Boosting Neural Combinatorial Optimization for Large-Scale Vehicle Routing Problems
ICLR 2025
南方科技大学 王振坤课题组
超大规模TSP(100,000)
开源:https://github.com/CIAM-Group/SIL
摘要
神经组合优化(NCO)方法在求解车辆路径问题(VRPs)中表现出了良好的性能。然而,大多数NCO方法依赖于传统的自关注机制,导致计算复杂度过高,难以应对大规模VRP,阻碍了其实际应用。在本文中,我们提出了一种具有线性复杂性的轻量级交叉注意机制,通过该机制开发了Transformer网络,以学习大规模VRP的有效和有利的解决方案。我们还提出了一种自我改进训练(SIT)算法,该算法可以在大规模VRP实例上直接进行模型训练,从而绕过获取标签的大量计算开销。通过迭代解重构,Transformer网络本身可以生成改进的部分解作为伪标签来指导模型训练。在100,000个节点的旅行推销员问题(TSP)和有能力车辆路线问题(CVRP)上的实验结果表明,我们的方法在合成基准和现实基准上都取得了卓越的性能,显著提高了NCO方法的可扩展性。
介绍
本文提出了一种具有线性计算复杂度的轻量级交叉注意机制,可以显著提高NCO模型求解大规模VRP的效率。
与传统的自注意力使每个节点关注实例中的所有其他节点不同,交叉关注通过代表性节点改革计算过程。特别是,代表性节点首先关注实例的每个节点来更新自己的嵌入,然后通过关注代表性节点来更新实例节点的嵌入。在固定数量的代表性节点下,相对于传统的自注意算法,在保持节点间有效注意计算的同时,大大降低了计算复杂度。
基于所提出的交叉注意机制,开发了一种新的Transformer网络,以更有效地解决大规模VRP。此外,提出了一种创新的自我改进训练(Self-Improved Training, SIT)算法,使模型能够在大规模实例上成功训练。
相关工作
基于泛化的方法
基于泛化的方法通常是在小规模的实例上训练神经模型,然后在相同规模或更大规模的实例上进行测试。它一般是指基于构造的方法,通过学习一个模型,以自回归的方式为给定的问题实例构造近似解。
- AM、各种POMO改进、SL、BQ-NCO、LEHD
基于简化的方法
一些方法通过分解或学习局部策略来简化大规模VRP。
基于热图的方法
这种方法首先建立一个图神经网络(GNN)模型来预测一个热图,该热图测量每条边在最优解中的概率,然后使用热图迭代搜索一个近似解。
前序知识
- VRP的定义
- VRP解的构造
- 自注意力机制
方法论
轻量级交叉注意力
传统的自注意机制是 $O(n^2)$ 复杂度的。
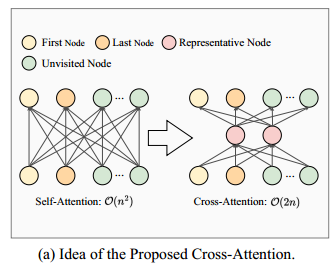
如上图,在注意力计算中使用了两个代表性节点。两个代表性节点首先根据它们与实例中所有节点之间的关注程度更新它们的嵌入。随后,通过对代表性节点进行关注计算来更新实例的节点嵌入。与自关注相比,这种交叉关注的复杂度为 $O(nm)$,其中 $m$ 为代表性节点的数量。由于通过代表性节点传播节点嵌入,交叉注意机制在保持节点之间有效交互的同时实现了低复杂度。
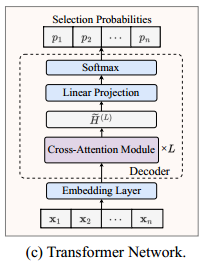
Transformer 架构
网络由单个嵌入层和一个解码器组成,解码器具有 $L$ 个堆叠的交叉关注模块。
-
嵌入层:一个线性层
-
交叉注意力模块解码器
-
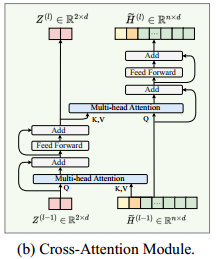
在解码的第 $t$ 步,选择当前部分解的第一个和最后一个节点作为代表节点
-
-
第一个节点和最后一个节点的嵌入记为 $h_{\pi_1},h_{\pi_{t-1}}$,未访问的节点记为 $H_a^t$
-
在第一步的时候随机选择一个节点最为第一个和最后一个节点
-
第 $t$ 步的代表性节点嵌入 $Z^{(0)}$ 和图节点嵌入 $\widetilde{H}^{(0)}$
\[\begin{aligned} Z^{(0)} & =\left[\mathbf{h}_{\pi_1} W_1, \mathbf{h}_{\pi_{t-1}} W_2\right] \\ \tilde{H}^{(0)} & =\left[\mathbf{h}_{\pi_1} W_1, \mathbf{h}_{\pi_{t-1}} W_2, H_a^t\right] \end{aligned}\] -
接下来会经过 $L$ 层注意力模块,在第 $l$ 个交叉注意力模块中,首先让代表性节点对图节点嵌入 $\widetilde{H}^{(l-1)}$ 进行注意力操作以更新代表性节点嵌入,即
\[\begin{aligned} & \hat{Z}^{(l)}=\operatorname{Attn}\left(Z^{(l-1)}, \tilde{H}^{(l-1)}\right)+Z^{(l-1)} \\ & Z^{(l)}=\operatorname{FF}\left(\hat{Z}^{(l)}\right)+\hat{Z}^{(l)} \end{aligned}\] -
随后,图节点嵌入 $\widetilde{H}^{(l-1)}$ 对代表性节点进行注意力操作以更新其嵌入,即
\[\begin{aligned} \hat{H}^{(l)} & =\operatorname{Attn}\left(\widetilde{H}^{(l-1)}, Z^{(l)}\right)+\widetilde{H}^{(l-1)} \\ \widetilde{H}^{(l)} & =\operatorname{FF}\left(\hat{H}^{(l)}\right)+\hat{H}^{(l)} \end{aligned}\] -
最后对未访问节点嵌入应用线性投影和 softmax,已生成选择每个未访问节点的概率,即
\[\begin{aligned} & u_i= \begin{cases}\widetilde{\mathbf{h}}_i^{(L)} W_O, & i \notin\left\{\pi_{1: t-1}\right\} \\ -\infty, & \text { otherwise }\end{cases} \\ & \mathbf{p}=\operatorname{softmax}(\mathbf{u}) \end{aligned}\]
-
复杂度分析
$O(2\widetilde{n})$,其中 $\tilde{n}$ 为输入到解码器的点数。
自提升训练
基于构造的NCO模型在解码中表现出偏差,其中起始节点、目标节点和方向的变化可能导致截然不同的解决方案。得益于这种偏差,模型可以通过迭代局部重建直至收敛,逐步提高解的质量。
然而,目前的局部重建技术仍然依赖于SL或RL,由于标签的稀缺性或奖励的稀缺性,阻碍了它们对大规模VRP的适用性。相反,本文提出了一种自我改进训练(SIT)算法,专门用于局部重建,以便更有效地探索大规模VRP的解。
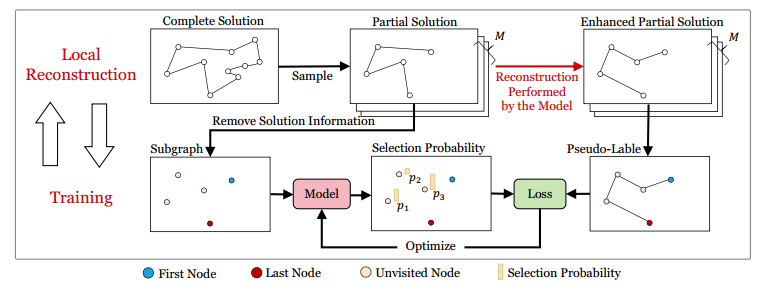
局部重构
在解中采样长度至少为 4 的局部解,第一个节点和最后一个节点固定,中间的解重新构造,将生成的解与原解比较。
模型训练
来自局部重建的增强解作为伪标签,以监督的方式训练模型。
对于大规模VRP实例,由于大量GPU内存的使用,构造完整解很困难。为了解决这个问题,将模型的学习范围限制在解决方案的局部部分。
在每次迭代中,神经模型进行多次局部重构(并行)以提高解的质量,然后使用增强的部分解作为伪标签来训练模型以提高其性能。
实验
数据集
- 5个随机合成数据集:1k、5k、10k、50k、100k
- 1k的测试集大小128,其他是16
- TSP使用LKH3,CVRP使用HGS
- 标准数据集:TSPLIB、CVRPLIB,EUC_2D 特征,超过 1k 的实例,共33个TSP和14个CVRP
模型设置和训练
- 嵌入维度 128,注意力层数 6,注意力头数 8,隐藏层维度 512
- 随机插入生成的伪标签在 1k 规模实例上进行热身
- 1k、5k/10k、50k/100k 的数据集大小分别为 20k、200、100
- SIT中局部解最大长度 1000
- 单个 RTX 3090,24GB内存
baseline
- 经典求解器:LKH3、Concorde、HGS
- 插入启发式:随机插入
- 构造NCO:POMO、BQ、LEHD、INViT、SIGD
- 基于热图:DIFUSCO
- 基于分解:GLOP、H-TSP
- 基于局部策略:ELG
比较结果
RPC:并行局部重构,Parallel local ReConstruction
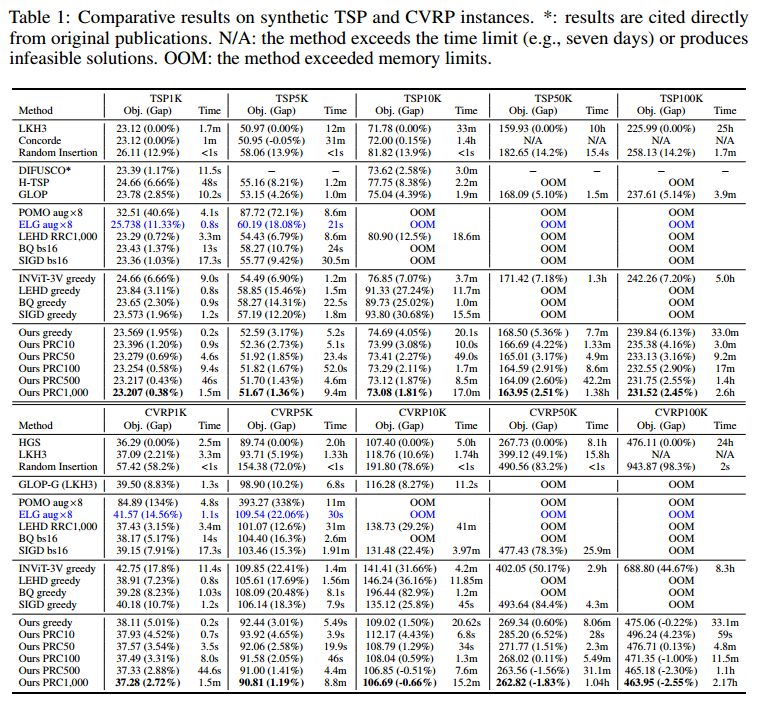
- 使用 Greedy 的时候,明显其他也是用 Greedy 的构造NCO,无论是求解质量还是速度
- 只使用 50 次PRC,在除了 CVPR 1k 的其他数据集上,优于其他所有学习方法
在标准数据集上,不使用 PRC 大部分都更好,使用后全部更好。
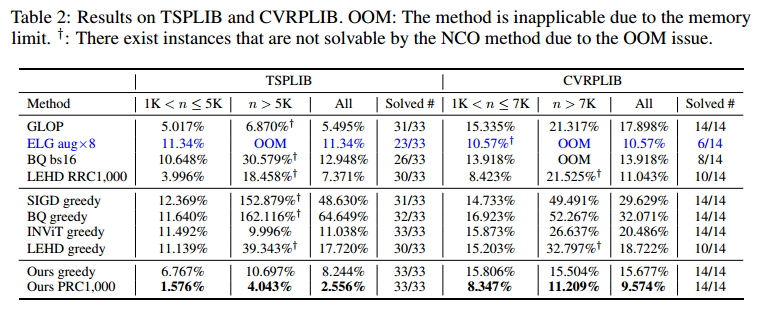
消融实验

SIT 提升质量,交叉注意力提速和降低内存使用。
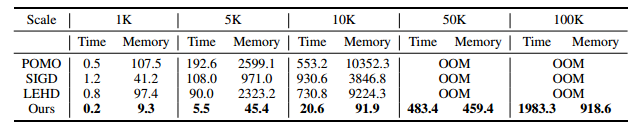
额外的实验
效率分析(求解时间和使用内存)
敏感性分析:局部解的长度上限 1000 比 10000 更好。
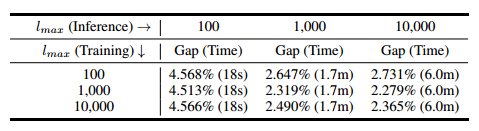
直观地说,学习构造过长的解会压倒模型的能力,这使得通过有限数量的交叉注意计算来学习有利的表示变得困难。另一方面,设置为较小的值会导致过度的局部策略并牺牲全局性能。因此,设置为一个中间值1000,以平衡训练和推理性能。
附录
迭代重构的复杂度分析
$O(kl_{max}^2)$,$k$ 是迭代次数,$l_{max}$ 是局部解的长度。
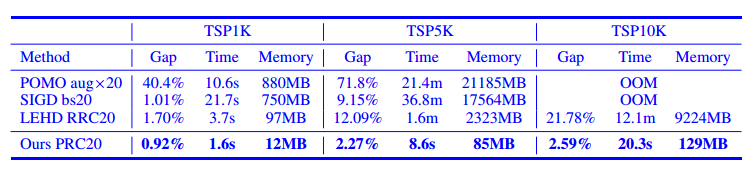
值得注意的是,许多NCO方法(包括本文)采用后搜索或迭代推理来换取更多的计算时间以获得更好的准确性。为了全面说明本文方法在计算效率上的优势,将其与三种具有代表性的NCO方法(即POMO, LEHD和SIGD)分别在单轮(贪婪搜索)和多轮推理下进行了比较。在多轮推理下,按照他们的论文建议,对POMO使用augmentation (aug),对LEHD使用random reconstruction (RRC),对SIGD使用beam search (bs),每轮操作20轮。
单轮推理结果
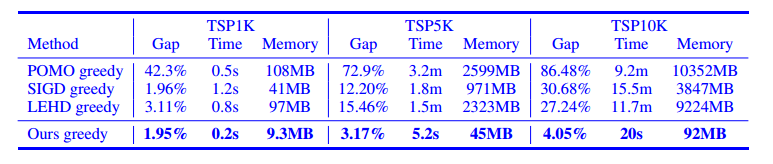
多轮推理结果
CVRP实现细节
问题设置
一个解 $\lbrace 0,1,2,3,0,4,5,0,6,7,0,8,9,10\rbrace$ 记为
\[1 \quad 2 \quad 3 \quad 4 \quad 5 \quad 6 \quad 7 \quad 8 \quad 9 \quad 10 \\ 1 \quad 0 \quad 0 \quad 1 \quad 0 \quad 1 \quad 0 \quad 1 \quad 0 \quad 0 \\\]其中第一行显示访问的节点序列,而第二行表示是否通过仓库或其他客户节点访问每个节点。
Transformer 网络
略
复杂度分析
同 TSP。
容量约束
两个措施
- 排除尾部子线路。如果在局部解决方案结束时的子线路没有在仓库结束,它将不参与重建过程。
- 初始容量计算。当部分解的头部节点不是仓库时,车辆的初始容量由原完整解中该头部节点与其前一个车辆段之间节点的总需求减去满载容量决定。
代表节点的选择
其他选项:
- 池化节点:所有节点的嵌入的平均
- 可学习节点:学习两个嵌入
这些方法在训练过程中有不确定性,训练早起的损失变成 NaN。
在求解VRP时,最后一个节点被动态更新为上一步选择的节点,未访问节点数量减少。这种调整不断地改变第一个、最后一个和未访问节点之间的关系。代表性节点必须在每个步骤中准确地反映这些更改。然而,池化节点或可学习节点无法实现这一点。相反,第一个和最后一个节点本质上表示动态变化的信息,因此更适合作为代表性节点。
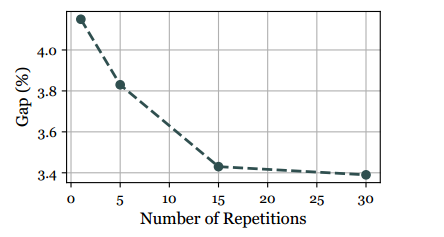
本文探索了增强模型对最后一个节点信息感知的策略,以提高模型的学习能力。在代表性节点中多次重复最后一个节点,并使用两次SIT迭代在TSP1K实例上进行模型训练。相应模型的最优性差与重复最后一个节点的数量的关系如图所示。可以发现,在重复次数和性能增益之间存在正相关关系。而且,随着重复次数的增加,增量收益越来越小,特别是当重复次数大于15次时。此外,增加代表性节点的数量会导致额外的计算开销。考虑到这些因素,在实验中使用15来平衡性能改进和资源效率。
伪代码

训练设置
初始方法对 PRC 的影响
贪心、最邻近插入、启发式随机插入:贪心是最快的
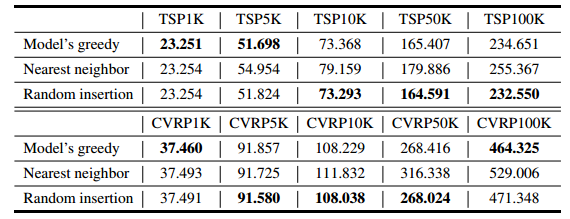
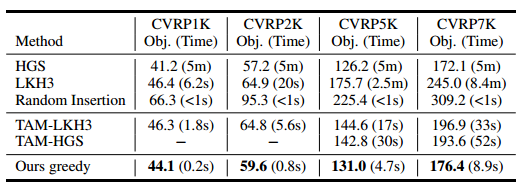
与TAM的比较
TAM 没有开源,直接比较论文
小规模实例结果
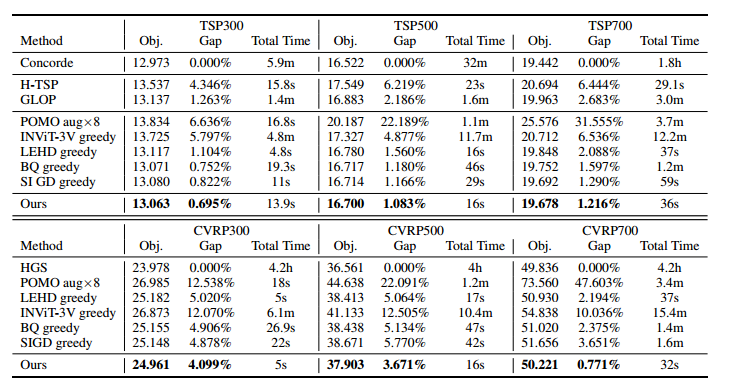
300 的时候推理时间更长些,但效果更好。
可扩展性
在 BQ 中加入 SIT 和交叉注意力。
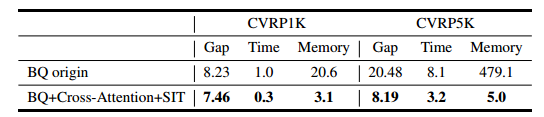
没有在大规模上直接训练的讨论
- 对于使用监督学习进行模型训练的NCO方法,很难获得足够的标记数据(即,具有如此大规模的问题实例的最优解)。
- 对于基于强化学习的NCO方法,过多的GPU内存开销使其无法使用如此大规模的问题实例进行模型训练。
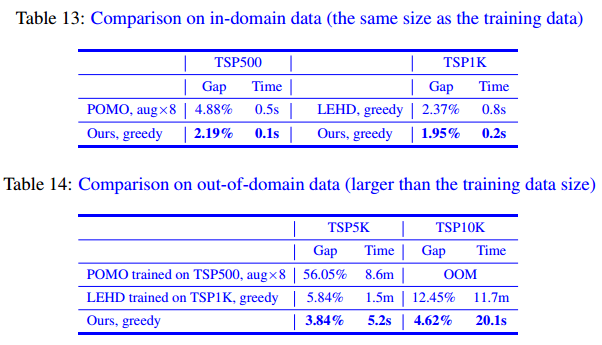
本文的方法比在大规模上直接训练的 POMO 和 LEHD 更好。
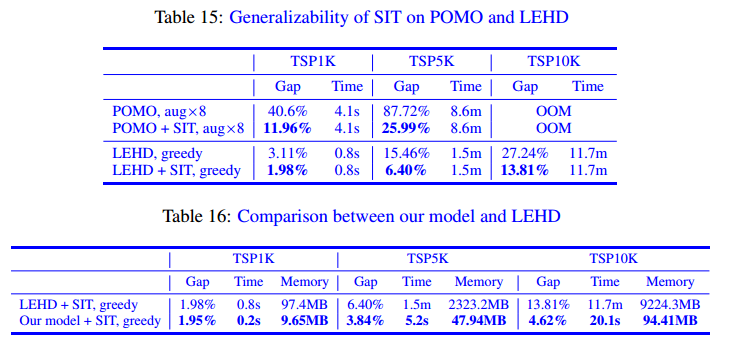
交叉注意力的有效性和普适性
在 POMO 和 LEHD 上应用 SIT,探究交叉注意力的效果。
与NeuroLKH的比较
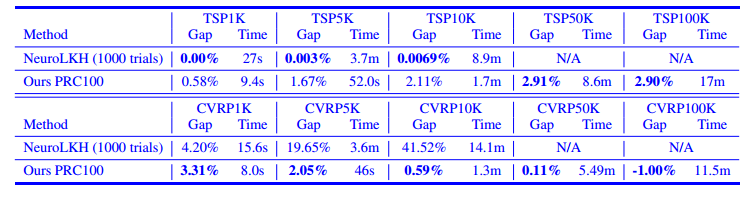
NeuroLKH 在 1k/5k/10k 上表现更好,但更大规模由于奇异值或内存不足问题,无法解决。