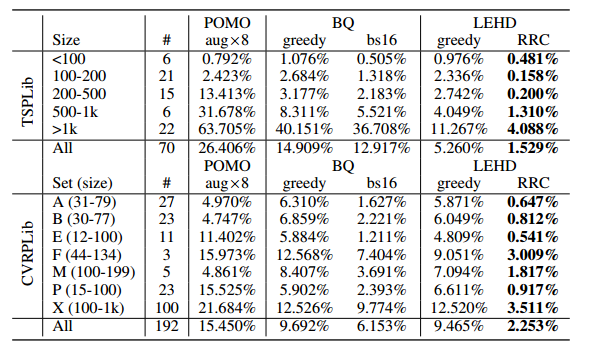
标准数据集上
消融实验
POMO是重编码器,在小规模上表现更好,大规模表现糟糕。

监督学习效果要远远好于强化学习。

随机重构的效果,在大规模上效果变好很多,符合预期
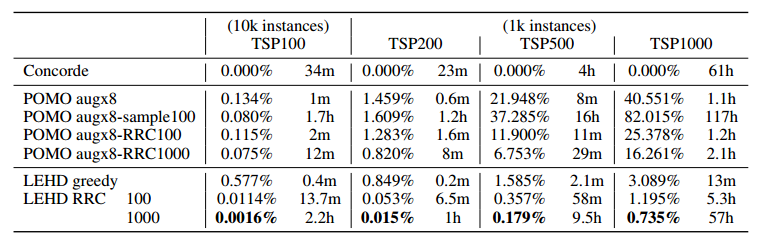
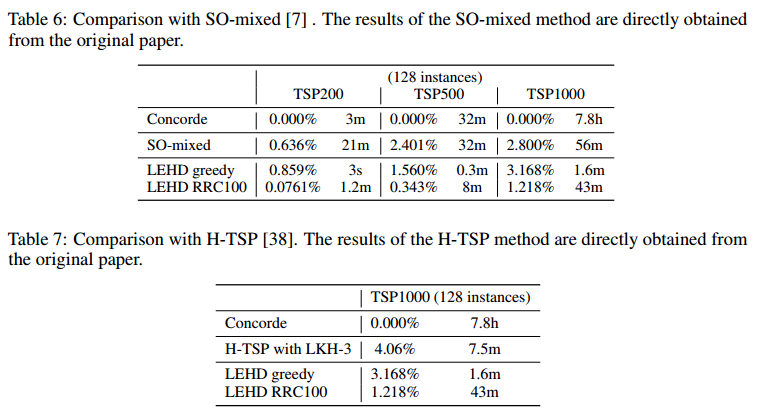
与基于搜索和改进的方法比较
未来工作
限制:监督学习
未来工作:强化学习