GOAL: A Generalist Combinatorial Optimization Agent Learner
ICLR 2025
NAVER LABS Europe
代码: https://github.com/naver/goal-co/
摘要
最近,基于机器学习的启发式方法在解决各种困难的组合优化问题(COPs)时表现出了令人印象深刻的性能。然而,它们通常依赖于一个单独的神经模型,并针对每个问题进行专门训练。问题的任何变化都需要调整其模型,并从头开始重新训练。在本文中,我们提出了通用组合优化代理学习器 GOAL(Generalist combinatorial Optimization Agent Learner),这是一种通用模型,能够高效地解决多个 COP 问题,并可进行微调以解决新的 COP 问题。GOAL 由一个骨干网和用于输入和输出处理的轻量级特定问题适配器组成。主干系统基于一种新形式的混合注意力模块,可以处理节点、边缘和实例级特征任意组合的图上定义的问题。此外,涉及节点或边缘异构类型的问题可通过新颖的多类型转换器架构来处理,在该架构中,注意力模块是重复的,以便在依赖相同共享参数的情况下处理有意义的类型组合。我们在一组路由、调度和经典图问题上对 GOAL 进行了训练,结果表明,GOAL 的性能仅略逊于专业基线,同时也是首个能解决各种 COP 的多任务模型。最后,我们通过对几个新问题进行微调,展示了 GOAL 强大的迁移学习能力。
介绍
实验问题:
- 路由问题:非对称TSP、CVRP(TW)、OP
- 调度问题:JSP、非相关机器调度问题(UMSP)
- 包装问题:背包问题
- 图问题:最小顶点覆盖
很容易针对中等规模问题(100个节点)生成解。
通过实验:
- 在所有训练任务上表现很好
- 考虑了8个新的问题,证明可以在几分钟或几个小时内使用几次模仿学习或者无监督的情况下进行微调能够达到很好的效果
- 微调指的是从头开始训练模型所需的一小部分时间和数据
- 消融实验:评估共享codebook、多类型 Transformer 和混合注意力块的有效性
- 8个训练任务重有7个达到了 SOTA
贡献:
- GOAL:一个通用的、灵活的端到端组合优化模型。GOAL的两个关键组成部分是混合注意力模块,它可以处理由具有节点级、边缘级和实例级特征的任意组合的图表示的问题,以及它的多类型 Transformer 架构,它允许无缝地处理具有多部分图结构的问题。
- 证明了学习一个单一的骨干模型可以有效地解决各种CO任务,包括路由、调度、包装和图问题。
- 展示了这种多任务预训练模型的潜力,无论是否有监督,它都能有效地适应处理各种新的CO任务。
相关工作
- CO的端到端启发式学习
- 神经启发式的泛化
- 序列决策问题的多任务训练
组合优化的多任务学习
构造式CO求解器
使用 BQ-MDP。
多任务 CO 问题
由于每个任务都有自己的参数空间来表示其实例,任何多任务策略的某些部分必须是特定于任务的,并且通过处理每个任务的至少几个实例来训练:纯粹的零概率泛化是不可能的。
任务表征
因此,GOAL模型接收三个输入 $t, x, \bar{x}$,其中 $t$ 是任务标识符,而 $(x, \bar{x}) \in \boldsymbol{\Omega}_t$ 是一个参数,表示任务 $t$ 的一个实例,其中 $x \in \mathbb{R}^{N \times F_t}$(分别地,$\bar{x} \in \mathbb{R}^{N \times N \times \bar{F}_{\mathrm{r}}}$)表示 $N$ 个节点的 $F_t$ 维特征向量(分别地,$N \times N$ 条边的 $\bar{F}_t$ 维特征向量)。尽管某些任务可能没有边特征($\bar{F}_t=0$),但我们始终假设至少存在一个节点特征,通过在 0 到 1 之间随机分配值来区分节点,作为节点标识符,因此我们始终有 $F_t \geq 1$。$F_t$ 和 $\bar{F}_t$,以及相应特征的含义,均取决于任务 $t$。模型的输出是一个矩阵 $y \in \mathbb{R}^{N \times K_t}$,表示每个候选动作的得分,即节点与选择选项的配对。和通常一样,它被传递到 softmax(在整个矩阵上)以获得概率分布。在适当的情况下,可以使用任务依赖的掩码来确保任务禁止的动作的概率为零。
模型架构
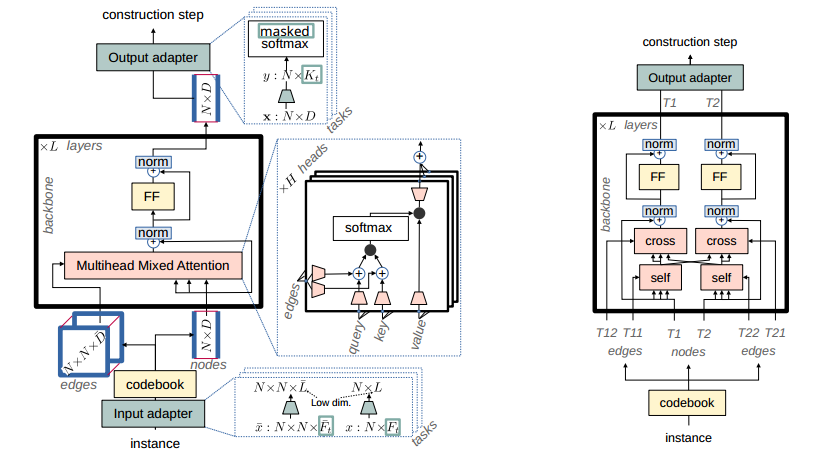
左:针对单一类型问题的GOAL架构;绿色组件是特定于任务的,而其他组件属于主干。密码本是一个共享的 $𝐿\times 𝐷(\bar{L}\times\bar{R})$ 矩阵应用到节点(边)。由输入适配器产生的边缘表示。
右:多类型问题的GOAL架构(这里有2个节点类型T1,T2);“self”和“cross”是相同的多头混合注意块(所有类型和任务的每层参数相同);两种类型的“FF”也是每层相同的前馈块。对于边,显示了所有类型组合(这里是T11,T12,T21,T22),但每个任务可以定义自己的类型组合。这两种体系结构使用相同的一组参数。
省流:实例通过一个低秩的适配器映射到一个空间中,密码本再映射到高维空间,然后点和边都进行注意力计算,并融合。
模型架构是对 BQNCO 的扩展,主要由一系列参数共享的层组成(称为主干网络),以及针对每个任务的输入和输出适配器模块。输入和输出适配器模块针对任务的特征维度(节点特征、边特征和实例特征)进行特定设计。模型中没有使用位置编码:所有关系信息都假设由边特征矩阵 $ \bar{x} $ 捕捉。
模型的主干部分由多层自注意力 Transformer 层组成,其中传统的自注意力模块被替换为多头混合注意力模块。
在一般情况下,混合注意力模块允许 $ N $ 个节点对 $ N’ $ 个节点进行注意力操作(仅当 $ N = N’ $ 时为自注意力)。这种混合注意力机制是一种广义注意力机制,其输入包括:节点表示作为查询向量、键向量和值向量,以及一个可选的 $ N \times N’ $ 的对数二进制掩码 $ M $。在每个头 $ h $ 中,查询、键和值向量首先被投影到一个维度为 $ d $ 的公共空间,得到每个 $ i = 1:N $ 和 $ j = 1:N’ $ 的向量(维度为 $ d $):
\[Q^{(h)}_i = Q_i W^{(h)}_Q, \quad K^{(h)}_j = K_j W^{(h)}_K, \quad V^{(h)}_j = V_j W^{(h)}_V\]然后,键向量和查询向量被用来计算一个 $ N \times N’ $ 的分数矩阵 $ S $,该矩阵经过掩码处理和 softmax 归一化后,乘以重新投影的值向量,以产生输出表示 $ Y $,维度为 $ N \times d $:
\[Y = \sum_{h} \text{softmax}_{\text{col}}(S^{(h)} + M)^\top V^{(h)}\]其中,不同的注意力机制在计算分数矩阵时有所不同:
-
传统注意力:
\[S^{(h)}_{ij} = \langle Q^{(h)}_i | K^{(h)}_j \rangle\] -
本文的混合注意力:
\[S^{(h)}_{ij} = \langle Q^{(h)}_i + E'^{(h)}_{ij} | K^{(h)}_j + E'^{(h)}_{ij} \rangle\]
在混合注意力中,额外输入了一个 $ N \times N’ $ 的“边”向量,这些向量被两次投影到维度为 $ d $ 的公共空间,分别作为键和查询向量,得到向量(维度为 $ d $):
\[E'^{(h)}_{ij} = E_{ij} W'^{(h)}_E, \quad E'^{(h)}_{ij} = E_{ij} W'^{(h)}_E\]分数矩阵仍然是通过键向量和查询向量的点积计算得到,但每个向量现在是节点部分和边部分的和。混合注意力机制允许将任意关系信息(边特征)直接融入注意力机制的核心部分。这与位置编码不同,位置编码试图将边信息(仅限于序列顺序)预先嵌入节点表示中。
在 GOAL 主干网络中,所有输入到注意力模块的节点(边)特征的维度为 $ d $($ \bar{d} $),它们都被投影到一个维度为 $ d’ $ 的公共空间中,其中 $ d’ $ 等于 $ d $ 除以头的数量。主干网络中不使用掩码。这种模型的一个已知限制是其二次复杂度,因为注意力矩阵的大小为 $ N^2 $。然而,在实际应用中,对于许多任务,可以通过简单的任务特定启发式方法(例如预过滤呈现给模型的节点集合)来解决这一问题。在可能的情况下,使用了这种启发式方法。
输入和输出适配器是线性投影模块,将任务特定的实例特征投影到主干网络的输入嵌入空间(维度为 $ d $)和从主干网络的输出嵌入空间投影到任务特定的动作空间。然而,当 $ d $ 很大且训练任务数量较小时,存在一种风险,即每个任务生成的嵌入可能会占据嵌入空间的互补子空间,从而无法有效地跨任务共享参数。为了避免这种情况,强制输入线性投影为低秩。具体来说,节点(分别地,边)特征首先被投影到一个“小”维度空间,迫使表示在任务之间共享维度,然后通过共享的码本(见图2左)将这个低维度表示嵌入到“大” $ d $-维度的嵌入空间中。
多类型 Transformer 架构
省流:适配器中,不同类型的点进行不同的编码后,进行交叉注意力,如右图,使得适配器能够区分不同类型的点。
许多任务(组合优化问题)涉及不同类型的节点。例如,调度问题通常涉及“操作”和“机器”节点。对于 GOAL,一种解决方案是简单地在主干网络中不加区分地处理它们。适配器是任务特定的,当然可以自由地根据节点类型进行不同的处理。然而,这有时是不太好,因为它使适配器为所有节点和边提供统一的嵌入,尽管它们本质上是异质的:在调度问题的例子中,边特征可能在操作之间携带优先级约束,或在机器和操作之间携带处理时间,而在机器之间则没有任何信息。
与其将这些不同类型的关系打包到一个单一向量中,并在未定义特征的地方填充填充值,本文提出了一种多类型架构,适配器为每种类型(节点)或兼容类型对(边)输出单独的嵌入。模型的每一层不再是操作所有节点的单一自注意力块,而是根据任务特定的配置,由跨不同类型兼容子集的节点和边的交叉注意力和自注意力块组成。这在图(右)中进行了说明。因此,在我们的调度问题示例中,模型将包含分别针对操作节点和机器节点的自注意力块,以及针对操作-机器边和反之亦然的交叉注意力块。注意,尽管架构配置现在是任务特定的,但模型参数对于所有配置都是相同的:一层中的所有注意力块,无论是自注意力还是交叉注意力,无论它们涉及的类型如何,都共享相同的、层特定的参数。这正是我们能够训练一个独特的模型来解决任意单类型或多类型问题的原因。
实验
探究
- 是否能够学习单一主干,使得其能解决各种CO问题
- 是否可以用作预训练模型,并通过有效微调来训练未见过的CO问题
- 混合注意力模块和多类型架构的贡献有多少
训练任务:
-
8个经典问题,每个问题100万个随机实例,并使用传统求解器
- 非对称旅行商问题(ATSP) (LKH),有能力车辆路线问题(CVRP) (LKH),有时间窗口的有能力车辆路线问题(CVRPTW) (HGS),定向问题(OP) (A4OP),背包问题(KP) (ORTools),最小顶点覆盖问题(MVC) (FastWVC),无关机器调度问题(UMSP) (high)和作业车间调度问题(JSSP) (ORTools)
- 实例节点规模100,JSSP为10x10,UMSP为100x20
训练过程
- 8个V100,batch为256,训练7天,400个epoch
- 验证集大小128
baseline
- 神经构造方法:AM、MDAM、POMO、Sym-NCO、BQ-NCO、MVMoE、MatNet、S2V-DQN、COMPASS
- 测试时使用greedy
训练任务上的表现
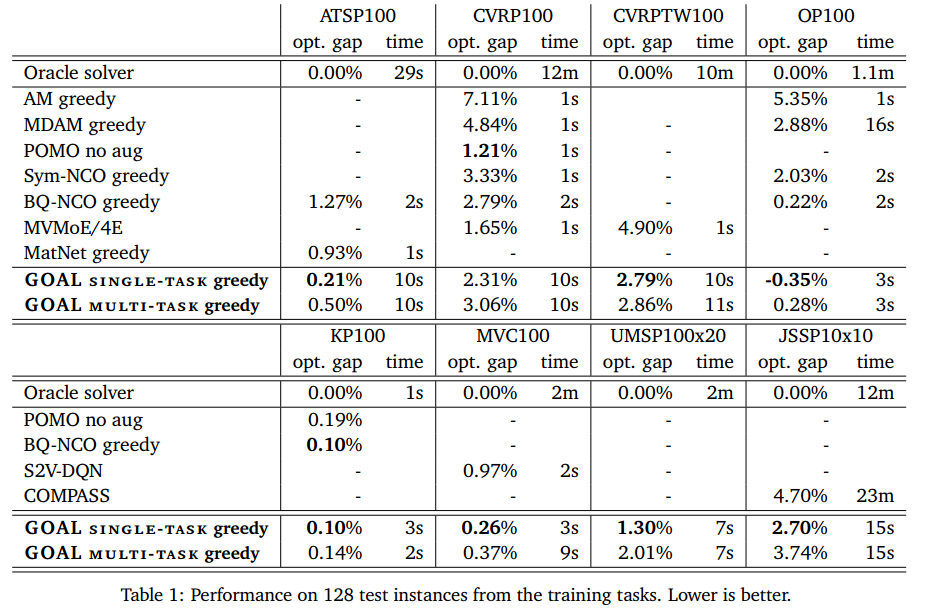
附录实验中,GOAL在比训练实例大10倍的实例上具有出色的zero-shot泛化。
新任务微调
8种新的COP:旅行修理工问题(TRP),奖品收集TSP (PCTSP),开放CVRP (OCVRP),分离交付CVRP (SDCVRP),顺序排序问题(SOP),最大覆盖位置问题(MCLP),最大独立集(MIS)问题和开放车间调度问题(OSSP)。
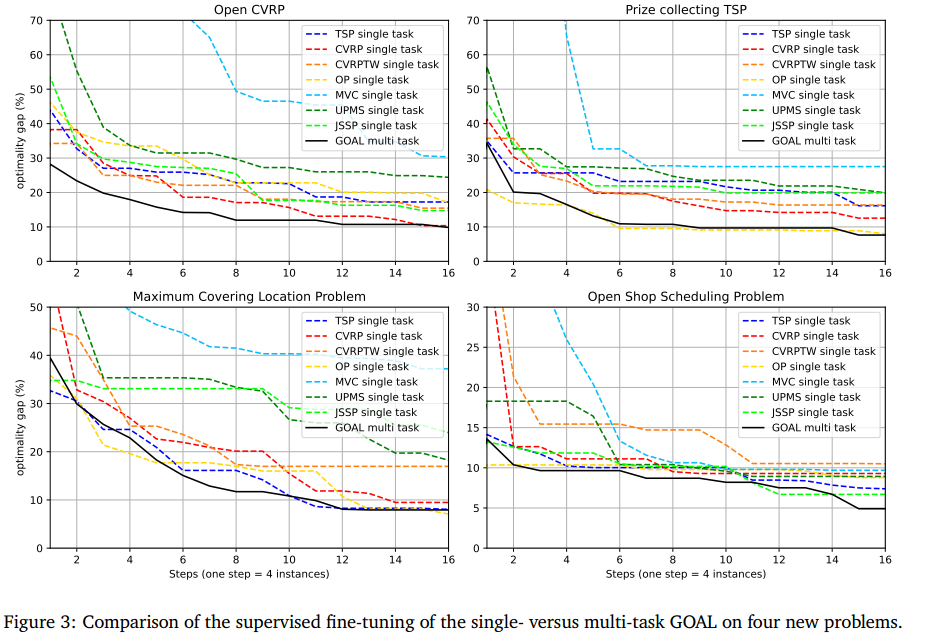
在四个新问题上,单任务和多任务GOAL的监督微调比较:
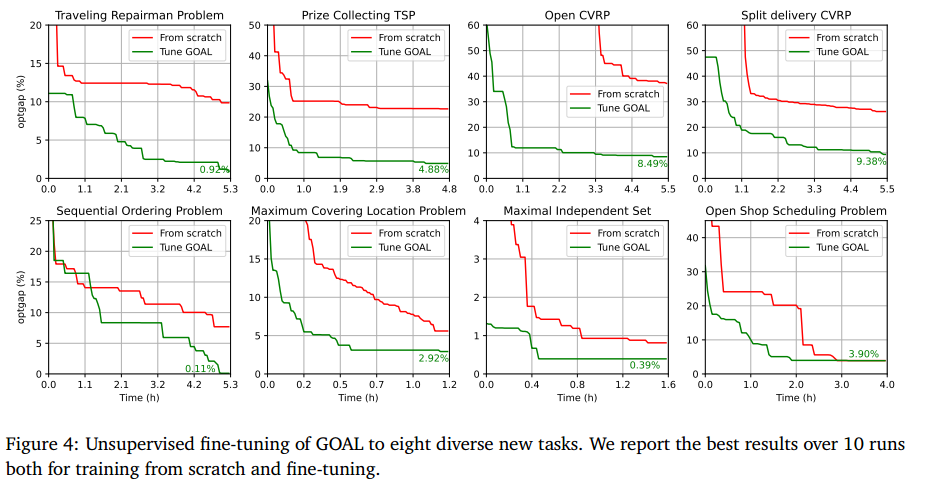
无监督微调目标到八个不同的新任务:
消融实验
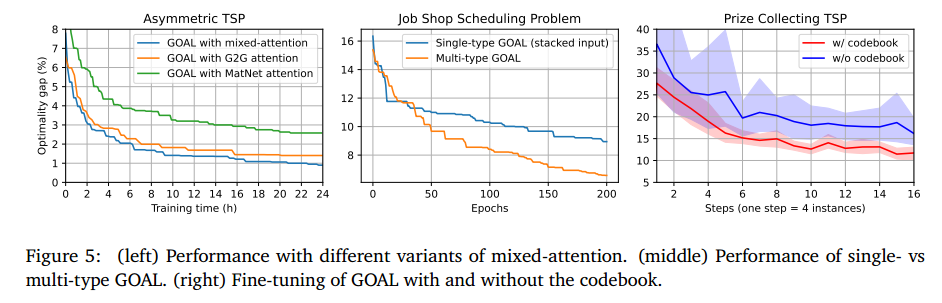
- 左图消融了混合注意力模块
- 中图是单任务GOAL和多任务的对比
- 右图是有无密码本的微调
讨论和总结
优点:
- 一个单任务专用模型,在七个CO问题上提供最先进的结果
- 多任务模式,可以用同一个骨干解决不同的问题
- 预训练模型,该模型可以有效地对新问题进行微调
局限:
- 无法处理复杂约束
- Transformer的二次复杂度使其处理超过1000个节点的实例成本太高