Cross-Problem Learning for Solving Vehicle Routing Problems
求解车辆路线问题的交叉问题学习
来自:A*STAR
IJCAI 2024
代码:https://github.com/Zhuoyi-Lin/Cross_problem_learning.
摘要
现有的神经启发式算法通常针对每个特定的车辆路径问题(VRP)从头开始训练深度架构,忽略了不同VRP变体之间的可转移知识。本文提出了一种跨问题学习方法来辅助不同下游VRP变量的启发式训练。特别是,将复杂vrp的神经体系结构模块化为:
1)处理旅行推销员问题(TSP)的主干Transformer,
2)处理复杂vrp中特定问题特征的附加轻量级模块。
因此,本文提出对TSP的主干Transformer进行预训练,然后将其应用于针对每个目标VRP变体的Transformer模型的微调过程中。
- 一方面,同时对训练好的主干Transformer和特定问题模块进行了全面微调。
- 另一方面,只微调小型适配器网络和模块,保持主干Transformer不变。
在典型vrp上进行的大量实验证实,
1)完全微调比从头开始训练的微调获得了明显更好的性能,
2)基于适配器的微调也提供了相当的性能,同时显着具有参数效率。此外,我们的经验证明了我们的方法在交叉分布应用和通用性方面的良好效果。
介绍
神经方法的限制:
- 只能针对单个问题
- Transformer的计算开销和内存成本大
- 训练两个不同但相关的问题的时候,需要从头训练浪费了潜在的可转移知识
不同的VRP变体之间在数学上只有少量的约束不同,相应的神经启发式仅在其各自的神经结构的几层中是不同的。因此理论上可以利用神经网络的公共部分来传递学习到的参数。
本文主要回答的问题是“VRP训练的神经启发式是否有利于其他类似变体的训练,以及如何部署它?”为此,首先使用Transformer模型预训练TSP的神经启发式,然后利用预训练模型作为骨干,通过微调促进其他(相对)复杂VRP变体的神经启发式学习。
本文主要回答的问题是“VRP训练的神经启发式是否有利于其他类似变体的训练,以及如何部署它?”为此,我们首先使用Transformer模型预训练TSP的神经启发式,然后利用预训练模型作为骨干,通过微调促进其他(相对)复杂VRP变体的神经启发式学习。
具体来说
- 首先基于TSP的主干Transformer模型对复杂vrp的神经架构进行模块化,其中主干之外的附加轻量级模块用于处理复杂vrp中的特定问题特征。
- 然后,直接将预训练好的主干应用于TSP 在复杂vrp的神经启发式训练过程中,通过对主干以及特定问题模块进行全面微调。
- 最后,提出了三种基于适配器的微调方法,以进一步提高参数的使用效率。大量的实验证实,在复杂vrp上完全微调的Transformer明显优于在每个vrp上从头开始训练的Transformer。基于适配器的微调方法不如完全微调,但与从头开始训练的方法相当,训练参数要少得多。
- 此外,我们实证验证了关键设计在微调过程中的有效性,以及我们的方法在交叉分布应用中的良好效果。
值得注意的是,所提出的方法具有足够的通用性,可以用于不同的模型来学习vrp的有效神经启发式。综上所述,本文在以下四个方面做出了贡献:(重复上面四点)
相关工作
- VRP的神经启发式
- 预训练、微调
预备知识
关注 TSP、OP、PCTSP、CVRP
- VRP描述
- 基于Transformer的构造启发式
- MDP
- REINFORCE
方法
用于解决vrp的跨问题学习属于预训练-然后微调范式。给定一个基本VRP的Transformer(本文为TSP),训练它学习用DRL算法求解基本VRP的神经启发式算法。然后,将预先训练好的Transformer作为主干,通过微调训练下游vrp的神经启发式算法。根据Transformer的模块化,提出了不同的微调方法,可以使用问题特定模块对主干网进行全面微调,也可以使用小型适配器网络对轻量级问题特定模块进行微调。下面,详细阐述了vrp Transformer的模块化,DRL对TSP的预训练方法,以及不同的微调方法。
VRP Transformer 模块化
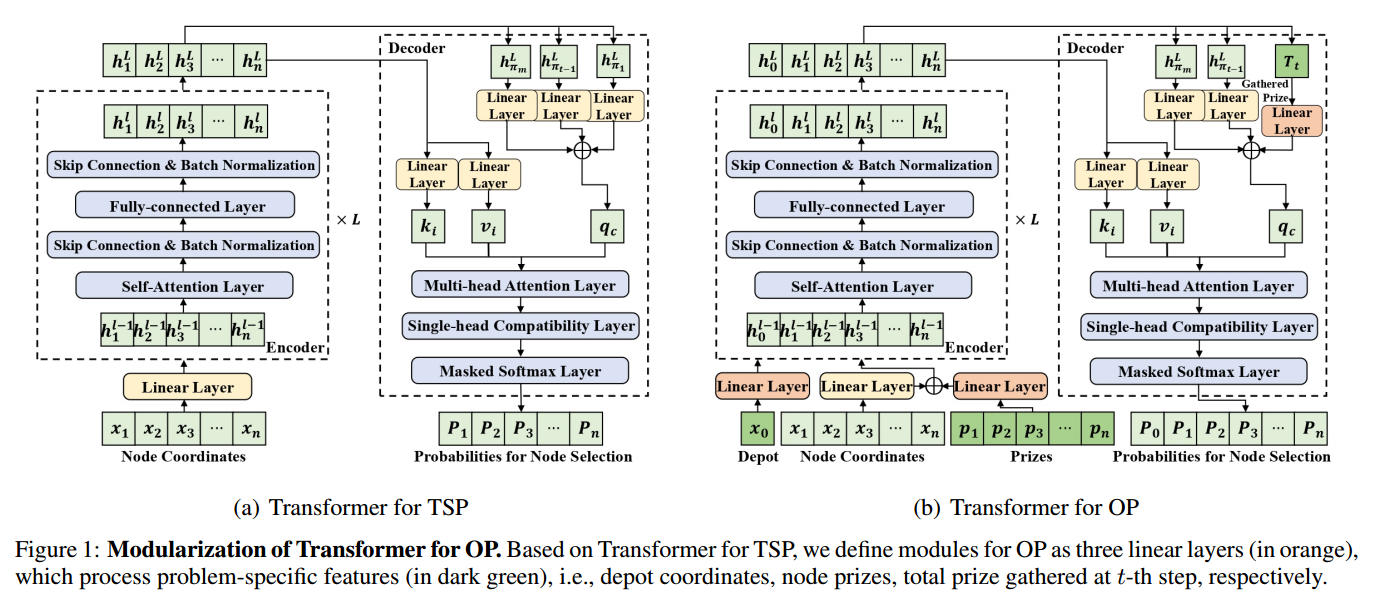
如图所示,用于OP的Transformer被模块化为主干Transformer(用于TSP)加上三个附加的线性层来处理附加的特性。同样,可以模块化变压器的其他vrp,如PCTSP和CVRP。以PCTSP为例,只需要在编码器之前转换1)仓库的坐标、奖品和惩罚,2)在解码器中转换剩余的奖品。(其实分别对应编码器和解码器的输入)
TSP上的预训练
鉴于上述模块化,本文建议首先为TSP训练主干Transformer,然后为下游任务微调特定于问题的模块。使用TSP作为预训练基本任务的基本原理是:
1)如模块化所示,TSP的变压器包含在其他vrp(例如,OP, PCTSP)的变压器中;
2)作为基本VRP, TSP仅以节点坐标为特征,其他VRP也包含节点坐标。因此,我们可以利用TSP的骨干变压器来学习有用的节点表示来反映vrp中的常识(例如,节点位置及其距离),然后将骨干变压器插入下游vrp的变压器中。
(简单来说,TSP是最基础的VRP,其他复杂VRP去掉约束后都相当于TSP)
Full Fine-Tuning for VRPs
一种直接的微调方法是利用TSP预训练的AM作为为任何下游VRP训练Transformer的热启动。
通过经验观察到,与为每个VRP从头开始训练神经启发式的现有方法相比,这种简单的微调能够显著提高训练效率。
Adapter-Based Fine-Tuning for VRPs
尽管可以方便地实现完全微调,但它仍然依赖于每个下游VRP需要训练的大量参数。考虑到VRP变体的广泛范围,用有限的内存资源训练和存储许多重型模型是不现实的。一个理想的替代方案是,只存储问题特定的模块以及VRP的小型网络,它可以与主干(用于TSP)一起使用,以组装Transformer以解决问题。为此,本文提供了三种基于适配器的微调方法,即内部调优、侧调优和LoRA。对于每个下游VRP,只训练其问题特定的模块和小型适配器网络,同时冻结预训练骨干的参数。
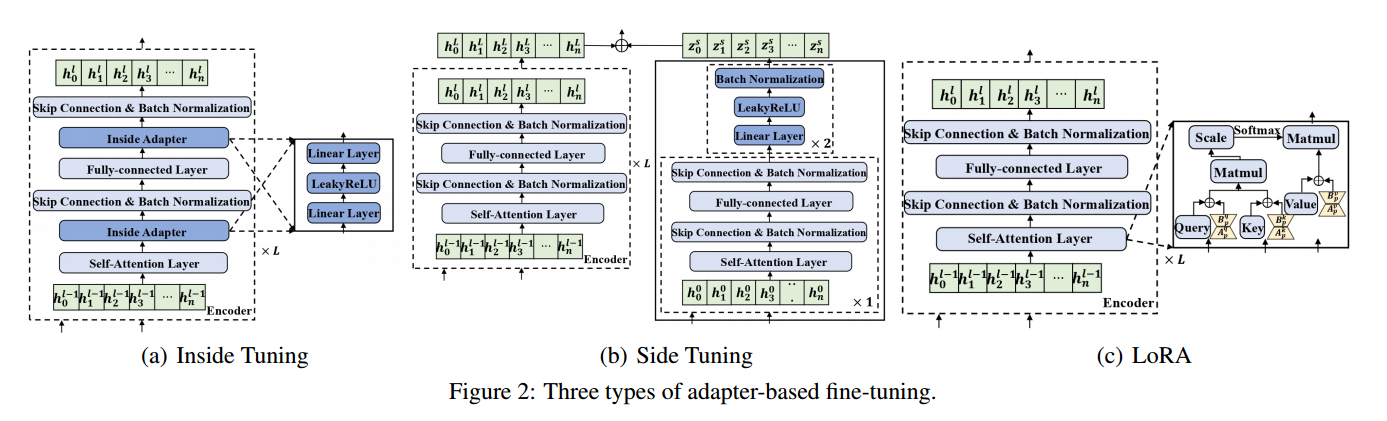
- 内部调优
适配器网络在内部调优中包含两个线性层,中间使用LeakyReLU(LR)激活函数,形式为:
\[\operatorname{APT}_{\text {in }}\left(h_i\right)=\mathbf{W}_1^{\mathrm{in}} \cdot \operatorname{LR}\left(\mathbf{W}_0^{\mathrm{in}} \cdot h_i+\mathbf{b}_0^{\mathrm{in}}\right)+\mathbf{b}_1^{\mathrm{in}},\]其中$i \in\lbrace 0, \ldots, n\rbrace$为节点索引。设置可训练参数$\mathbf{W}_0^{\text {in }} \in \mathbb{R}^{d \times(d / 2)};\mathbf{W}_1^{\text {in }} \in \mathbb{R}^{(d / 2) \times d};\mathbf{b}_0^{\text {in }} \in \mathbb{R}^{d / 2}$;$\mathbf{b}_1^{\text {in }} \in \mathbb{R}^d$,这些参数均匀初始化在范围$(-1 / \sqrt{d}, 1 / \sqrt{d})$。将上述适配器网络放置在自注意力层和全连接层之后,正如图2(a)所示。
- 侧向调优
侧向调优不是调整编码器中的中间嵌入,而是调整编码器的输出,神经架构如下:
\[\begin{gathered} h_i^{\prime}=\mathbf{B N}\left(h_i+\mathbf{M S L}_i\left(h_0, \ldots, h_n\right)\right), \\ h_i^{\prime \prime}=\mathbf{B N}\left(h_i^{\prime}+\mathbf{F L}\left(h_i^{\prime}\right)\right), \end{gathered}\] \[\mathrm{APT}_{\mathrm{si}}\left(h_i^{\prime \prime}\right)=\mathbf{B N}\left(\mathrm{LR}\left(\mathbf{W}_1^{\mathrm{si}} \cdot \mathbf{B N}\left(\mathbf{L R}\left(\mathbf{W}_0^{\mathrm{si}} \cdot h_i^{\prime \prime}+\mathbf{b}_0^{\mathrm{si}}\right)\right)+\mathbf{b}_1^{\mathrm{si}}\right)\right),\]其中$i \in\lbrace 0, \ldots, n\rbrace$为节点索引。在前两个公式中,在AM的编码器中使用类似的神经结构(执行一次而不是$L$次),通过多头自注意力层(MSL)和全连接层(FL)处理节点嵌入,之后跟随跳跃连接和批归一化(BN)。在后一个公式中,节点嵌入进一步通过线性层、LeakyReLU激活和批归一化演变,其中$\mathbf{W}_0^{\text {si }}, \mathbf{W}_1^{\text {si }} \in \mathbb{R}^{d \times d};\mathbf{b}_0^{\text {si }}, \mathbf{b}_1^{\text {si }} \in \mathbb{R}^d$是可训练参数,并且均匀初始化。该适配器网络位于编码器旁边,将初始节点嵌入$\left\lbrace h_i^0\right\rbrace_{i=0}^n$演变为$\left\lbrace z_i^s\right\rbrace_{i=0}^n$,这些嵌入被加到编码器的输出中(保持主干权重不变),如图2(b)所示。
LoRA
受到低秩适配(LoRA)启发,设计了一种低秩分解来调整预训练变换器中任何矩阵的输出,
\[\operatorname{APT}_{\mathrm{lo}}\left(h_i\right)=\mathbf{W}_p \cdot h_i+\mathbf{B}_p \mathbf{A}_p \cdot h_i\]其中$i \in\lbrace 0, \ldots, n\rbrace$为节点索引。$\mathbf{W}_p \in \mathbb{R}^{d \times d}$表示主干Transformer中用于TSP的预训练权重矩阵;$\mathbf{B}_p \in \mathbb{R}^{d \times r}$和$\mathbf{A}_p \in \mathbb{R}^{r \times d}$是两个可训练矩阵,$r=2 \ll d$,我们将其初始化为0和高斯分布$(0,1)$。应用公式来调整预训练Transformer编码器中查询、键和值矩阵的输出,如图2(c)所示。
实验
TSP:[0,1]x[0,1]均匀采样节点坐标
OP:奖励设置为1
PCTSP:从均匀分布中随机抽样奖励和惩罚
客户节点数量:20 50 100
100个epoch,每个epoch有2500个batch,每个batch有512个实例(100的时候256个实例),验证集10000个实例。
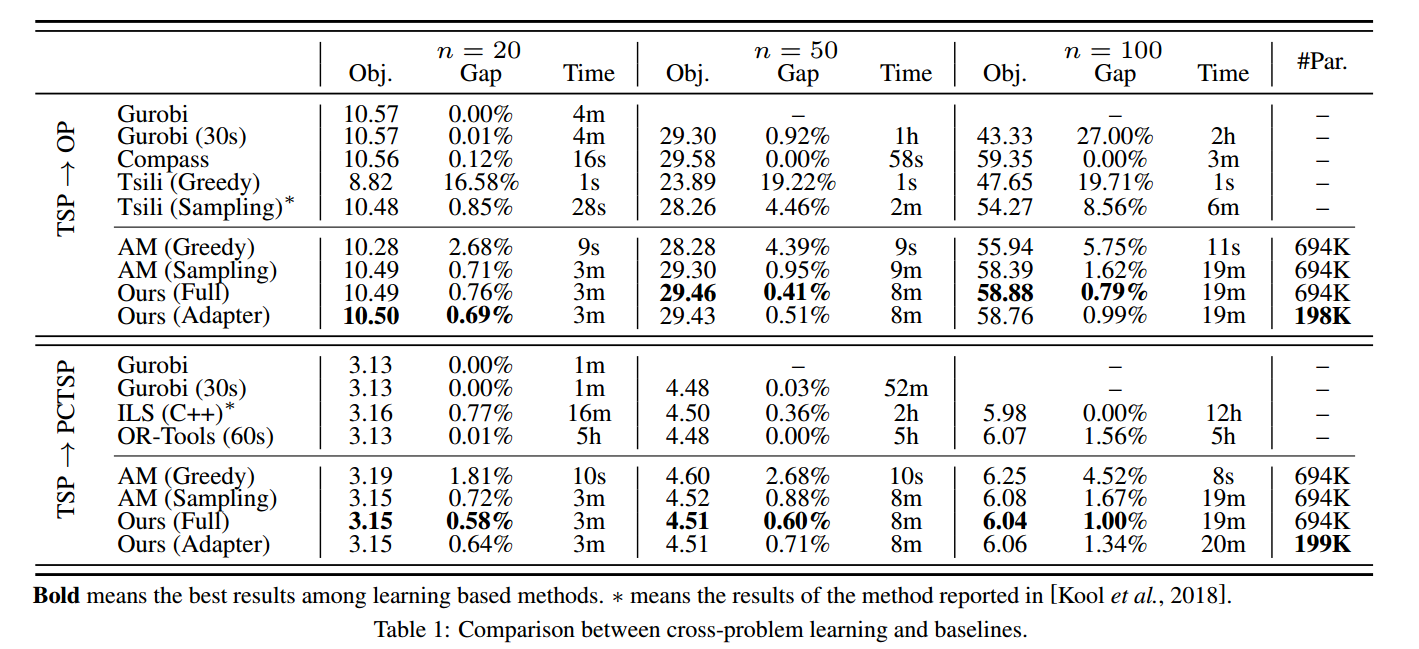
对比方法:AM、Gurobi、Compass(针对OP的专用遗传算法)、Tsili(一个经典的随机构造启发式算法,用于手动制作节点概率的OP)、ILS(迭代局部搜索元启发式算法,针对PCTSP)、OR-Tools(针对PCTSP)
对比
适配器微调只展示了内部调优,因为另外两种微调不行。
消融实验
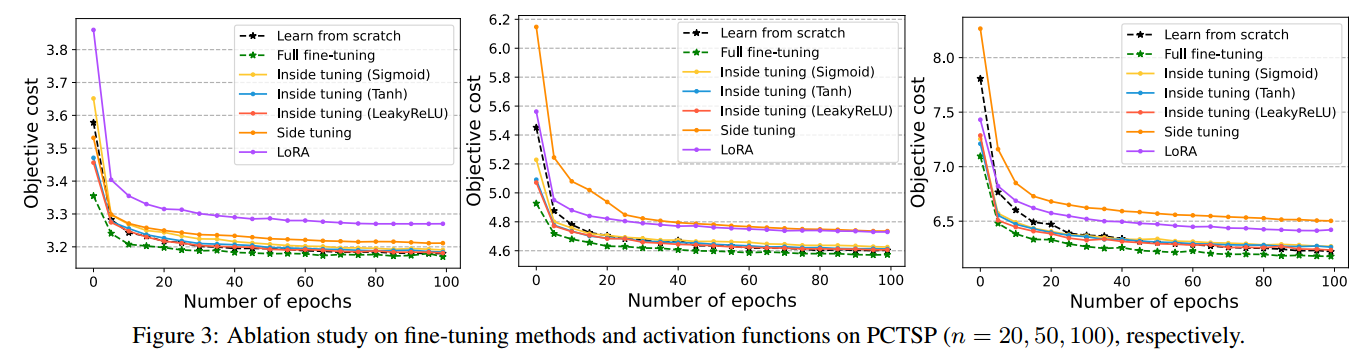
- 对比了三种适配器微调方式
- 改变激活函数(Sigmoid Tanh LeakyReLU)
Versatility
泛用性,我还是第一次看到这词。
将该方法部署到POMO上,100个epoch,每个epoch 10000个实例,batch size 为64。
x 8 aug 是实例增强。
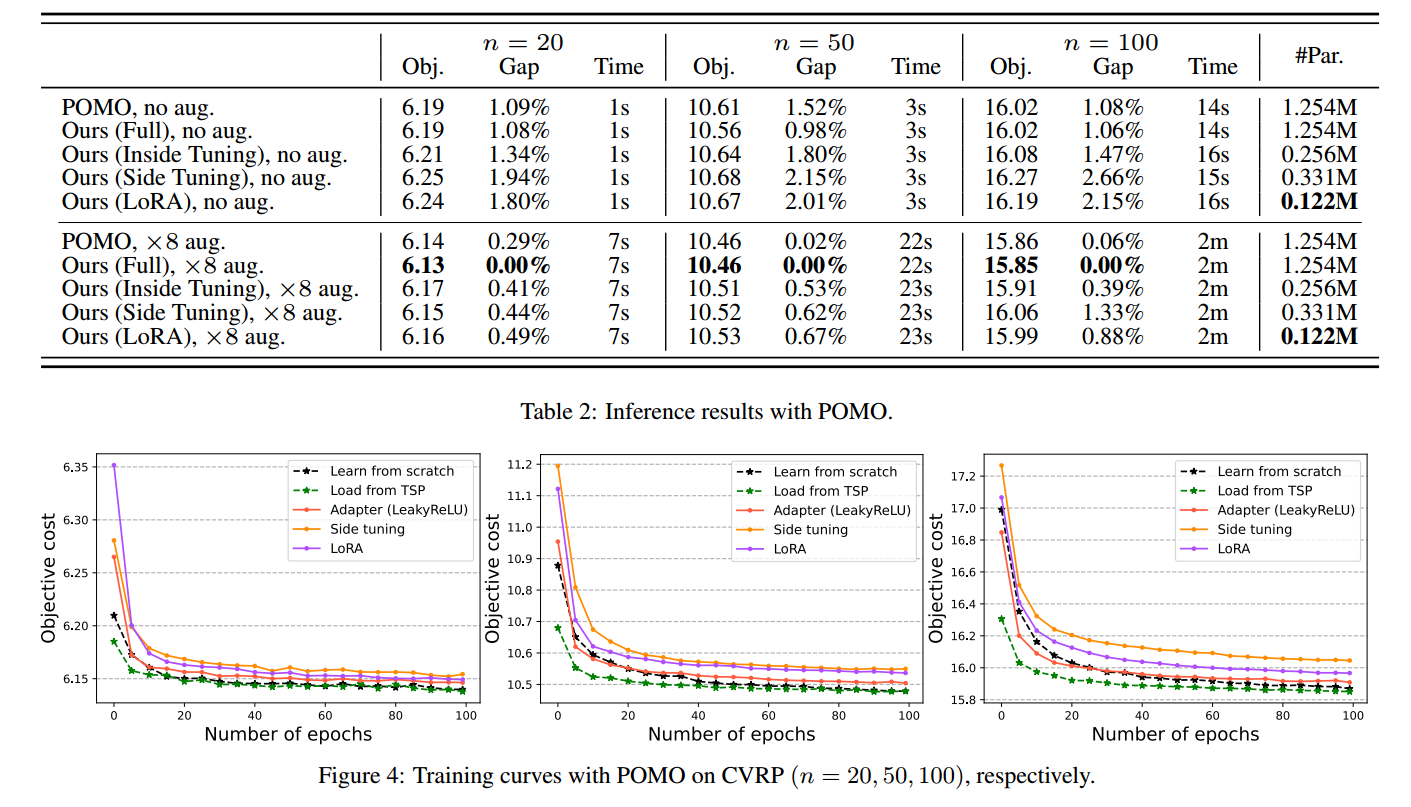
参数量减少更显著。
总结
结果表明,完全调优明显优于从头开始训练的Transformer,而基于适配器的调优提供了相当的性能,参数少得多。
在未来,将使用更先进的技术如神经结构搜索来改进方法,还计划将方法应用于解决其他cop问题,例如作业车间调度问题或垃圾箱包装问题。