Merkle2:A Low-Latency Transparency Log System
2021 IEEE Symposium on Security and Privacy (SP)
Yuncong Hu, Kian Hooshmand, Harika Kalidhindi, Seung Jin Yang*, Raluca Ada Popa
加利福利亚大学,伯克利
摘要
透明日志旨在帮助用户审计不受信任的服务器。例如,证书透明度(Certificate Transparency, CT)使用户能够检测到一个受损的证书颁发机构(Certificate Authority, CA)何时颁发了假证书。然而,实用的最先进的透明日志系统在用于低延迟应用程序时,监控成本很高。为了降低监控成本,此类系统通常要求用户等待一个小时或更长时间才能使更新生效,从而抑制了低延迟应用程序。
文章提出了Merkle2,这是一个透明的日志系统,支持高效的监控和低延迟的更新。为了实现这一目标,文章构建了一个新的多维的、经过身份验证的数据结构,其中嵌套了两种类型的Merkle树,因此系统被命名为Merkle2。使用这个数据结构,文章设计了一个透明的日志系统,它具有高效的监控和查找协议,可以实现低延迟的更新。特别是,Merkle2中的所有操作都独立于更新间隔,并且与日志中的条目数呈(多)对数关系。
Merkle2不仅与之前的工作相比具有很好的渐近性,而且在实践中也是高效的。评估表明,Merkle2在短短1秒内传播更新,并且可以支持比最先进的透明日志多100倍的用户。
前置知识
证书
- 当您通过安全连接 (HTTPS) 访问某个网站时,该网站会向浏览器提供数字证书。此证书用于识别该网站的主机名,由已验证网站所有者的证书授权中心 (CA) 签发。只要用户信任相应的 CA,便可信任证书中提供的身份证明。
为什么证书透明度很重要
- 当前模式要求所有用户都必须相信,数百个 CA 组织在为任何网站签发证书时不会出现任何错误。但在有些情况下,人为错误或假冒行为可能会导致误发证书。Certificate Transparency (CT) 改变了签发流程,新流程规定:证书必须记录到可公开验证、不可篡改且只能附加内容的日志中,用户的网络浏览器才会将其视为有效。通过要求将证书记录到这些公开的 CT 日志中,任何感兴趣的相关方都可以查看由授权中心签发的所有证书。这能够促使授权中心在签发证书时更加负责,从而有助于形成一个更可靠的系统。最终,如果使用 HTTPS 的某个网站的证书未记录到 CT 日志中,那么当用户访问该网站时,浏览器可能不会显示安全连接挂锁图标。
选自:https://www.cnblogs.com/sslwork/p/6193260.html
介绍
透明日志提供一致的、不可变的、只能追加的日志:任何读取日志条目的人都将以相同的顺序看到相同的条目,没有人可以修改日志中已经存在的数据,各方只能追加新的数据。它们的一个显著特征是将区块链/ledgers 的各个方面与传统的集中式托管结合起来。与区块链和ledgers 一样,透明日志依赖于分散的验证,使任何人都可以验证其完整性。同时,它们通常由中央服务提供商托管,例如Google。由于日志提供的保证和第三方的去中心化验证,服务提供商无法在没有检测的情况下修改或分叉日志。此外,集中式托管使这些日志比类似比特币的区块链更高效;它们提供更高的吞吐量和更低的延迟,同时避免了昂贵的工作量证明或对许多用户进行昂贵的账本状态复制。
常见的透明日志是仅追加的日志,它为存储在日志中的键 value 对提供了一个有效的字典。像 CONIKS 这样的最先进的透明日志为应用程序提供了以下关键属性:有效的成员和非成员证明,以及监控证明。特别是,当用户查找键 value 对时,服务器可以提供成员关系或非成员关系的简洁证明,以使用户确信它返回了正确的查找结果。例如,在 CT 中,浏览器只下载对数大小的数据来检查日志中是否存在特定网站的证书。然而,与 CONIKS 不同,CT 不能提供简洁的非成员证明,因此 CT 不能支持有效的证书撤销。
广泛采用透明日志的一个主要障碍是它们的高更新延迟,这阻碍了它们在许多低延迟应用程序中的使用。要了解影响更新延迟的因素,必须首先了解监视,这是透明日志的一个关键组件。监视允许其他方监视不受信任的服务器的状态及其返回给用户的结果。服务器定期(每个epoch)发布一个摘要,总结系统的状态。透明度日志依赖审计员(第三方或个人用户)来跟踪服务器发布的摘要,并相互交流以防止服务器歧义。从日志中查找数据的数据所有者和用户从审计员那里获取摘要。给定摘要,数据所有者可以检查其数据的完整性,用户可以检查来自服务器的查找结果的正确性。
现有的、最先进的、实用的透明度日志(如 CONIKS 或密钥透明度(KT))面临的一个关键挑战是,每个数据所有者都必须监控其数据的每个发布摘要。例如,Google的 KT 提案,引用1秒作为理想的 epoch 间隔(支持各种应用)。对于那些支持10亿用户目标的透明度日志,每秒处理每个用户的监视对于服务器的带宽和计算能力来说都是太大的成本。例如,如果 CONIKS 以1秒的理想 epoch 间隔运行,那么每个用户每年必须下载大约65gb的数据来检查他们的数据。对于10亿用户,服务器必须提供大约65eb的数据。
这种服务器成本与用户和时间的乘积成正比的依赖关系,促使现有的建议设置不频繁的时间,例如小时或天。反过来,在需要低延迟更新的应用程序中,较长的 epoch 间隔会影响响应性和用户体验。以 PKI 为例。先前的透明度日志让用户等待一个小时才能开始使用服务,因为新的公钥出现在日志上需要一个 epoch,以便其他用户可以查找它们。然而,一项研究表明,网络用户的可容忍等待时间仅为2秒。例如,用户可能不希望在注册和设置生成 SK-PK 对的物联网设备之前等待一个小时。此外,密钥所有者可能不希望等待一个小时来撤销泄露的密钥,因为攻击者可能会使用泄露的密钥窃取数据或信息。入侵检测系统等应用旨在立即阻止事件并撤销恶意帐户。
为了降低监控成本,研究人员提出了基于重密码原语的透明日志,如 recursive SNAKs 或 bilinear accumulators。然而,这些工作导致高附加延迟和内存使用。其他工作让审计员代表用户检查每个操作,这导致审计员的开销很高。
因此,本文提出了一个问题:是否有可能构建一个既支持高效监控又支持低延迟更新的透明日志系统?本文提出了一个低延迟透明日志系统Merkle2来回答这个问题。Merkle2的核心是一个新的数据结构,旨在支持高效的追加、监视和查找协议。因此,服务器可以频繁地发布摘要,而数据所有者不需要检查服务器发布的每个摘要。此外,数据所有者只下载多对数大小的数据,以便在整个系统生命周期中进行监控。
本研究实现了Merkle2,并在Amazon EC2上对其进行了评估。Merkle2 可以维持1秒的 epoch 大小,从而支持低延迟应用程序。对于这样的epoch大小,Merkle2 每台服务器机器最多可以支持8 × 106个用户(Amazon EC2 r5:2xlarge实例),比 CONIKS 大100倍。对于监视效率的显著提高,Merkle2中追加和查找的成本仅略有增加;因此,对于大epoch大小,当 CONIKS 的监控成本可以接受时,CONIKS 的性能可能略好于Merkle2。例如,当 epoch 大小为1小时时,CONIKS 可以支持比 Merkle2 多2倍的用户。然而,如此大的epoch大小很难适应各种低延迟应用程序。我们将Merkle2的渐近复杂性与表1中的先前系统进行了比较。

其中,$n$ 是日志条数、$\lambda$ 是 AAD 的安全参数、$E$ 是epoch数、$P$ 是 epoch 之间的追加数。红色表示表现最差。
技术概括
背景
Merkle2 建立在 Merkle 树之上。两种类型的Merkle树在透明度日志中很常见:前缀树(其叶子按字典顺序排序)如 CONIKS 和时间顺序树(其叶子按附加时间排序)如 CT。在先前的透明度日志中,服务器将数据存储在 Merkle 树中,并将根哈希作为每个 epoch 的摘要发布。当用户访问数据时,服务器提供相应叶子的身份验证路径作为证明。
数据结构
时间顺序树和前缀树的优点和局限性是互补的:CT 基于时间顺序树,不需要用户监控每个摘要,但不能提供有效的查找或撤销;CONIKS可以支持有效的查找,但不支持有效的监视。因此,一个自然的问题出现了:是否有一种方法可以将它们结合起来以获得两种好处?
通过利用“多维”数据结构的思想来解决这个问题。Merkle2的数据结构由嵌套的 Merkle 树组成,外层是时间顺序树。时间顺序层的每个内部节点对应于一个前缀树,因此我们的系统的名称为Merkle2。每个数据块的哈希存储在时间顺序树的叶子节点中,并且对于从该叶子到时间顺序树根的每个节点,存储在其相应的前缀树中。文章提供了一种“预构建”技术,以避免在最坏的情况下花费过多的附加时间。
Merkle2的数据结构具有许多方便的属性,能够设计有效的监视和查找协议。例如,每个数据块只存储在 O(log(n)) 个前缀树中,其中 n 是时间顺序层的叶子数。这些前缀树允许基于索引(如 CONIKS)查找数据块。此外,时间顺序层的结构允许设计像 CT 这样的监控协议,这样数据所有者就不必检查每个摘要,而只需检查最新的摘要。
透明日志系统设计
通过利用Merkle2的数据结构,设计了透明日志系统的监控和查找协议。
要避免的第一个问题是数据所有者必须在每个摘要中监视他们的数据。为了解决这个问题,将 CT 中的一致性证明改编为 Merkle2 嵌套树的扩展证明。CT 中的一致性证明允许审计员确保在服务器发布新的摘要时不会删除或修改证书。使用它,域名所有者不需要检查 CT 中的每个摘要。观察到一致性证明不仅保留了叶的完整性,而且保留了内节点的完整性。因为每个内部节点都包含一个前缀树,所以最重要的是不要改变叶子节点 value 或内部节点内容。因此,设计了一个扩展证明,允许审计员确保所有现有节点在未来系统状态下的完整性。进一步说明,扩展证明允许数据所有者只验证最新的摘要,而不是历史上的每个摘要,并确保他们将看到对其数据的早期修改。到目前为止,此证明仅确保内部节点中的前缀树根哈希保持未修改,但不检查前缀树中的实际内容。因此,Merkle2让每个数据所有者检查 O(n) 个前缀树的内容。
为了进一步降低每个数据所有者的监控成本,要求数据所有者只检查 O(log(n)) 个前缀树,以确保其数据块的成员性。此外,由于扩展证明保证,数据所有者在系统的整个生命周期中只需要检查这些前缀树中的每个树一次。然而,通过要求数据所有者只检查 O(log(n)) 个前缀树,并不能阻止攻击者为不属于他们的索引添加损坏的数据块。为了解决这个问题,共同设计了签名链,使用户能够在查找结果中验证数据块的所有权。签名链的安全性依赖于时间顺序树所维护的时间顺序。
最后,设计了一个查找协议,使用户能够有效地验证查找结果。该协议只涉及覆盖整个系统中所有数据块的 O(log(n)) 个前缀树的(非)成员资格证明。此外,设计了一个优化的协议,只查找最新的追加。
贡献
- 一种新的数据结构:Merkle2的数据结构由嵌套的 Merkle 树组成,外层是时间顺序树。时间顺序层的每个内部节点对应于一个前缀树。
- Merkle2 的数据结构具有许多方便的属性,能够设计有效的监视和查找协议。例如,每个数据块只存储在 O(log(n)) 个前缀树中,其中 n 是时间顺序层的叶子数。这些前缀树允许基于索引查找数据块。此外,时间顺序层的结构允许设计像 CT 这样的监控协议,这样数据所有者就不必检查每个摘要,而只需检查最新的摘要。
- 将 CT 中的一致性证明改编为 Merkle2 嵌套树的扩展证明。
- 共同设计了签名链,使用户能够在查找结果中验证数据块的所有权。
- 设计了一个查找协议,使用户能够有效地验证查找结果。
系统概况
在本节中,将描述Merkle2的体系结构和API。Merkle2 是一个由键 value 对组成的透明日志系统。将其称为 ID-value 对,以避免与加密密钥混淆。与 CONIKS 和 Google Key Transparency 一样,Merkle2 基于数据块的ID对分类账上的数据块进行索引,以支持高效的 ID 查找。
系统架构
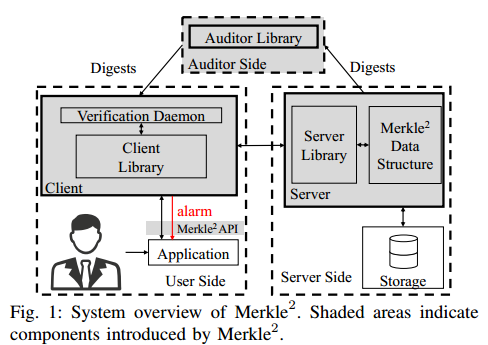
该系统由逻辑服务器、审计器和客户端组成,它们的角色如下所述。
服务器
- (逻辑)服务器存储用户的 ID-value 对,并负责维护 Merkle2 的数据结构和服务客户端请求。服务器为客户端和审计员提供证据以监视系统。在每个 epoch 结束时,服务器向审计员发布汇总 Merkle2 状态的摘要。服务器提供的每个响应都将被签名。
审计员
- 审计员负责验证服务器是否向客户端和其他审计员提供一致的状态视图。在每个 epoch 结束时,每个审计员都会从服务器请求一个服务器指定的总体状态摘要以及一个简短的证明。通过验证证明,审计师确认从前一个时期的状态转换是有效的。审计人员互相谈论摘要,以确保他们对系统有一致的看法,这一点至关重要。如果两个审计员发现同一 epoch 的不同摘要,他们可以通过提供签名来证明服务器的错误行为。
客户端
- 用户运行客户端软件,包括客户端库和验证守护进程。用户的应用程序与客户端库交互,通过 API 追加和查找 ID-value 对。每个用户负责监控服务器上自己的 ID-value 对。将 ID 的所有者定义为在系统中为该 ID 添加第一个 value 的人。只有 ID 所有者才允许为该 ID 附加新 value 。一个用户可以拥有多个 ID。验证守护进程作为一个单独的进程运行,定期监视 ID 所有者的 ID-value 对。在第一次追加之后,守护进程将定期联机并向服务器发送监视请求。
API
append(<ID, value>):将 ID 的新 value 附加到日志。如果在追加之前没有 ID 的 value ,则用户将被标识为 ID 的所有者。否则,只允许 ID 的所有者追加新 value 。服务器同时添加<ID, val>到持久性存储和 Merkle2 的数据结构。直到服务器在下一个 epoch 中发布新的摘要,追加才会生效。对于每个追加,验证守护进程将定期在线并代表 ID 所有者监视,以确保其完整性。lookup(ID):查找 ID 的所有 value 。服务器应该返回到目前为止由 ID 所有者追加的所有 ID value,按照追加时间按时间顺序排序。查找结果不包含当前 epoch 后附加的 value;但是,在这种情况下,服务器可以通知用户在下一个 epoch 发送另一个查找请求。还引入了一个支持最新查找的扩展 APIlookup_latest,它允许用户查找 ID 的最新 value,因为对于许多应用程序来说,最近的 value 是唯一感兴趣的 value。该 value 是在查找操作之前以 epoch 为单位对 ID 进行的最新追加。
威胁模型和安全保障
Merkle2 保护系统免受已经危及服务器的恶意攻击者的攻击。假设的攻击者可以修改数据或控制服务器上运行的协议。特别是,它可以 forks 不同用户的视图或返回旧数据。Merkle2 保证诚实的用户和审计人员将检测到这些类型的主动攻击。
在大多数透明度日志中,假设至少有一些审计员是可信的,这意味着他们将在每个 epoch 结束时验证发布的摘要和证明,并检测 forks。直观地说,要求是任何用户都应该能够联系到至少一个已连接且受信任的审计员。每个 ID 所有者负责监视自己的 ID-value 对。与依赖强ID 所有者的系统不同,Merkle2 中的 ID 所有者不需要监控每个 epoch。他们可以选择监控频率,比如每天一次或每周一次,并在监控周期之间通过只检查最近的 epoch 来监控更新。如果 ID 所有者监视 epoch $p$ 中的摘要而没有检测到违规,那么在 epoch $p$ (包括 epoch $p$ )之前执行 ID 查找的诚实用户就可以保证收到正确的 value 或检测到违规。
文章中包含了具体的形式化表达和证明,在此按下不表。
数据结构
数据结构布局
数据结构的布局如下所示。Merkle2 的数据结构由几个称为时间顺序树(按时间排序)的顶级树组成,对于该树中的每个内部节点,都存在一个前缀树(按 ID 排序)。
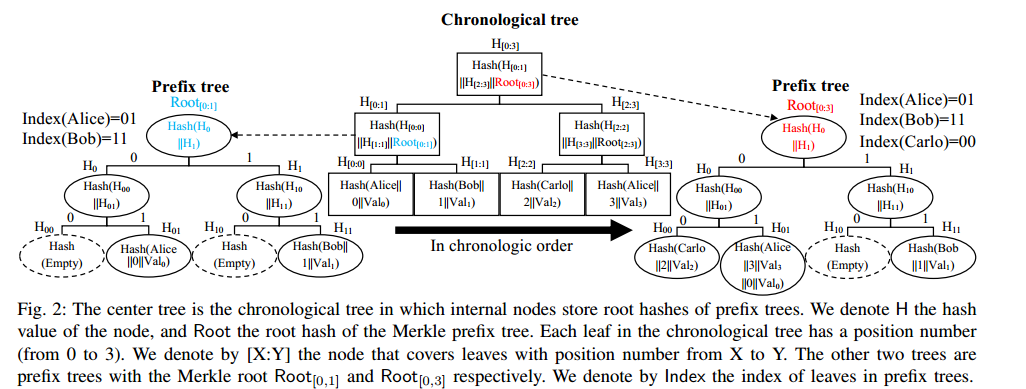
时间顺序树(Chronological tree)
-
时间顺序树将用户的 ID-value 对按时间顺序从左到右存储在它的叶子上。例如,如果Alice在Bob之前向系统中添加一个 ID-value 对,那么她的对将出现在 Bob 的对的左边。每个 ID-value 对都有一个位置号,它表示叶子在树中的位置。例如,在图2中,Alice 有两个 value Val0 和 Val3,这两个 value 分别分配给位置号为 0 和 3 的叶子。ID-value 对稍后可以通过其位置号作为叶节点引用。时间树的每个内部节点都有对应的前缀树,如图2所示。时间顺序树中每个内部节点的哈希值是以下三元组的哈希值:
-
它的两个子节点在时间顺序树中的哈希值
-
该节点对应的前缀树的根哈希值
这允许时间顺序树的根散列总结该时间顺序树中所有前缀树的状态。
-
前缀树
- 前缀树存储用户的 ID-value 对,按字典顺序按 ID 排列。与内部节点相关联的前缀树存储在该节点上根的子树中出现的所有 ID-value 对。例如,在图2中,时间顺序树节点[0:1]对应的前缀树存储了[0:1]子树中的所有子树。因此,[0:1]的前缀树(如图2左侧所示)存储 ID-value 对 Alice;Val0 和 Bob;Val1。同时,图2右侧的前缀树存储了所有的 ID-value 对,因为它与根节点相关联[0:3]。如果用户追加多个 value,它们都将存储在前缀树的同一叶节点下,因为它们共享相同的 ID。由于 Alice 附加了两个 value (Val0和Val3),因此它们都存储在前缀树的同一叶节点中。前缀树中内部节点的哈希值的计算与典型的 Merkle 树一样,其中父节点哈希值是左和右子哈希值连接在一起的哈希值(
H(leftChildHash;rightChildhash))。
选择时间树作为外层的原因是,审计人员可以检查一个简洁的证明,所有的追加在 epochs 之间。相反,如果使用前缀树作为外层,审计人员需要检查的证明的大小可能与 epoch 之间的追加数呈线性关系。这也是 CT 选择时间树的原因。其他系统如 CONIKS 通过要求每个 ID 所有者监视每个 epoch 来避免这种开销。
时间顺序树森林
- Merkle2 的数据结构由一个时间顺序树的森林组成。每棵这样的树都是满的。也就是说,没有一片叶子丢失。当 ID-value 对在epoch $i+1$ 中追加时,我们保留了 epoch $i$ 中时间顺序树的结构,从而维护了这个属性。确保在 epoch $i+1$ 中,只向 epoch $i$ 的现有树添加父树,或者添加单独的树。因此,通过向右扩展 Merkle2 的数据结构来添加叶子;随着更多的叶子被添加,每当我们可以构建一个更大的、完整的二叉树,新的内部节点(和因此产生的新的根)被创建。
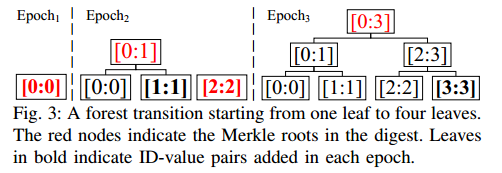
- 图3显示了Merkle2的数据结构在一组追加后的转换。内部节点[0:1]是自动创建的,因为叶子[0:0]和[1:1]可以存储在一个完整的二叉树下。注意,每个内部节点([0:1],[2:3],[0:3])包含前缀树的根哈希,如图2所示。这种森林设计确保旧森林的根作为内部节点保留在森林的任何后续版本中,并且它们的哈希值仍然相同。例如,[0:1]和[2:2]的哈希值在epoch2和epoch3之间不会改变。
- 时空复杂度证明略。
追加 ID-value 对
要附加一个新的 ID-value 对,Merkle2 的数据结构首先通过创建一个包含 ID-value 对的新叶节点来扩展森林。根据叶子位置为 ID-value 对分配一个位置号。然后,Merkle2 的数据结构递归地将最右边的两个时间树合并为一个大的时间树,如果它们具有相同的大小。这个过程不断重复,直到无法合并最后两棵树为止。对于合并过程中创建的每个根节点,必须通过插入该根节点下出现的所有 ID-value 对来构建相应的前缀树。
原文此处是对追加的均摊时间复杂度分析,在最坏情况下,复杂度可能是线性的。为了解决这个问题,引入了预构建策略。首先确定Merkle2 的数据结构支持的 ID-value 对的最大数量。这个数字可以足够大,比如 $2^{32}$。为了附加 ID-value 对,Merkle2 的数据结构将其插入到所有可能的前缀树中,包括那些目前还不存在但应该在将来构建的前缀树。
监控协议
ID 所有者负责监视他们自己的 ID-value 对,而审计员则跟踪服务器在每个 epoch 发布的摘要。监测协议的目标是:
- 避免需要在每一个单独的 epoch 进行监测;
- 使监测在任何给定的 epoch 有效。
为了解决前一个问题,设计了一个有效的扩展证明,允许审计员证明每个 epoch 都是前一个 epoch 的扩展。这样,当 ID 所有者验证 epoch $t$ 的监控证明时,ID 所有者也隐式地验证 epoch $t-1,\cdots,1$。因此,ID 所有者不需要监视每个摘要,只需监视最新的摘要。
对于后一个属性,设计了一个监控证明和共同设计签名链,使 ID 所有者能够验证他们的 value 没有被篡改。
两个部分的扩展证明和复杂度分析略,在此关心签名链的设计。
监控证明仅保证攻击者不能从 Merkle2 的数据结构中删除 ID-value 对,它不会阻止被入侵的服务器添加 ID-value 对(例如,ID 所有者从不检查的前缀树)。例如,在图4中,Alice 无法检测到攻击者在位置25插入了 Alice;Val0,因为Alice在节点[24:27]根的时间树中没有 value ,因此监控证明将不包括节点[24:27]前缀树的成员资格证明。
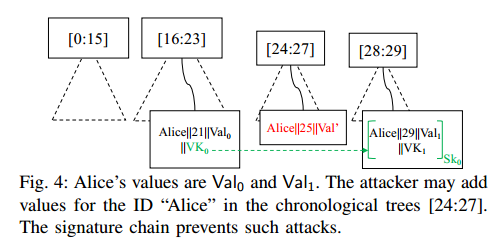
为了防止攻击者添加损坏的 ID-value 对,Merkle2 协同设计了如下签名链。ID 所有者将验证密钥附加到Merkle2中的每个 ID-value 对。此外,每个新的 ID-value 对、它的位置和新的验证密钥都由附加到所有者的前一个 ID-value 对的验证密钥签名。然后,用户可以使用相同的验证密钥验证 ID-value 对上的签名。通过验证签名链,用户可以确认所有的 ID-value 对确实是由 ID 所有者附加的。
在图4的示例中,尽管攻击者仍然可以添加 Alice;Val0 而不被 Alice 捕获,但由于攻击者无法生成有效的签名,其他用户不会接受损坏的对。注意,在查找过程中,攻击者可能会试图隐藏链的末端。监控证明确保攻击者无法在不被发现的情况下隐藏所有者的 value 。
到目前为止所描述的协议仍然是不安全的,因为第一个 value 没有签名。攻击者可能会插入一个损坏的 ID-value 对,并试图让用户相信它是该 ID 的第一个 value。这样,攻击者就可以绕过签名链。然而,观察到,如果诚实的 ID 所有者已经在Merkle2中插入了该 ID 的 value ,那么攻击者无法说服其他用户伪造的 value 是该 ID 的第一个 value 。这是正确的,因为监视证明确保攻击者无法在不被检测到的情况下删除现有 value 。例如,在图4中,攻击者无法隐藏 Alice;21;Val0 并声明 Alice;21;Val0 为“Alice”的第一对。同时,Alice也将通过验证监控证明来检查[16:23]的成员证明。服务器无法提供对于同一前缀树,与 ID “Alice”相关联的叶节点的成员资格和非成员资格证明。
第一个 value 检查。ID 所有者必须确保它确实在 Merkle2 中附加了该 ID 的第一个 ID-value 对,否则其他人可能已经获得了该 ID 的所有权。检查附加在它之前的所有叶子是不可行的。相反,可以利用前缀树的非成员性证明来证明该特定 ID 不存在 value。例如,如果在位置 x 添加 ID-value 对,则存在一个最小时间顺序树集 $Ct_1,\cdots,Ct_n$ 覆盖前 x−1 个叶子(在这个覆盖集中只有 O(log(x)) 棵时间顺序树)。对于 $Ct_i$ 的每个时间根对应的前缀树,可以为 ID 生成非成员证明。非成员证明允许 ID 所有者计算前缀树的根哈希为了计算时间根的根哈希值,$Ct_1,\cdots,Ct_n$ 中,第一个 value 证明还包含这样做所需的最小节点哈希集。这样,ID 所有者就可以计算按时间顺序排列的根的哈希值,并将它们与摘要进行比较。
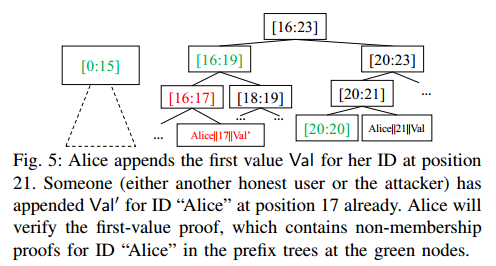
(作者还举了个例子,并做了复杂度分析,但我好像并不是很关心这部分内容。)
LOOKUP协议
我们用 $Ct_1,\cdots,Ct_n$ 表示在Merkle2的数据结构的森林中的时间顺序树,$Pt_1,\cdots,Pt_n$ 表示在它们的根的前缀树,也称之为根前缀树。查找证明必须能够让用户相信查找结果包含给定 ID 的所有 value。通过为所有根前缀树提供(非)隶属性证明,服务器可以证明所有 Merkle2 中给定 ID 的 ID-value 对的(非)隶属性。此外,签名链还可以帮助用户验证查找结果的真实性。
基于这些思想,ID 查找协议的工作方式如下。对于除第一个之外的每个 ID-value 对,查找证明都包含由 ID 所有者签名的签名。对于每个前缀树 $Pt_i$,生成一个证明 $\pi_i$ 如果在 $Pt_i$ 中存在一个 value,$\pi_i$ 是隶属性证明。否则 $\pi_i$ 就是非隶属性证明。查找证明还包含根节点 $C_P{t+i}$ 的左右子节点的哈希值 $LH_i,RH_i$,允许用户计算根哈希,并将其与摘要中的哈希进行比较。最后,查找证明包含签名链和以下元组:$(<\pi_1;LH_1;RH_1>,\cdots,<\pi_n;LH_n;RH_n>)$。直观地,查找证明捕获哪些时间顺序根包含ID value ,哪些不包含 ID value。
例子略。
在查找证明验证过程中,用户拥有以下内容:
- 查找结果,其中包含目标 ID 的所有 ID-value 对;
- 审计器的最新摘要,其中包含森林中每棵时间顺序树的根哈希;
- 与查找结果相对应的查找证明。
用户的操作步骤如下:
- 使用每个 ID-value 对中提供的验证密钥验证签名链;
- 对于每个 ID-value 对,找出它所属的时间树 $Ct_i$ 和对应的前缀树 $Pt_i$;
- 根据步骤2的结果,利用 $\pi_i$ 和 $Pt_i$ 中的 ID-value 对计算每个 $Pt_i$ 的根哈希 $Root_i$;
- 使用 $Root_i$ 和 $<LH_i,RH_i>$ 计算 $Ct_i$ 的根哈希;如果签名链是有效的,并且计算出的根哈希值与摘要中的哈希值匹配,则用户可以接受查找结果。
复杂度分析略。
查找最新的 ID-value 对
提供了一个优化的协议来查找 ID 的最新(即最近) value。在许多应用程序中,用户可能需要最新的 value,而不是所有的 value 。我们使用主密钥(如图6所示)来替换签名链,因为链的大小与 value 的数量呈线性关系。ID所有者生成一对主密钥,并将主验证密钥作为其在日志中的第一个ID- value 对追加。ID 所有者还必须通过验证第一 value 证明来确保主验证密钥是第一个 value。所有由 ID 所有者追加的未来对都将使用主签名密钥进行签名。
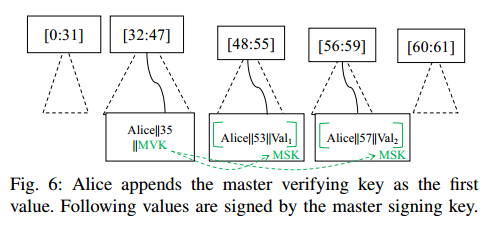
用户无需下载给定 ID 的所有 ID-value 对和签名链,只需下载最新的 value 和主验证密钥来验证签名。用户还需要前缀树的(非)成员资格证明,以确保主验证键实际上是给定 ID 的第一个 value,并且查找结果实际上是最新的。
例子略。
假设 ID 所有者不会在系统中更改他们的主密钥。如果需要,Merkle2 可以允许 ID 所有者更改其主密钥,如下所示。ID 所有者可以通过使用旧主密钥追加和签名新的主密钥来撤销主密钥。但是,允许更改主密钥将增加查找成本,因为其他用户现在也需要检查主密钥的签名链。相反,用户可以使用现有技术在多个设备上安全地备份主密钥,就像他们所做的那样为端到端加密服务提供密钥,例如使用秘密共享。这个修改后的查找协议的成本是O(log2 (n)),因为不再有签名链成本。用户还可以缓存主键,以进一步降低查找的成本。
merkle2的应用
web证书的透明度日志
在安全问题上,证书颁发机构已经被攻破并错误地颁发证书,促使使用透明日志的 web 证书管理系统的设计,其中证书的所有者可以验证他们自己的证书的完整性,并让证书颁发机构对损坏的证书负责。
现在描述如何使用 Merkle2 来代替现有的系统进行证书管理。日志服务器运行 Merkle2 的服务器来管理每个域名的证书。ID 为域名,value 为该域的 web 证书。同一域可能有多个证书。没有将证书存储为不同的域证书对,而是将多个证书捆绑在一起作为单个值,并且每个追加将是该域名的所有证书的哈希值。Merkle2 还通过允许域所有者为同一域名附加所有未被吊销证书的散列来有效地支持吊销。如果证书不在此域名的最新后缀中,则该证书无效(例如,它已被吊销)。最后,web 浏览器可以简单地检索域的最新 value 来检查证书是否有效。
优点:支持撤销,且高效。
公钥的透明度日志
Merkle2 也可以用于透明的公钥基础设施,作为 CONIKS 或 KT 的替代方案。使用端到端加密电子邮件系统作为现实世界的例子。在这个应用程序中,Merkle2 中的 ID 对应于用户的电子邮件,例如alice@org:com,值对应于用户的公钥,例如 PKAlice。为了加入系统,Alice附加了她的电子邮件地址 alice@org:com 的第一个公钥。为了撤销公钥,Alice 为她的电子邮件地址附加了一个新的公钥。如果Bob想发送给Alice的加密电子邮件,他查找alice@org:com的最新公钥,并用它加密并发送电子邮件。对于公司通信,组织可以监控所有的 email-PK 对。对于个人帐户,在用户设备上运行的客户端可以定期监控透明度日志。
优点:监控效率高,低延迟。
隐私问题:能够保障。
实现
用 Go 实现了 Merkle2 的原型。它由四个部分组成,如图1所示:服务器(≈800 LoC)、审计器(≈200 LoC)、客户端库(≈450 LoC)和验证守护进程(≈600 LoC),它们都依赖于一组核心Merkle2数据结构库(≈2400 LoC)。
代码:https://github:com/ucbrise/MerkleSquare
服务器实现使用 LevelDB 在持久化存储中备份 ID-value 对,以防服务器故障,该方法已在以前的透明日志系统中使用。为了提供128位的安全级别,我们使用 SHA-3 作为哈希函数和 Ed25519 签名(这是系统中唯一的公钥操作)。没有实现 VRFs,因为隐私不是本文的重点。为了支持预构建策略,将Merkle2中的时间顺序树高度限制为31,这意味着它最多可以存储 $2^{31}$ 个 ID-value 对,每个追加将添加到31个前缀树中。
评估
实验设置
在 Amazon EC2 实例上进行实验;微基准测试和系统服务器在 r5.2xlarge 实例上运行。审计器和客户端服务分别运行在 r5a.xlarge 和c4.8xlarge 实例上。
baseline
选择了三种最先进的透明度日志进行比较:CONIKS、AAD和ECT。将Merkle2的复杂性与表1中的这些基线进行比较。
通过微基准测试和端到端系统性能比较了Merkle2和CONIKS。最初的CONIKS实现是相当不完整的,例如,它不支持监视或持久存储。此外,由于CONIKS不是为短时期设计的,它在每个时期复制和重建整个Merkle树;这将产生大量的时间和空间成本,这将使CONIKS与Merkle2相比处于不公平的劣势。为了进行公平的比较,增强了CONIKS的设计,使用持久的数据结构,避免了复制整个树的开销。还实现了论文中的监控功能,并将CONIKS数据结构封装到服务器系统中。在CONIKS实现中禁用了 VRFs,因为本文不关注隐私。与Merkle2类似,修改后的CONIKS实现可以在追加期间处理查找和监视,但不允许并发追加。
AAD是建立在双线性累加器之上的渐近高效透明对数,但其常数较大。将AAD的微基准测试结果与他们的论文和存储库进行比较,因为本文的设置不支持运行AAD的实验。例如,生成必要的公共参数需要20多个小时,并且如所示,实验是在r4.16 × large实例上运行的,这比本文实验的机器要强大得多。
还比较了Merkle2和ECT,用于透明web证书的用例。由于没有可用的ECT实现,使用他们论文中提供的数字和其他在线统计数据进行比较。
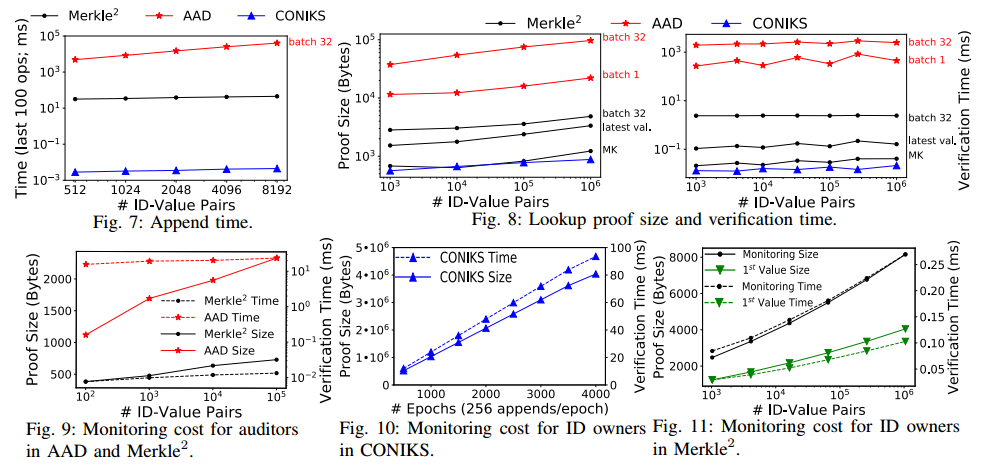
Microbenchmarks
通过对单个操作的微基准测试,将Merkle2的核心协议与AAD和CONIKS进行了比较。
操作包括:
- append time
- monitoring cost
- lookup cost
- memory usage
端到端系统评估
从客户端的角度分析端到端性能,包括证明验证以及与服务器和审计员的通信。
表II显示了平均延迟,表III显示了103个操作的服务器响应的消息大小。对于Merkle2,只度量最新值查找协议,因为它在实际应用程序中更有效和有用。并且,将查找主验证密钥和最新 ID-value 对的成本分开,因为用户可以存储和重用主密钥。结果表明,在Merkle2中追加和查找的开销更大。主键查找的成本比最新值查找的成本低;这是因为由于Merkle2中的森林设计,后者的证明较小。
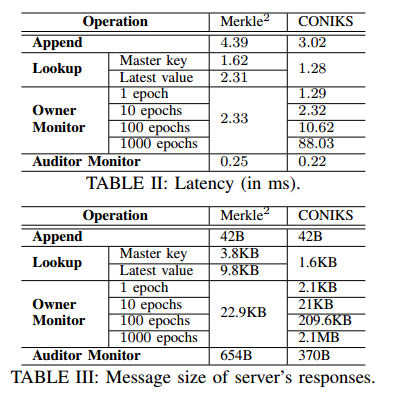
结果表现如下图所示,暂时按下不表。
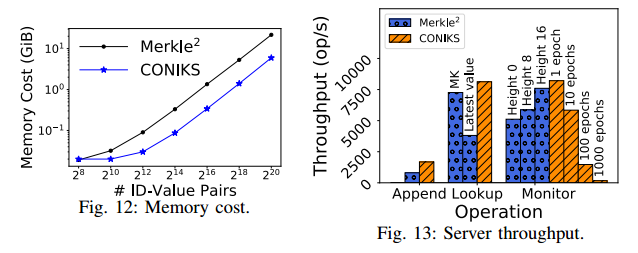
应用程序中的性能
Web证书管理
为了与 ECT 进行比较,根据论文中的数字并借助在线统计来估计ECT的成本。最近的证书统计显示自2018年6月以来大约有5002599,每天新增599个证书。此外,ECT中的审核员需要每个追加 2kb 的数据。因此,ECT 审核员每天必须下载5002599 * 2KB≈9.5GB的数据进行监控。相比之下,Merkle2审计器只需要log(10^9)∗32B∗2≈1.9KB的数据进行监控。
公共秘钥管理
Merkle2支持高效监控,但在追加和查找操作方面牺牲了一些性能。为了理解Merkle2的好处,必须在与目标应用程序匹配的工作负载下运行基准测试。因此,在下面的场景中比较Merkle2和CONIKS。
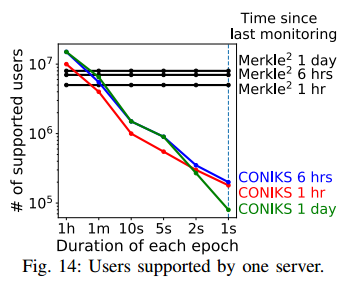
考虑使用可用统计数据加密电子邮件的实际应用。其中,10亿用户每秒发送200个追加内容,每个用户每天发送42封邮件。用户还可以缓存短时间内(例如1小时)发送的电子邮件的公钥。使用 Enron 电子邮件数据集,发现用户需要对大约62%的电子邮件执行键查找。综上所述,每个用户每天可能发送42·62% = 26个查找请求。通过调整平均监控频率来控制监控请求的数量。基于这些结果,在不同的epoch间隔和监控频率下为不同数量的用户生成工作负载。为了保证实验时间合理,在运行前只向系统中加入10^6对 ID-value 对。
局限性和未来工作
实验表明,当epoch间隔较长时,Merkle2的性能不能超过CONIKS,因为追加和查找成为瓶颈。Merkle2留给未来的工作,以提高其追加和查找效率。例如,可以使用一台服务器预构建大型前缀树,以备将来使用;另一个服务器可以缓存较小的前缀树,并更有效地服务用户的请求。此外,可以为不同的用户批量查找证明,并利用代理来节省服务器的带宽。
考虑到数据在Merkle2的数据结构中被复制,内存使用也是一个问题。注意到,与时间顺序树中的正确子树相关联的前缀树是不需要的;因此,通过跳过这些前缀树,服务器可以节省一半的空间。把这些优化留给未来的工作。
相关工作
- 透明日志
- 经过验证的数据结构
- 区块链和共识协议
- 与不受信任的服务器共享文件
总结
在本文中,提出了Merkle2,一个低延迟透明日志系统。Merkle2提供了一种新的经过身份验证的数据结构和利用它的系统设计,从而实现了高效的追加、查找和监视协议。对于短至1秒的epoch, Merkle2服务器可以比CONIKS多服务100倍的用户。Merkle2对web证书和公钥透明度都有应用。
附录
很多,大多是定义和证明相关。