TAP: Transparent and Privacy-Preserving Data Services

出自:32nd USENIX Security Symposium (USENIX Security 23)
摘要
如今的用户期望从处理他们数据的服务中获得更多的安全性。除了传统的数据隐私和完整性要求外,他们还期望透明度,即服务对数据的处理可以由用户和受信任的审计员进行验证。本文目标是构建一个多用户系统,在实现实际性能的同时,为大量操作提供数据隐私、完整性和透明度。
为此,首先确定使用经过身份验证的数据结构的现有方法的局限性。发现它们分为两类:
- 对其他用户隐藏每个用户的数据,但具有有限范围的可验证操作(例如,CONIKS, Merkle2和Proofs of Liabilities);
- 支持广泛范围的可验证操作,但使所有数据公开可见(例如,IntegriDb和FalconDB)。
然后,本文提出 TAP 来解决上述限制。TAP 的关键组件是一种新颖的树数据结构,它支持有效的结果验证,并依赖于使用零知识范围证明的独立审计,以显示树是正确构建的,而不会泄露用户数据。TAP 支持广泛的可验证操作,包括分位数和样本标准偏差。本文对 TAP 进行了全面的评估,并将其与两个最先进的基线(即IntegriDb和Merkle2)进行了比较,表明该系统在规模上是实用的。
介绍
今天的许多应用程序收集大量的用户数据,并做出对用户有直接影响的决策。
- 一个例子是公用事业公司从用户那里收集电力使用数据,并根据每个地区的高峰/非高峰时段收取不同的费用。
- 另一个例子是道路收费系统,该系统根据道路上的汽车数量确定实时交通状况,并向驾驶者收取适当的拥堵费。
- 第三个例子是监视点击并根据点击率向发布者支付广告费用的广告服务。
上述应用程序的一个理想属性是透明度,它允许用户验证对其数据所做的计算是否已正确执行。此属性比简单地确保数据完整性更强大,因为它可以保护用户免受忽略数据或篡改计算的恶意或受损服务提供商的攻击。
实现透明数据服务的一种方法是,提供者将原始数据提供给用户。例如,提供者可以使用公共公告板来存储数据。然后用户可以直接对数据执行计算,但他们没有数据隐私。这在动态道路定价等应用程序中是不可接受的,因为它将允许任何用户使用原始数据跟踪其他用户的移动。或者,服务提供者可以存储数据并只返回查询结果。例如,广告服务可能具有返回给定时间段内广告的总点击次数的API。然而,这种方法不能保证透明性,当提供者有伪造查询结果的经济动机时,这是很麻烦的。
本文的目标是构建一个具有以下属性的数据服务系统。
- 首先,它支持对许多独立用户的数据计算聚合的广泛查询。
- 其次,它保护数据隐私免受敌对用户的侵害。
- 第三,它保护数据的完整性和透明度,不受敌对提供商的影响。
- 最后,它具有合理的性能开销,并且在用户数量增加时可以很好地扩展。
实现目标的一个重要原语是经过身份验证的数据结构(ADS),它允许用户检测提供者返回的不正确结果。然而,文献中的所有ADS提案都分为两大类,这两大类都不能满足要求。
- 第一类包括保证隐私的方法,但支持有限的查询集。这类日志包括透明度日志,如证书透明度日志及其变体,如撤销透明度日志、扩展证书透明度日志、Trillian日志、CONIKS日志和Merkle2日志。透明度日志以键值元组的形式存储数据,并允许公开审计。然而,透明度日志只支持数据插入、删除和查找操作,因此不能满足我们的第一个要求。第一类还包括Proofs of Liabilities(PoLs),它允许用户证明某些用户值的总和是非负的,而不泄露潜在的值。
- 第二类是基于 SQL 的认证数据库,如IntegriDB和FalconDB。这些数据库允许用户验证各种SQL查询的结果——即sum、count、average、min和max。然而,它们要么是为单个用户设计的,因此无法满足我们的第一个要求,要么是将所有插入查询都公开,从而违反了第二个要求。
其他方法只支持透明范围查询,因此无法满足第一个要求。
在这项工作中,提出了一个名为TAP的Transparent and Privacy-Preserving的ADS,这是一个满足四个设计目标的数据服务系统。它用一种新颖的树状数据结构解决了现有系统的局限性,如图1所示,它结合了最适合上下文的现有方法的特性。该数据结构由一个按时间顺序排列的前缀树(如Merkle2)组成,前缀树中的每个叶子都是一个排序的Merkle sum 树(如pol)的根(如IntegriDB)。TAP采用与CONIKS和Certificate Transparency相同的系统模型,其中个人用户监控其数据的包含,并且存在一些审计员来验证数据结构的相关属性,例如,order 和 append-only。前缀树支持有效的监视和审计,类似于CONIKS和Merkle2的数据结构。同时,排序的和树可以快速验证各种操作,包括sum、count、average、min、max和样本标准差查询。TAP还支持分位数查询,该查询允许计算细粒度统计数据,例如滑动窗口的中位数或第5个百分位数。
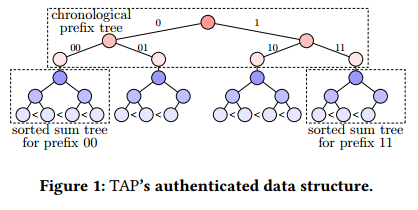
TAP 旨在存储来自多个用户的数据,因此满足了第一个要求。它保护数据隐私,即第二个要求,通过存储加密承诺而不是原始数据,并通过发布零知识证明。TAP的Merkle树结构确保了数据的完整性,并允许用户通过为承诺的潜在值生成Merkle证明和零知识范围证明来验证广泛查询的正确性,即第三个要求。在设置中,例如,在单个数据表中,通过滑动窗口计算聚合,TAP比以前的系统具有更好的性能,因为它维护一个单一的树,而不是IntegrDb中的许多树,并且树比Merkle2中的树小。TAP的计算和带宽开销在滑动窗口的大小上是线性的,但在整个树的大小上是对数的。
为了推理 TAP 的安全性,需要以下条件:
- 每个用户在每个时隙添加一个数据条目,每个时隙的用户集(但不是他们的数据)为监督者(例如,调节器)所知,并且对抗用户的比例是有界的。在这种情况下对TAP的属性进行了详细的分析,并在透明度和隐私之间找到了明确的权衡。专注于以泄露查询结果为代价保证完美的透明度,这些查询结果不能与用户身份简单地联系在一起。
最后的贡献是一个完整的、可公开访问的TAP实现,进行了广泛的实验来评估其性能。将TAP与两个相关基线(Merkle2和IntegrDb)进行比较。结果表明,该系统具有合理的开销,并且在许多情况下优于基线。
贡献:
- 对现有的ADS方法进行了调查,并讨论了它们在当今新兴应用中的局限性。
- 提出了TAP,这是一种多用户数据服务,其ADS结合了CONIKS、Merkle2、IntegriDB和pol的元素,以保护数据隐私和完整性,同时为广泛的操作提供透明度。
- 对TAP进行形式化分析,证明它只显示查询的结果。
- 提出了一个完整的实现,并评估其性能。将其与两个基线(即IntegrDb和Merkle2)进行比较,并显示TAP在许多情况下优于基线。
模型和需求
在本节中,首先讨论一般的系统和数据模型。
接下来,将介绍透明数据服务的三个用例,并讨论它们如何适合我们的模型。
最后,提出了威胁模型和系统需求。
模型实例
- 用户:用户将数据发送到服务器,并通过客户端对聚合数据发出查询。每个用户通过验证服务器是否正确存储了自己的数据并验证查询结果是否正确计算来监视数据结构。在实践中,监控可以是自动化的,例如,用户手机上显示账单或付款的应用程序可以通过查询服务器的ADS来验证显示的值。
- 服务器:服务器将用户提供的数据存储在数据库中,并在数据之上维护一个ADS。它计算对用户查询的响应,并使用ADS为响应生成证明。
- 审计员:审计员验证服务器的ADS。特别是,他们验证它是仅追加的,即数据从未被修改或删除,并且某些数据已被正确排序。
- 公告栏:服务器定期将其ADS摘要发布到不可变的公告板,例如公共区块链。用户和审计人员在监视、审计和查询验证期间下载最新的摘要。布告栏的唯一目的是防止歧义,即,服务器向不同的实体提供不同版本的ADS,因此可以被一个具有相同目的的八卦协议所取代。
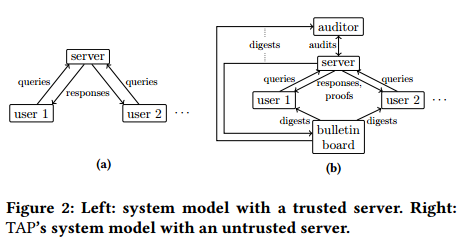
图2a显示了一个naïve设计,它假设服务器是完全可信的,因此允许不道德的操作人员返回不正确的查询结果。图2b显示了本文的系统模型,其中服务器是不受信任的。
数据模型
简单的关系数据模型,由以下属性组成:
- Time:时间被建模为一个epoch序列,即时隙(如小时或天),并被表示为整数。
- value:此属性包含隐私敏感数据。为简单起见,假设它们是非负整数。
- ID:这表示与该值关联的用户ID。
- Type:这些字符串属性捕获有关用户的元数据。
用 $𝑚$ 表示 Type 属性的数量,模式中的属性总数用 $𝑚’ =𝑚+ 3$ 表示。假设每个 epoch 每个 ID 有一个数据条目。这个假设可以防止单个敌对用户任意歪曲查询结果。然而,一个实体可以控制多个 ID,例如,一个人拥有多辆车进行拥堵收费。
用例实例
在下文中,将展示透明数据服务的三个说明性用例。在每种情况下,用户收到的账单或奖励都依赖于记录的数据,包括(可能)其他人的数据。在所有情况下,Time属性都是计费率或奖励率保持不变的最小时间间隔。在下文中,将讨论每个用例的关键特性,包括ID、Value和Type属性、系统的典型规模和查询类型。
- 智能电网:支持峰值/非峰值定价
- ID对应序列号,value 对应客户在epoch期间的用电量,type包括客户的地理位置和客户类型
- 透明数据服务的主要设计目标是允许客户验证其电费账单
- 数据服务允许用户通过求和查询来验证关于系统级的声明
- 数据服务允许计算聚合统计数据
- 同一区域内所有用户用电量的平均值和标准差
- 某一时间段内该区域的最大和最小用电量
- 所有住宅用户用电量排名前5%
- 拥挤定价:车辆在高峰时期通过严重拥堵的指定路段时收费
- ID对应一对车辆和监测架,value对应车辆在epoch期间穿过监测架的数量,type对应检测架和车辆的类型
- 数据服务允许用户验证他们的账单,即使是高级定价方案
- 数字广告
线程模型
考虑两种类型的威胁。
- 第一类是诚实但好奇的用户,他们遵循协议,但试图了解其他用户的隐私敏感数据。
- 第二种是对抗性服务器,它试图通过篡改数据和/或查询执行来伪造查询结果。
这种假设捕获了不道德的服务器所有者、内部威胁和通过软件漏洞进行的外部攻击。不考虑对隐私的威胁源于服务器和用户之间的勾结,因为服务器总是免费发送原始数据给超出协议的敌对用户。然而,一组有限的敌对用户可能会与服务器勾结来伪造查询结果——这包括服务器创建的假用户。
假设服务器和诚实用户之间的所有通信都是通过安全通道完成的。审计人员只能验证服务器ADS的服务器结构属性,而不能验证单个数据条目。实际上,对审计员的信任假设与对用户的信任假设是一样的,即任何拥有大量计算和网络资源的用户都可以作为审计员。在实践中,还假设一个“超级”审计员(例如,监管机构)有能力验证用户身份,以防止服务提供商创建无限数量的假用户。最后,假设公共公告板,或者用户的八卦协议是可信的,并且能够检测到含糊其辞。
需求
- 支持多用户的丰富操作。系统支持对多个独立用户生成的聚合数据进行广泛的操作(或查询)。
- 数据隐私。通过执行查询,用户只能了解有限数量的其他用户的值。
- 数据的完整性。服务器无法在不被检测到的情况下更改数据。
- 透明度。对于每个受支持的查询,服务器无法说服用户接受从不正确、不完整或人为数据计算得出的不正确结果。
- 效率。服务器和用户客户机上的计算、存储和网络成本都很小。查询开销随着用户数量和epoch的增长呈次线性增长。
(后四点也是Merkle2的需求,相比之下,Merkle2只能支持查询、插入、删除,不能支持 sum average 等聚合数据的操作)
现有解决方案
在本节中将讨论部分满足需求的现有方法。将它们分为三类:透明度日志、PoLs 和基于 SQL 的身份验证数据库。
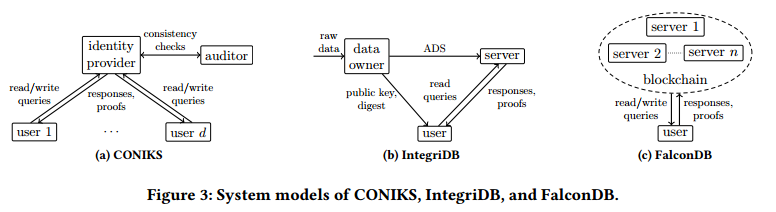
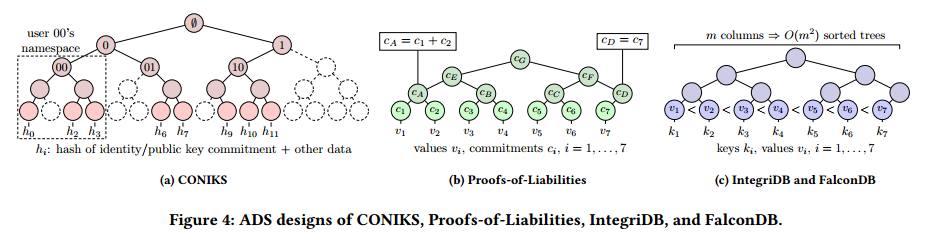
图4显示了各种系统模型的可视化表示,以及一些功能被纳入 TAP 的 ADS 设计。
Certificate Transparency (CT)
CT通过在透明日志中发布证书来解决证书颁发机构受损的问题。CT的系统模型由一些颁发证书并将其插入日志的证书颁发机构和在日志中搜索特定证书的用户组成。CT依靠监视器来确保日志的一致性。核心数据结构是一个Merkle树,其中的证书被散列并存储在叶子处,服务器对树的根进行签名。CT 已经扩展到支持证书撤销的有效验证。它也被概括为一种抽象,称为可验证日志,实现为Google的Trillian。
- CONIKS:CONIKS 扩展了 CT 以支持透明的名称到密钥绑定。它允许有效地证明不包含,以便用户可以轻松地检查其名称空间中未经授权的名称到密钥绑定。CONIKS的系统模型(如图3a所示,用于拥有 $𝑑$ 用户的系统)与CT类似,但用户更主动地监控他们的键绑定。CONIKS使用前缀树(如图4a所示)进行有效的不包含证明。它通过仅在叶子处存储绑定的承诺来隐藏绑定。它还通过添加虚拟节点来隐藏用户总数。
- Merkle2。Merkle2 通过一种数据结构扩展 CONIKS,从而实现高效的审计。该数据结构结合了按时间顺序排列的Merkle树和前缀树。时间顺序树的叶子只向右延伸(仅追加)。每个内部节点保护时间顺序树中的一组叶子,并存储具有相同叶子集的前缀树的根。
Proofs of Liabilities (PoLs)
PoLs 的设计目的是在用户完全匿名且其个人资产和负债对隐私敏感的情况下证明偿付能力——即资产大于负债。PoLs中的主要数据结构是一个Merkle sum树,如图4b所示,它在叶子中存储对资产和负债值的加法同态承诺。中间节点将承诺的总和存储在其子节点中。为了证明叶子中的资产和负债之和是非负的,PoLs 使用零知识范围证明。
基于 SQL 的认证数据库
- IntegriDB:系统模型是为外包数据库设计的。特别是,用户将数据和元数据上传到不受信任的服务器,如图3b所示。服务器执行用户查询并基于元数据生成证明,以表明结果是正确的。IntegriDB支持数据插入、多表连接查询、多维范围查询以及sum、count、average、min和max查询。IntegriDB 为每个列对创建一个排序树,为包含 $𝑚$ 列的表生成 $\frac{1}{2}(𝑚^2−𝑚)$ 个树,如图4c所示。在树的每个内部节点中,IntegriDB 在内部节点的子树叶子中的值上存储一个多项式。多项式可以证明在正确的叶子集合上执行了求和或范围查询。同时,树的排序特性允许用户验证最小和最大查询。
- FalconDB:将IntegriDB与区块链结合起来。在FalconDB的系统模型中,如图3c所示,智能合约维护ADS并确保其全局一致。查询直接由运行IntegriDB的服务器执行,而不需要经过协商一致(插入和删除除外)。用户通过检查服务器上的 ADS 是否与区块链中的相同来验证结果。
现有方案的限制
-
透明日志满足我们对多用户支持、隐私、完整性和效率的要求。但是,支持的操作范围(即插入、删除、包含和不包含)太有限,无法实现需求1。
-
类似地,PoLs不能实现需求1,因为它们只支持和查询,而不支持标准偏差、最小/最大值或分位数。
-
IntegriDB和FalconDB支持需求3、4和5,但不能同时支持需求1和2。IntegriDB的系统模型假设单个用户在将ADS上传到服务器之前正确地生成ADS。因此,IntegriDB不容易扩展到支持多个独立用户。特别是,服务器可以维护单独的数据库和ADS,但如果用户不自己在整个数据上构建数据结构,则无法验证对聚合数据的操作。因此,用户必须知道彼此的数据,即系统不能同时实现R1和R2。FalconDB支持多用户,但所有数据都存储在区块链上,因此不满足R2。
TAP
预备知识
文章使用了几种加密原语。由于篇幅限制,在这里仅对它们进行简要定义,请读者参考文献了解它们的正式和完整定义。
- 哈希函数 H
- 承诺方案 COM(COM.SETUP 和 COM.COMMIT)
- 用 $C(v,r)$ 表示用种子 $r$ 对 $v$ 的承诺,这个加密的加性同态的。
- 非交互式零知识证明(NIZK.SETUP、NIZK.VERIFY和NIZK.PROVE)
- Merkle Tree:一个二叉树,其中每个节点存储一个散列值。散列具有以下结构。
- 叶子包含存储在树中的值的散列。
-
对于内部节点,他的取值是 $h_i=H(h_{left(i)} h_{right(i)})$,即左右儿子的散列值的拼接,没有的儿子的散列值为0。 - 叶子节点的承诺是 $c_i=C(v,r)$,其中 $v$ 是叶子节点的 value,$r$ 是随机种子,中间节点的承诺是两个儿子的承诺相加。
- 前缀树:一个二叉树,其中每个叶子对应一个 key-value 对 $(a,b)$,其中 $a$ 是一个比特串。
- 一个具有 $a$ 比特串的中间节点,其左右节点分别为 $a$ 最后拼接0 和 1;根节点的比特串为空。
- 前缀树可以扩展为Merkle前缀树。
数据结构
TAP中的ADS将单个Merkle前缀树与多个排序的Merkle sum树相结合。前缀树中每个叶子的键值对应于Time和Type属性值的唯一组合,而其值则是排序后的Merkle和树的根哈希值。这个Merkle和树是由Time和Type属性等于前缀树叶键的数据的Value属性构造的。树按照叶子的值升序排序。每个叶子不仅存储原始值 $v$,还存储 $𝑣^2,𝑣^3,\cdots,v^z$ 。这些值可以用于计算高级统计数据(如标准差),同时对排序没有影响。
前缀树存储在内存中,而完整表存储在SQL数据库中。除了存储在前缀树叶子中的根散列外,不将Merkle和树保存在内存中,因为在查询期间可以轻松地动态构造Merkle和树。
(初始化过程和例子略)
Queries
包括 insert、Lookup、Range cover、Sum/count/average/standard deviation、Min/Max、Quantile的处理。
审计
审计员请求服务器生成证明,证明该树是仅追加的,并且求和树是按叶值排序的。为了证明位于epoch $t$ 的树是由位于epoch $t’ <t$ 的树以只追加的方式构建而成的,服务器包含每个前缀树的叶子 $i$,其 Time 属性 $s_i’$ 满足 $t’<s_i’<t$。
此外,它从位于 $t’$ 的树发送一组内部节点,以便可以从这些节点中的散列重新构建位于 $t$ 的树的根。然后,审计员从公告板请求 $t$ 和 $t’$ 的摘要,并检查它是否可以使用新的叶子和旧的内部节点重建这两个树。为了证明sum树的叶子 $v_1,\cdots,v_{n^\ast}$ 是有序的,服务器执行以下操作。对于每个 $i=1,\cdots,n^\ast-1$,它生成一个 $v_{i+1}-v_i\geq 0$ 的零知识范围证明,并将证明发送给审计师。
分析
针对五个需求的证明,略。
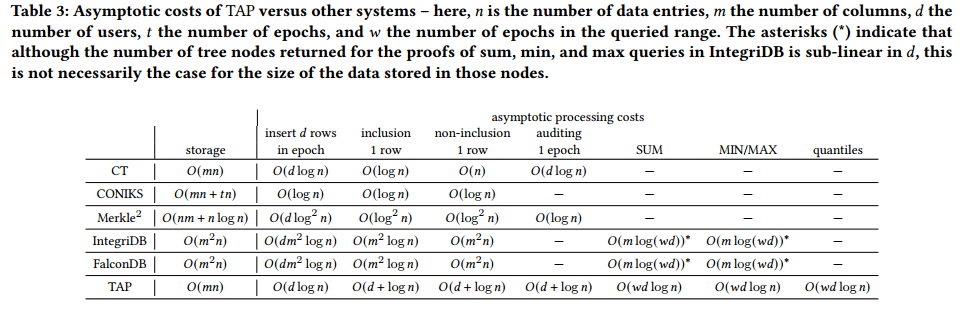
$n$ 是数据条目的数量,$m$ 是列的数量,$d$ 是用户数,$t$ 是 epoch 的数量,$w$ 是查询范围内的 epoch 的数量。星号表示,尽管在 $d$ 中IntegriDB中sum、min和max查询的证明返回的树节点的数量是次线性的,但对于存储在这些节点中的数据的大小来说,情况并非一定如此。
评估
在本节中,将评估 TAP 的实际性能。首先描述了我们的实现,然后讨论了实验设置,最后给出了实证结果。
进行了四种类型的实验:
- 单台机器上的微基准测试
- 不同机器上的用户和服务器的端到端实验
- 与两个相关基线的性能比较
- 探索TAP限制的扩展性实验。
最后三组实验是在Amazon Web Services (AWS) EC2上运行的。
实现和设置
实现语言:Go
代码仓库:https://github.com/tap-group/transparent-data-service
前缀树实现基于Merkle2。对于承诺和零知识范围证明,使用Morais等人的 zkrp 库。该库使用 Bulletproofs 进行零知识范围证明,使用secp256k1 椭圆曲线的 Pedersen 承诺进行加性同态承诺。使用Go的 MySQL 模块作为数据库后端。
baseline:使用截至2022年6月的integrdb和Merkle2参考实现的最新版本。
- 使用Merkle2作为查找查询和审计的基准
- 使用IntegriDb(尽管有不同的系统模型和对更广泛SQL查询的支持)作为聚合查询的基准,因为它是所知道的使用公开可用代码的最有效的方法。
- 尽管 vSQL 报告了在更一般的SQL查询类上与IntegriDb相当的性能,但没有将vSQL作为基准,因为它的实现不是公开可用的。
微基准测试
首先评估单个机器上不同查询的带宽成本。对于这个实验,考虑 $𝑑= 100$ 个用户,每个用户每个 epoch 插入一个新值。有两个Type列:region 和 is_industrial。每个用户被随机分配到 10 个区域中的一个,20% 的用户将 is_industrial 设置为1,其他用户将其设置为0。
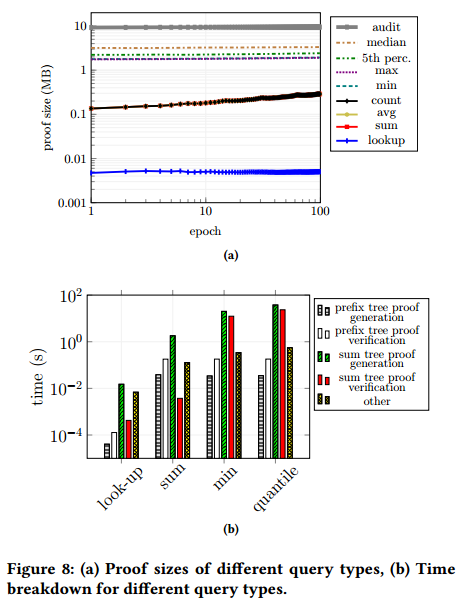
图8a比较了不同查询(包括审计)的验证大小。
- lookup 具有最小的证明,因为它们仅由两条Merkle树共路径组成。
- 后面是sum、count和average,它们的证明包括范围查询中的所有前缀树叶子。
- 接下来是min和max,它们为每个和树添加范围证明。
- 对于分位数查询,观察到中位数和第5百分位数之间存在一些差异——前者具有更大的证明大小。原因是,对于每个子树,如果和树的所有值大于或小于分位数,查询只需要一个包含和范围证明,否则需要两个包含和范围证明。前一种情况更有可能出现在第5个百分位数。
- 审计的证明是最大的,因为它包含𝑂(𝑑)范围证明。
即使在这种情况下,每个epoch的大小也保持在10MB左右。
端到端表现
在 $𝑛= 1000$ 和 $𝑚= 5$ 的设置中测量不同用户查询的端到端延迟。图8b显示了详细的细分。将总时间分为五个部分:
- 前缀树证明生成:生成查找的前缀树包含证明的时间,以及其他查询的范围覆盖证明的时间。
- 前缀树证明验证:验证前缀树证明的时间。
- sum 树证明生成:用于查找 sum 树包含证明的时间,用于验证和查询承诺所需的哈希值,以及用于其他查询的 sum 树包含证明和范围证明的时间。
- sum 树证明验证:验证 sum 树证明的时间。
- 其他:网络延迟和任何其他费用。
观察到网络延迟是端到端延迟的一个重要因素。正如预期的那样,该成本与证明尺寸成正比。剩余的成本主要是重建 sum 树的成本。对于求和查询,范围覆盖证明有很大的影响,但它们的成本仍然比 sum 树证明小一个数量级。对于最小/最大查询和分位数查询,与 sum 树证明相关的成本特别大,因为它们由生成和验证零知识证明的成本主导。sum, min和分位数查询的端到端延迟分别为1𝑠,23𝑠和60𝑠,这对于低端虚拟机是合理的。
与baseline比较
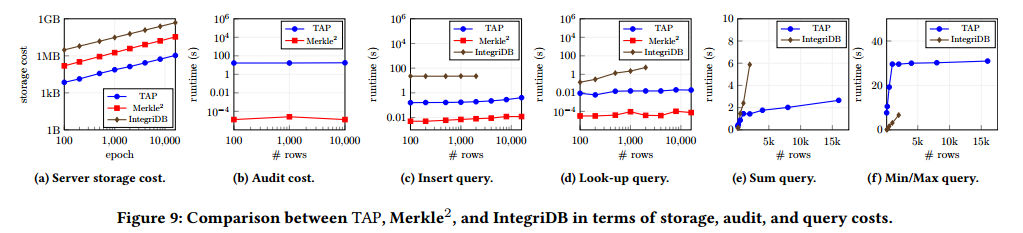
为了为表3中所示的渐近成本差异提供经验证据,将TAP与IntegriDb和Merkle2在不同查询和不同数据大小下进行比较。
- 图9a显示了这三种系统的存储成本。由于TAP不存储Merkle承诺树,而是在查询期间动态生成它们,因此它具有最低的存储成本。IntegriDb的成本最高,因为它需要存储至少25个与Merkle2具有相同叶子数量的树的副本。
- 在图9b中,显示了TAP与Merkle2的审计成本。从这个图中省略了IntegriDb,因为默认情况下它不支持审计。可以看到,与Merkle2相比,TAP 中的审计成本要高几个数量级,这是因为TAP中的审计人员每个 epoch 必须评估数十个零知识范围证明。然而,注意到,在低端机器(t2.xlarge)上审计一个具有100个新条目的epoch只需要60𝑠。
- 图9c显示了在一个 epoch 中插入100个数据条目的成本。Merkle2比 TAP 快,因为前者不需要动态生成和树。然而,IntegriDb的性能最差,因为新数据需要插入到至少25棵树中。
- 查找查询的结果如图9d所示,与插入查询类似,尽管IntegriDb的查找成本比其他查询增长得更快。当对超过2000行的表执行查询时,IntegriDb引用实现崩溃了。
- 图9e比较了TAP和IntegriDb在前10个epoch上求和查询的开销。尽管IntegriDB中的证明大小仅取决于构成总和的值的最小覆盖集,但我们观察到,它的总成本在行数上呈线性。
- 对于min max查询,观察到相同的结果,如图9f所示。通过将图9f中的线外推到IntegriDB实现崩溃的地方,推测在表大小达到10,000行之前,IntegriDB将比TAP更糟糕。
稳定性
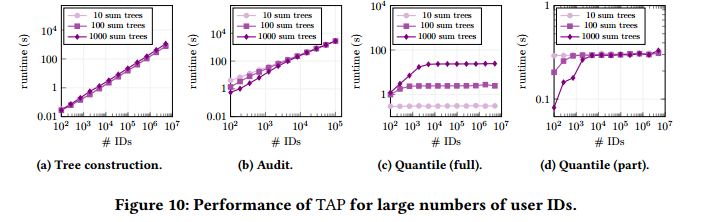
在本节中,将在一台中型AWS机器(m5.4 × large)上研究TAP在实际用户id数量下的性能。
- 图10a显示了为不同数量的 ID 和 sum 树构建TAP数据结构的成本。观察到,拥有10个子树和100个子树的树之间的差异可以忽略不计,但拥有100个子树和1000个子树之间的差异却很明显。特别是,对于1000个子树,构建树所花费的时间大约比100个子树多50%:原因是每个子树的构建依赖于SQL选择查询来获取叶值,即,当子树数量很大时,这将成为瓶颈。
- 在图10b中,将完整审计的成本显示为用户id数量的函数。观察到,对于大量 ID,审计成本类似于 ID 数量的线性函数。对于大约15,000个 ID,无论子树的数量如何,完整审计都需要420秒。
- 图10c显示了对整个数据集进行分位数查询的成本。成本逐渐变得只依赖于子树的数量,因为主要工作负载包括为每个子树创建 zk-range 证明。
- 在图10d中,显示了查询由10个子树组成的固定范围的开销。查询的成本与子树的总数无关,只与 ID 的数量呈对数关系,这在实际规模上是不可见的。
讨论和限制
- 比例限制:大规模上仍需要一定开销
- 报告不当行为:TAP的透明属性确保如果服务器以可验证的方式行为不当(例如,签署明显错误的查询结果),则可以通过八卦或公告板检测并传播。服务器通过伪造用户数据来进行不当行为的情况更难检测和证明。在这种情况下,设想用户将向监管机构或消费者监督机构提出上诉。假设服务器有信誉需要保护,而这种信誉会因为频繁的投诉而受到损害。
- 激励措施:TAP希望每个用户独立地、持续地验证自己的数据,并在数据伪造的情况下充当举报人。因此,TAP的用户必须有监视测量的动机。
- 信任模型:在实践中,TAP用户不仅依赖操作符插入数据,而且还依赖于开发验证查询证明的应用程序/客户端。在这种情况下,恶意服务器既可以伪造数据,也可以故意在客户端中插入错误,以错误地说服用户相信证明的有效性。因此,需要额外安全性的TAP用户有能力编写自己的代码进行证明验证是至关重要的。
- 用户身份:TAP在用户完全匿名的设置中是不切实际的,因为这样的设置将允许服务器创建无限数量的假用户。然而,假设监管机构能够检测到(大量)虚假用户的存在,特别是如果他们对查询结果有重大影响。
总结
TAP 是一个多用户数据服务,为用户查询提供数据隐私、完整性和透明度。TAP中的ADS结合了按时间顺序排列的前缀树和排序的和树,这些和树的根存储在前缀树的叶子中。这种数据结构允许TAP支持范围广泛的查询,这些查询对于新兴的数据服务非常有用,并且具有良好的大规模性能。
在未来的工作中,计划明确用户的隐私成本——也就是说,如果取一个包含有很少叶子的和树的聚合,那么这比每个和树都有很多叶子揭示了更多的信息。这样就可以给每个用户分配一个隐私预算。未来工作的另一个有趣方向是为TAP添加对其他查询的支持,例如,最近的一组测量和另一组聚合之间的 Spearman 秩相关性。