ICLR 2026 review阶段,LLM AHD合集二
Fusing LLMs with Scientific Literature for Heuristic Discovery
https://openreview.net/forum?id=lwqeXDYKWJ
rating:4444, Reject
核心思想
让大语言模型(LLM)在进化算法中“查文献”,从而突破自身知识边界,自动设计出更强、更专业的启发式算法。
痛点与动机
- LLM擅长写代码,但在设计高性能、领域专用的启发式算法时,受限于其静态、通用训练知识。
- 进化算法(EC)能探索巨大搜索空间,但传统方法依赖人工设计组件,创新受限。
- 关键问题:如何让LLM在算法设计过程中主动获取并整合最新、领域相关的科学知识?
贡献
- 提出KA-EAD,首次将科学文献动态检索融入LLM驱动的进化算法设计流程。
- 把LLM的“内部反思”转化为主动知识查询,实现“卡壳时查论文”的类人行为。
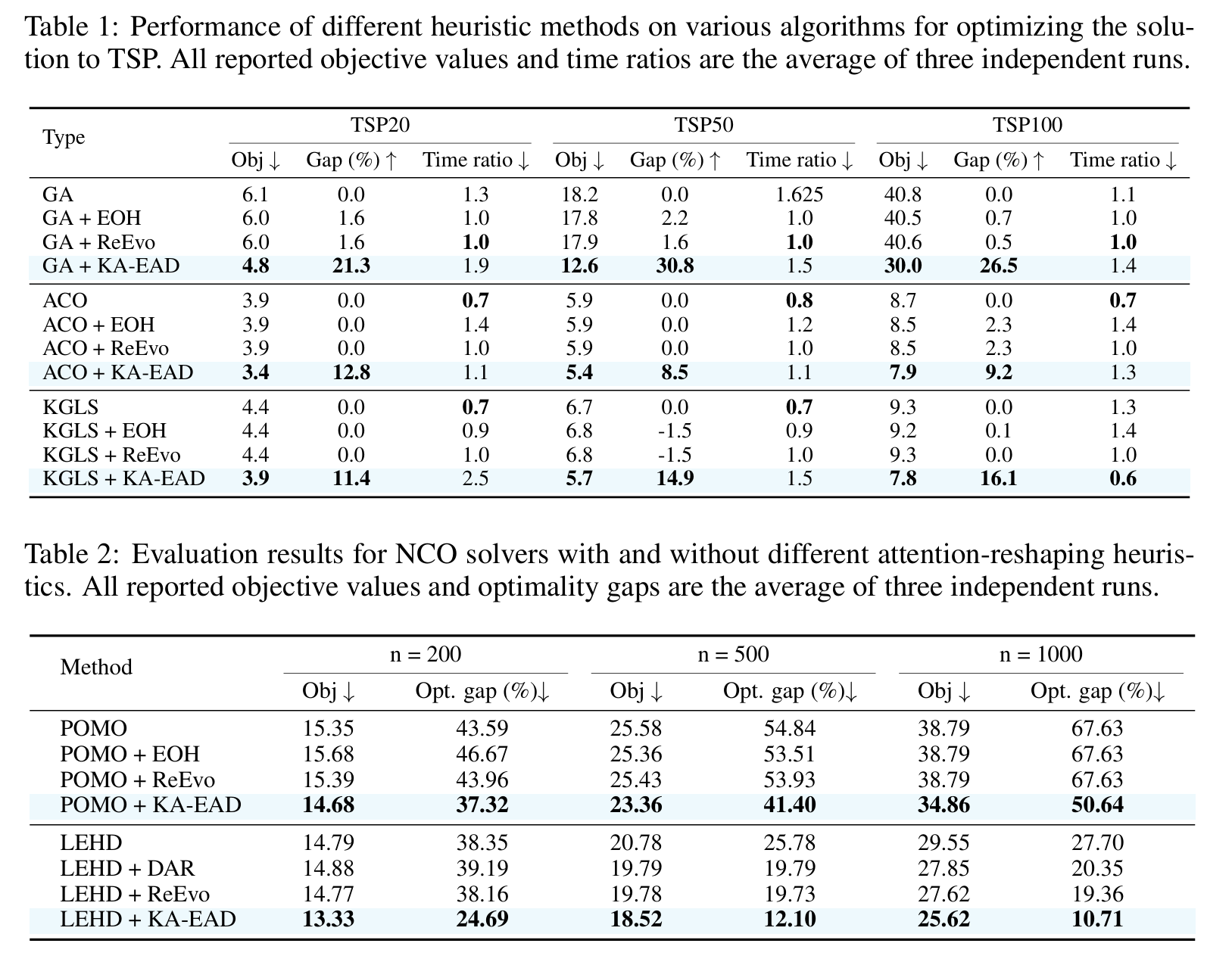
- 在经典算法(GA、ACO、KGLS)和神经组合优化器(POMO、LEHD)上均取得显著性能提升,如LEHD在TSP1000上的最优性差距从27.70%降至10.71%。
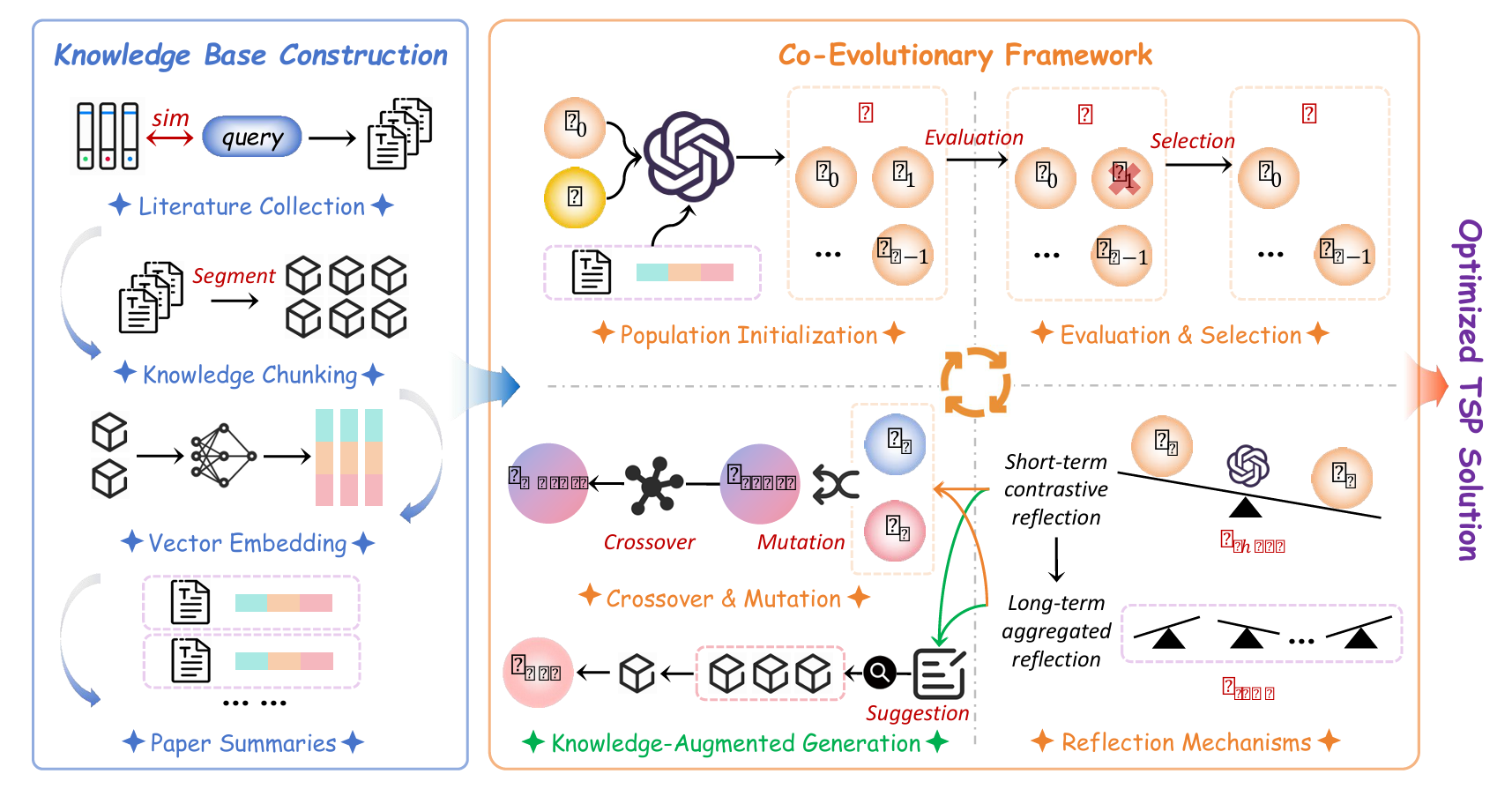
方法
知识库构建与增强
文献语料筛选
- 用关键词(如“Traveling Salesman Problem”、“Ant Colony Optimization”、“heuristic design”)从学术数据库获得候选文档集。
- 采用句子嵌入模型$E_{\mathrm{sent}}$(例如
all-MiniLM-L6-v2)分别对文档摘要与任务自然语言描述$\mathrm{desc}(\mathcal{P})$编码。 -
保留余弦相似度高于阈值$\theta_{\mathrm{corpus}}$的文档,构成领域语料
\[C_{\mathrm{lit}}=\lbrace d_{i}\mid\operatorname{sim}(E_{\mathrm{sent}}(\mathrm{abstract}(d_{i})),\;E_{\mathrm{sent}}(\mathrm{desc}(\mathcal{P})))>\theta_{\mathrm{corpus}}\rbrace\]
知识分块、嵌入与索引
- 提取每篇文档全文$T_i$。
- 使用分词器Tok(同嵌入模型)将$T_i$切分为长度约$L_{\mathrm{chunk}}$(如512)token的语义连贯块$\kappa_{i,j}$。
-
所有块组成可检索知识库
\[\mathcal{K}_{\mathrm{chunk}}=\bigcup_{i,j}\lbrace \kappa_{i,j}\rbrace\] - 用嵌入模型$E_{\mathrm{chunk}}$将每个块$\kappa$映射为向量$v_{\kappa}=E_{\mathrm{chunk}}(\kappa)\in\mathbb{R}^{d}$。
- 采用FAISS构建可快速k-NN搜索的向量索引$\mathcal{I}_{K}$。
知识增强进化算法
算法维护一个种群$Pop_t=\lbrace s_1,\dots,s_M\rbrace $,每个个体$s_k$主要由其源代码$c_k$定义。流程如下:
初始种群生成
- 生成器LLM$LLM_{\mathrm{gen}}$接收系统提示、任务描述$\pi_{\mathrm{seed}}$、长程反思$\rho_{\mathrm{LT},0}$(初始为空)以及从$\mathcal{K}_{\mathrm{chunk}}$提炼出的摘要$\mathrm{Summ}(\mathcal{K}_{\mathrm{chunk}})$。
- 通过升温采样(temperature $\tau_{\mathrm{init}}$稍高)生成$M$段不同代码$\lbrace c_1,\dots,c_M\rbrace $,实例化为$Pop_0$。
- 在环境$E$中执行得初始适应度$f(s_k)$。
进化算子与主循环
每代$t>0$依次执行:
- 选择(Selection):按适应度$f(s)$做锦标赛选择,得父代种群$Pop’_{t-1}$。
- 反思(Reflection):
- 用$LLM_{\mathrm{reflect}}$比较一对优/劣个体$(s_{\mathrm{better}},s_{\mathrm{worse}})$,输出短期反思$\rho_{\mathrm{ST},t}$。
- 更新长期反思$\rho_{\mathrm{LT},t}\leftarrow\rho_{\mathrm{LT},t-1}\oplus\rho_{\mathrm{ST},t}$。
- 标准变异(Standard Variation):交叉/变异算子作用于$Pop’_{t-1}$,可受$\rho_{\mathrm{ST},t}$引导,产生子代$Pop_{\mathrm{var},t}$。
- 知识增强生成算子(RAG-Operator)——核心创新:
- 查询构造(Query Formulation) 由$LLM_{\mathrm{query}}$把$\rho_{\mathrm{ST},t},\rho_{\mathrm{LT},t}$与问题焦点综合为自然语言查询$q_{\mathrm{RAG}}$。
- 知识检索(Knowledge Retrieval)
- 将$q_{\mathrm{RAG}}$嵌入为$v_q=E_{\mathrm{chunk}}(q_{\mathrm{RAG}})$。
-
在索引$\mathcal{I}_{K}$中做$k_{\mathrm{ret}}$-近邻搜索,返回最相关块集合
\[\mathcal{K}_{\mathrm{retrieved}}=\lbrace \kappa_{j}\mid\kappa_{j}=\mathrm{NN}_{j}(\mathcal{I}_{K},v_q),\;j=1,\dots,k_{\mathrm{ret}}\rbrace\]
- 增强生成(Augmented Generation)
- 构造提示$\mathrm{prompt}_{\mathrm{RAG}}$,内含: – 任务签名与类型/张量约束 – 检索到的知识$\mathcal{K}_{\mathrm{retrieved}}$ – 改进建议(可为$q_{\mathrm{RAG}}$本身)
- $LLM_{\mathrm{gen}}$据此生成新代码种群$Pop_{\mathrm{RAG},t}$;若编译/语义错误,则迭代重提示直至通过。
- 评估与种群更新(Evaluation, Population Update, Termination)
- 合并$Pop_{t-1}\cup Pop_{\mathrm{var},t}\cup Pop_{\mathrm{RAG},t}$,评估所有新个体。
- 按适应度选最优$M$个组成下一代$Pop_t$(精英保留)。
- 当函数评估次数$FE\geq FE_{\max}$、适应度收敛或时间到,终止并返回最优$s^*$。
实验
审稿人意见
这就是RAG。
Adversarial examples for heuristics in combinatorial optimization: An LLM based approach
https://openreview.net/forum?id=fasU6t3hL4
rating:2622, withdraw
痛点
- 组合优化问题(背包、装箱、聚类、汽油圈问题)大多 NP-hard,实际只能跑启发式。
- 想判断一个启发式到底多“烂”,需要构造让它表现尽可能差的实例(adversarial instance)。
- 传统局部搜索、遗传算法只能吐出毫无结构的数字向量,人类看不懂、更无法理论化;多年下来很多紧的下界提不上去。
核心思想
把 Google DeepMind 的“FunSearch”框架(用 LLM 写代码→进化→打分)改造成“Co-FunSearch”,让人类数学家一起参与,成功给四个经典 NP-hard 问题里的著名启发式算法挖了“最坏情况”大坑,把若干长期停滞的理论下界一次性提高,甚至推翻了一个 30 年悬而未决的“输出多项式时间”猜想。
方法
省流版:FunSearch写启发式代码 -> LLM生成他认为在这个代码上可能表现很差的实例 -> 人类专家观察代码和实例,推导出一些证明和定理 -> 数学层面上的理论突破
- 基于 Google DeepMind 的 FunSearch:用 LLM 生成 Python 程序 → 程序输出实例 → 实例打分 → 高分程序继续被 LLM 改写进化。
- 人类专家参与(Co-FunSearch):定期挑选最高分程序,手工简化、提炼结构、推广为通用构造,并给出数学证明。
- 优势:相比传统局部搜索,LLM 能生成结构化、可解释、可推广的实例,而非一堆无意义的数字。
实验和例子
| 问题 | 原最好下界 | 新下界(本文) | 意义 |
|---|---|---|---|
| Knapsack(背包问题) | 2.0 | 超多项式 | 首次推翻“Nemhauser-Ullmann 算法是输出多项式时间”的 30 年猜想 |
| Bin Packing(装箱问题) | 1.3 | 1.5 | 随机顺序模型下界大幅提升,距上界 1.7 只差 0.2 |
| k-median 聚类 | 1.0(平凡) | 黄金比例 ≈1.618 | 首次给出非平凡下界 |
| Gasoline 问题(Lovász 汽油圈) | 2.0 | >4.0 | 否定“迭代舍入是 2-近似”的猜想,高维可推到 6、8 等 |
成功案例:
- Bin Packing:LLM 生成冗长物品列表 → 专家简化为“只有两类物品” → 得到闭式构造 → 证明随机顺序比 ≥ 1.5。
- Knapsack:LLM 输出重复结构 → 专家改为“2 的幂次 + 微调因子” → 构造出中间 Pareto 集爆炸性增长的实例 → 证明算法时间复杂度为 n^Θ(√n)。
- k-median:LLM 生成高维点集 → 专家提炼为“3 个点 + 权重” → 证明 price of hierarchy 下界为 黄金比例 φ。
失败案例:
- 在 k-means 聚类、Ward 聚类、页面替换算法、Best-Fit 渐近随机比 等问题上,未能突破现有下界,甚至无法复现已知结果。
- 仍依赖人类专家“看懂并提炼”LLM 生成的代码,若结构隐藏过深则难以推广。
- 计算成本高:每个问题需运行数千次 LLM 调用。
审稿人意见
写作存在一些问题,工作的意义没有表述清晰。
Improving LLM Symbolic Problem-Solving via Automated Heuristic Discovery
https://openreview.net/forum?id=yX1gmPYHOL
rating:4468, Reject
目标
提出了一种名为 AutoHD(Automated Heuristic Discovery) 的新方法,用于提升大语言模型(LLM)在符号类问题求解任务中的推理能力。
痛点
传统的推理增强方法(如 Chain-of-Thought、Tree-of-Thoughts)依赖于模型自身的判断或外部验证器来评估中间步骤,但存在以下问题:
- 自验证不可靠:LLM 不能准确判断中间步骤是否正确。
- 外部模型成本高:需要额外训练或大量数据。
解决思路
让 LLM 自己生成启发式函数(heuristic function),用于评估中间状态离目标有多远,从而指导搜索过程。
CoT:Chain of Thought,ToT:Tree of Thought,GoT:Graph of Thought

方法概述
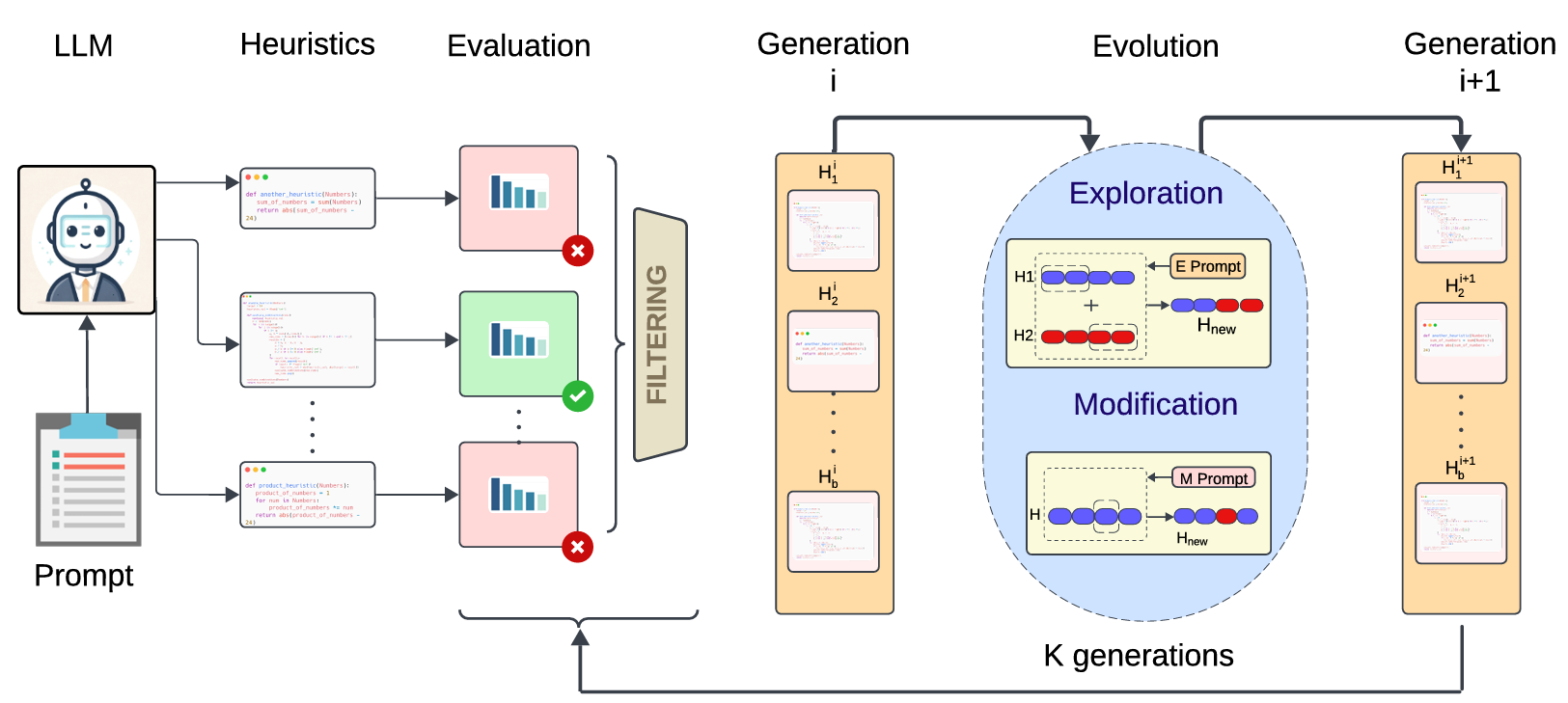
- 启发式函数生成:
- 用 LLM 生成多个 Python 格式的启发式函数,用于估算当前状态到目标状态的“距离”。
- 每个函数包括自然语言描述和可执行代码。
- 启发式引导搜索:
- 在推理阶段,使用生成的启发式函数指导搜索算法(如 A* 或贪心 BFS)选择最优路径。
- 不再依赖 LLM 自评或外部模型。
- 启发式进化:
- 通过多轮“进化”优化启发式函数:保留表现好的,生成新的变体。
- 使用小验证集评估每个函数的效果,逐步提升质量。
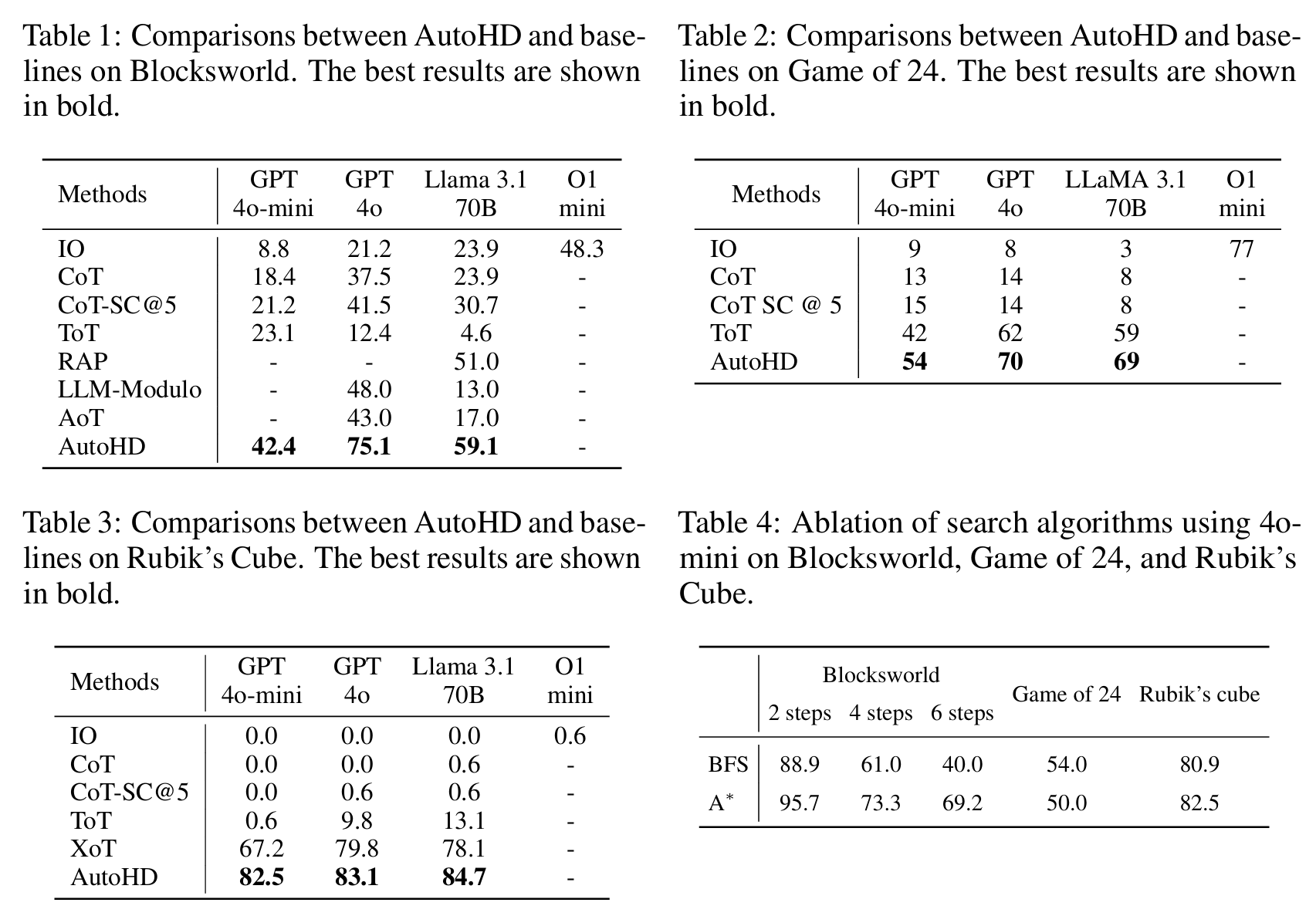
实验
在三个经典符号推理任务上测试
审稿人意见
计算成本较高、实验不充分
Hierarchical Representations for Cross-task Automated Heuristic Design using LLMs
https://openreview.net/forum?id=dgvx86qybJ
rating:2646, Reject
痛点
传统的启发式算法设计依赖专家经验,耗时且难以迁移。近年来,大语言模型(LLMs)被用于自动启发式设计(AHD),但现有方法多为单任务、单启发式,缺乏跨任务泛化能力。相比之下,人类专家设计的元启发式(如禁忌搜索、模拟退火)具有更强的通用性。
贡献
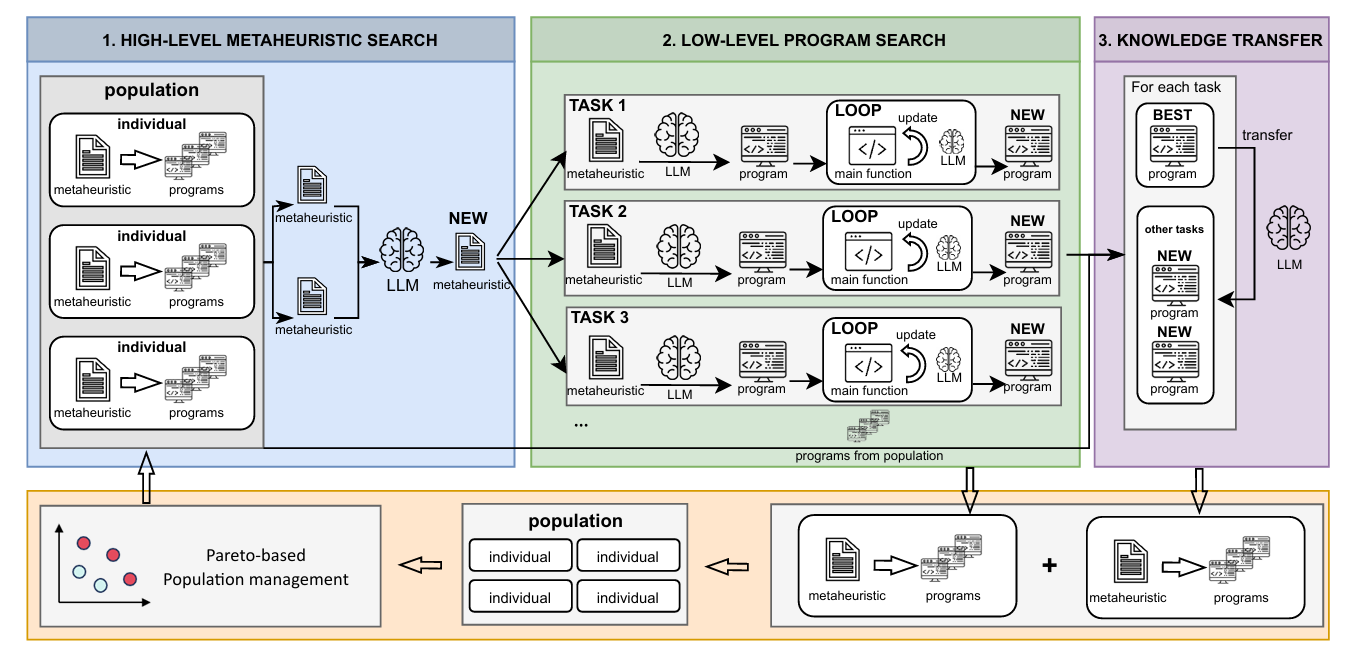
- 提出层次化表示(Hierarchical Representation)
将启发式算法分为两层:
- 高层:任务无关的元启发式(Metaheuristic)
- 低层:任务特定的程序实现(Task-specific Program)
- 设计 MTHS 框架
- 同时演化多个任务的元启发式和程序实现
- 引入知识迁移机制,将某任务上表现优异的程序适配到其他任务
- 使用Pareto 多目标优化管理种群,平衡多个任务的性能
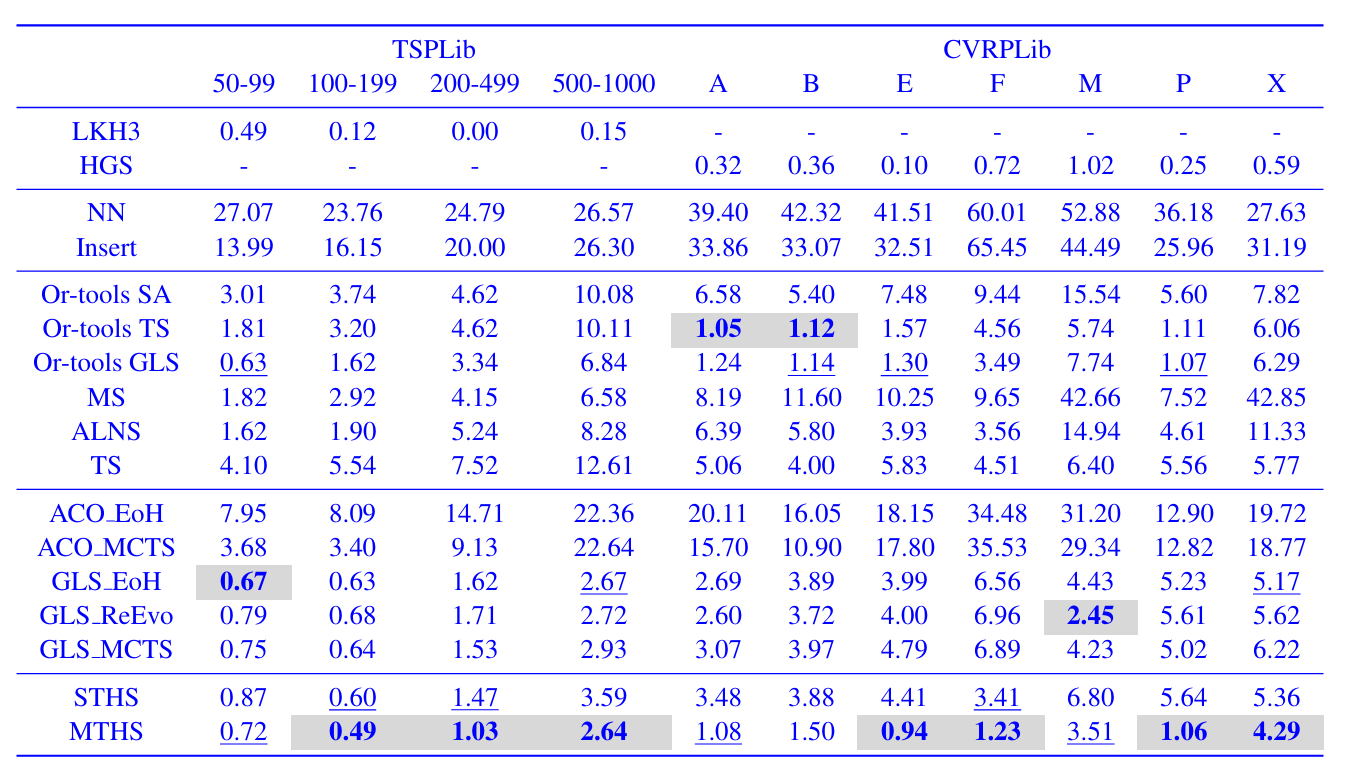
- 实验验证
在多个组合优化问题(TSP、CVRP、FSSP、BPP)上,MTHS 显著优于:
- 传统启发式(如 NN、Insert、TS、ALNS)
- Google OR-Tools 的元启发式
- 现有 LLM 驱动的 AHD 方法(如 EoH、ReEvo、MCTS-AHD)
实验

审稿人意见
没有消融实验,运行成本较高,未见明显多任务。
个人看法:这个多任务
TPD-AHD: Textual Preference Differentiation for LLM-Based Automatic Heuristic Design
https://openreview.net/forum?id=VEMknlIPtM
rating:2442, Reject
痛点
传统大语言模型驱动的自动启发式设计(LLM-AHD)中存在的搜索方向不明确、优化过程不可解释等问题。
贡献
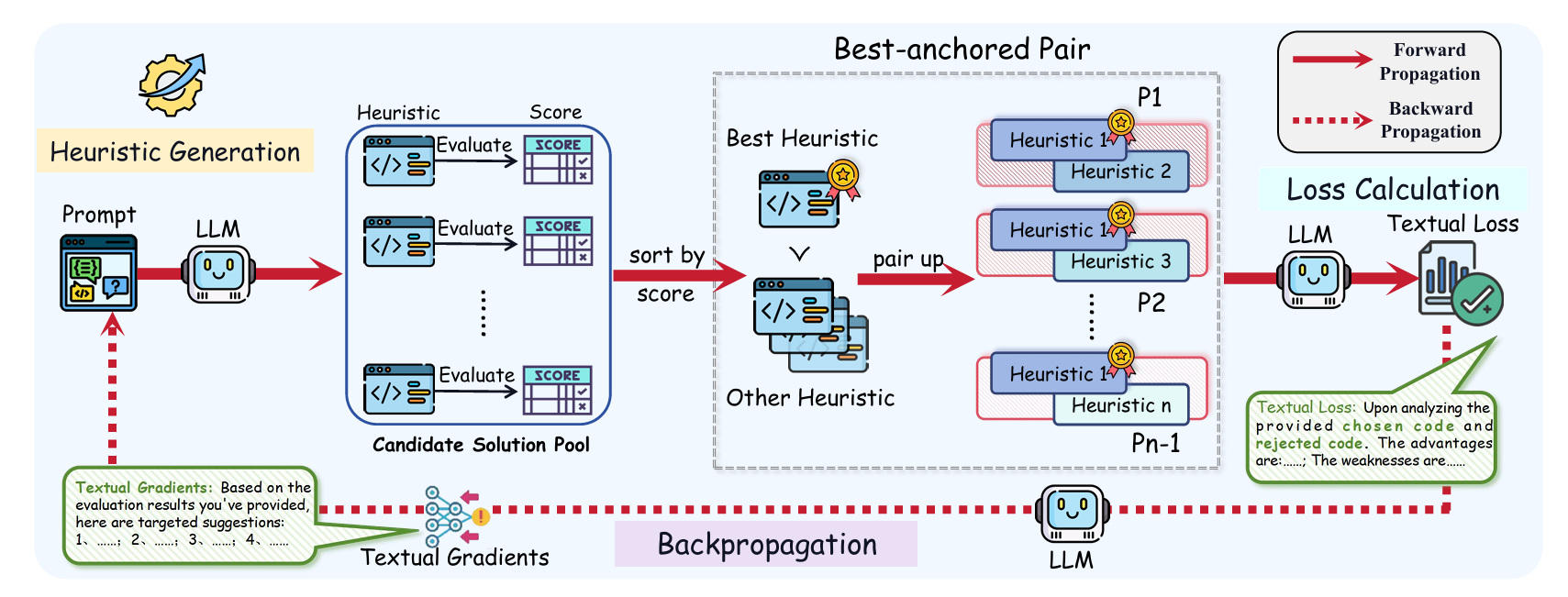
- 提出TPD-AHD框架 这是首个将文本偏好优化(Textual Preference Optimization)与文本梯度(Textual Gradient)结合用于组合优化问题启发式设计的框架。它通过自然语言形式的反馈引导启发式算法的演化,具有高度的可解释性和方向性。
- 最佳锚定偏好配对机制(Best-Anchored Preference Pairing) 在每一轮迭代中,框架会将当前最优启发式与其他候选启发式进行配对比较,生成一个“文本损失(Textual Loss)”,用于指导下一步的优化方向。这种机制减少了低质量候选对优化过程的干扰,提升了学习效率。
- 文本梯度反向传播(Textual Gradient Backpropagation) 文本损失被用于生成自然语言形式的“文本梯度”,直接指导如何修改提示词(prompt)以生成更优的启发式算法。这一过程模拟了连续优化中的梯度下降,但完全在离散文本空间中进行。
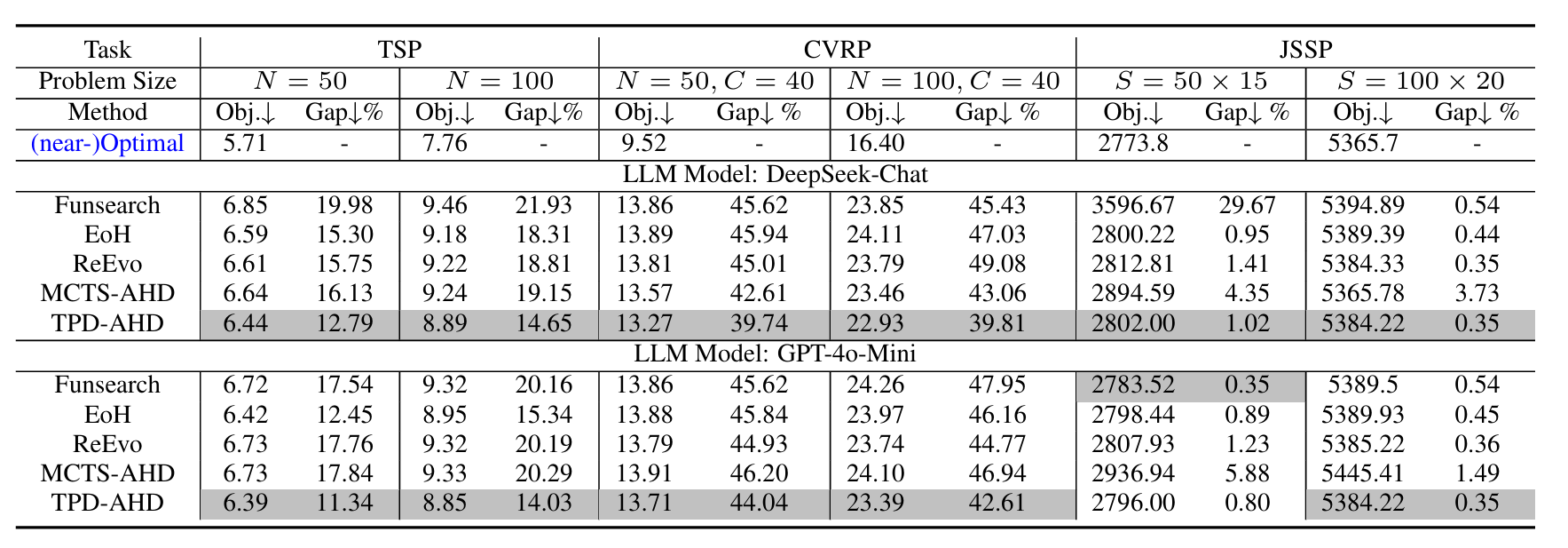
实验

审稿人意见
动机不充分,文本梯度本质还是反思。
CodePDE: An Inference Framework for LLM-driven PDE Solver Generation
https://openreview.net/forum?id=q196xGhRMa
rating:424,withdraw
卡耐基梅隆大学
目标
求解偏微分方程(PDE)。
动机
大型语言模型(LLM)在复杂数学与科学任务上展现出惊人潜力 。其核心洞见在于:代码是连接自然语言与符号科学计算的通用中介。受此启发,一个引人注目的新范式应运而生:仅用自然语言描述 PDE,即可自动产生可执行的求解器代码。
发现
- 可靠性—复杂度权衡:部分模型保守地采用低阶格式以保证鲁棒,而前沿模型(如 o3、Gemini-2.5-Pro)能在探索高阶、多样方案的同时保持低失败率。
- 生成与精修技能分离:推理型模型(o3、DeepSeek-R1)初始生成更强,但在精修阶段未必优于标准模型(GPT-4o、DeepSeek-V3),提示两种能力可能由不同机制驱动。
贡献
- 将 PDE 求解重塑为代码生成任务,提出首个结合领域知识、自改进与测试时扩展的 LLM 推理框架 CodePDE。
- 证明 CodePDE 能充分释放 LLM 潜力,生成高质量 PDE 求解器。
- 首次对 LLM 生成的 PDE 求解器进行系统研究,分析其精度、效率、数值方案多样性及失效模式,为构建更强大、可靠的科学计算 LLM 提供指南。
方法
- 问题描述
- 代码生成
- Debug
- 评估
- 求解器精修
实验
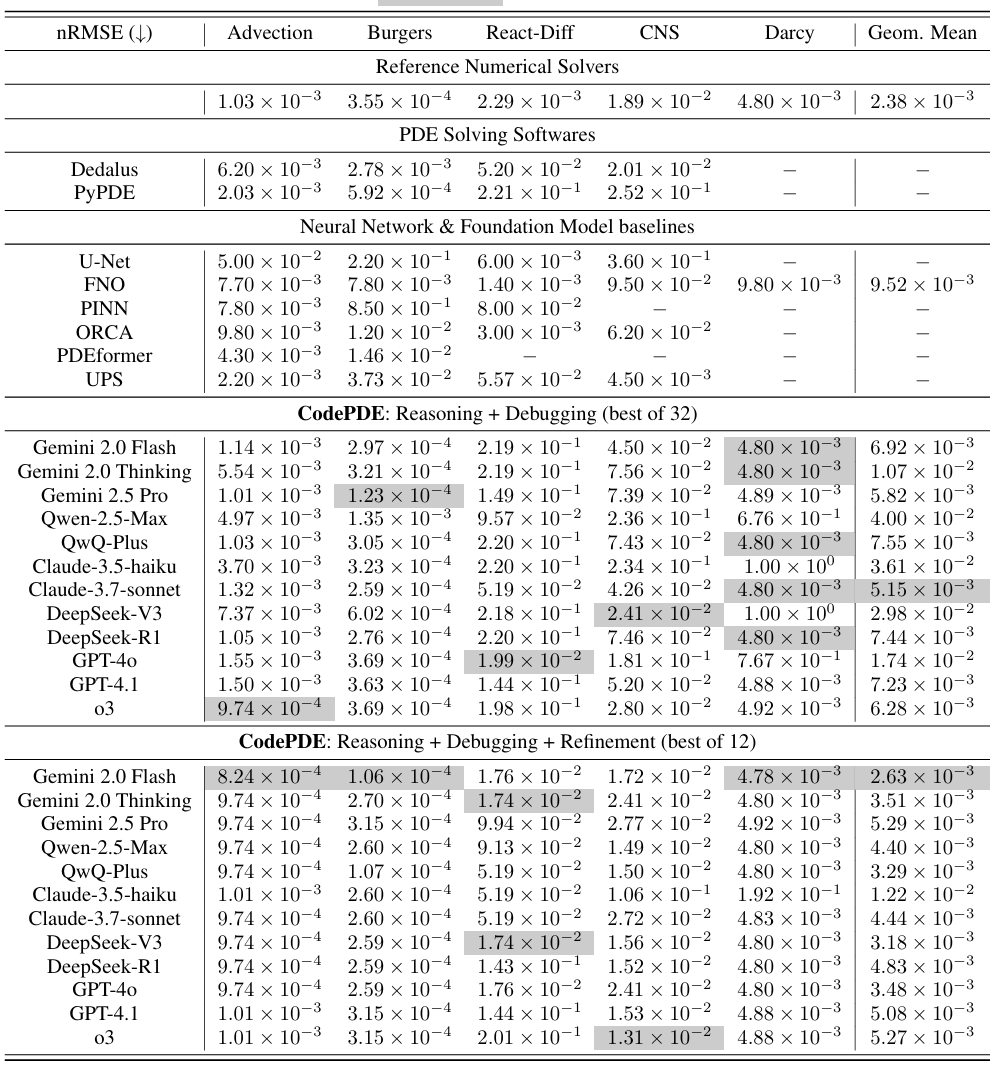
审稿意见
求解对象过于简单,成本较高,难以替代传统求解器。
VRPAgent: LLM-Driven Discovery of Heuristic Operators for Vehicle Routing Problems
https://openreview.net/forum?id=02mBAZjFzp
rating:6444, Reject
痛点
NCO痛点
- 测试阶段需要昂贵 GPU,限制了实际部署;
- 可扩展性差:注意力机制必须处理完整距离矩阵,导致大规模实例难以应用;
- 学到的策略难以被人类专家解读,引发可靠性与安全性担忧。
LLM启发痛点
- “弱代理沙盒”:仅让 LLM 生成零散的小代码片段,缺乏整体求解框架支撑;
- 缺乏正确性保障:生成代码可能不可行或破坏解结构;
- 搜索效率低:容易陷入冗长、脆弱、难以维护的实现。
核心思想
利用大语言模型(LLM)自动为车辆路径问题(VRP)发现高效的启发式算子,从而突破传统人工设计启发式的瓶颈,其中:
- LLM 只负责生成“问题专用的启发式算子”(如:从当前解中移除哪些客户、按什么顺序重新插入);
- LNS 框架本身保持不变,负责保证解的可行性与搜索结构;
- 通过 遗传算法(GA) 迭代优化这些 LLM 生成的算子,最终发现 超越人类设计的启发式策略。
优势:问题无关,仅需单核CPU。
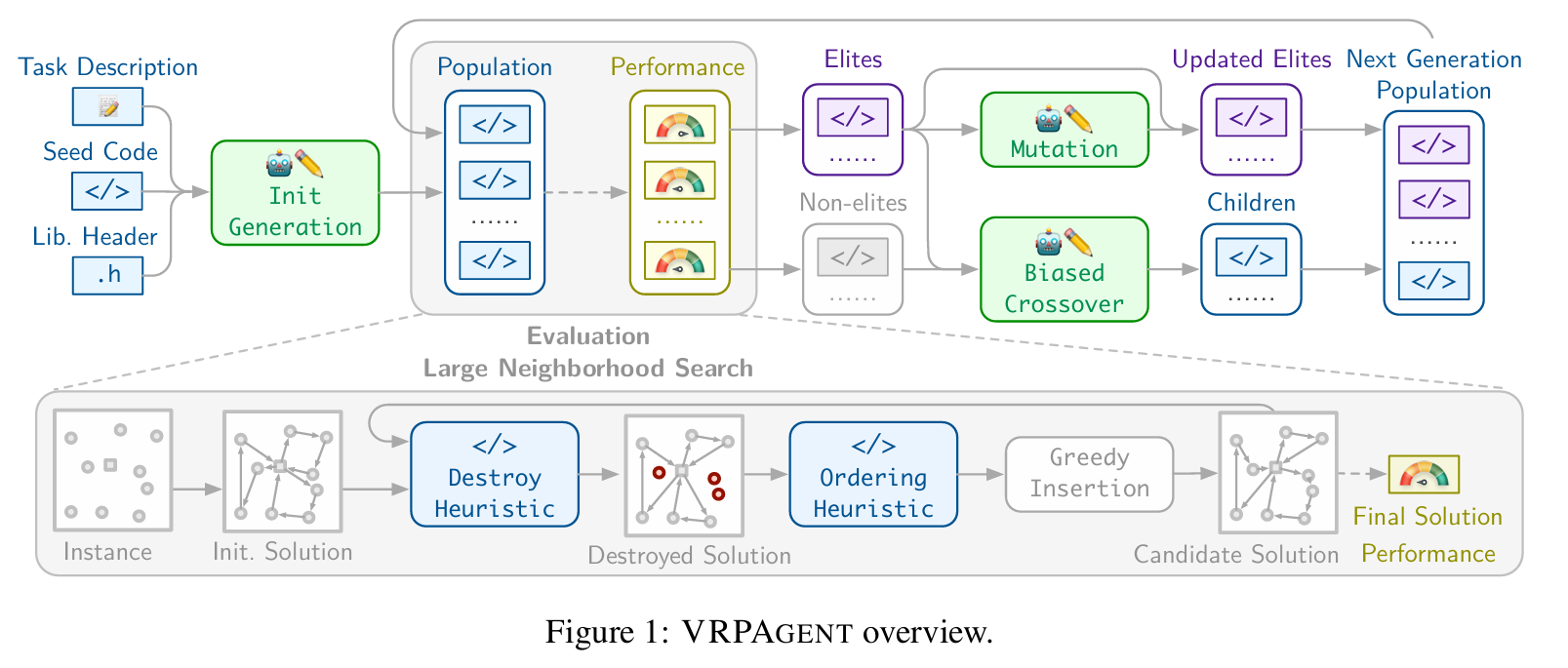
方法
LNS框架
对给定实例 ,LNS 首先生成初始解 (每客户一条路径)。随后重复以下步骤,直到满足终止条件:
- 销毁:调用 LLM 生成的算子,从当前解中移除一组客户,得到部分解 ;
- 排序:调用 LLM 生成的算子 ,对移除客户得到排序列表;
- 重插入:按该顺序逐个贪婪插入到当前解的局部最优位置(即增量目标值最小);
- 接受:若新解更优,或以模拟退火概率接受,则替换当前解。
最终返回搜索过程中发现的最佳解。
LLM代码进化
- 初始化种群
- 评估
- 排序,分为精英种群和非精英种群
- 80%的精英和20%的非精英交叉
- 精英个体变异
- 形成下一代
- 重复2-6,40轮
实验
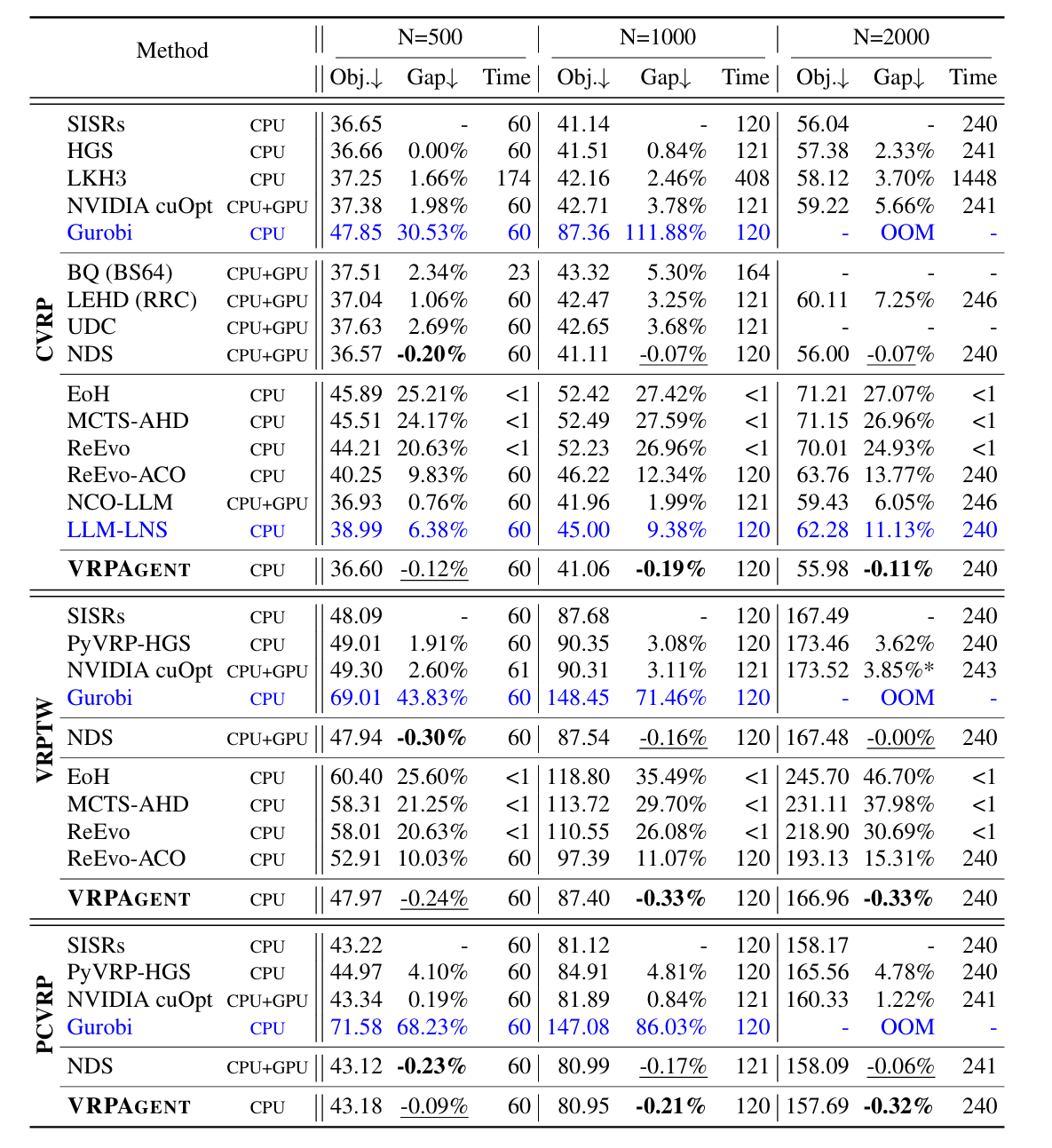
审稿人意见
生成的算法没有可解释性和逻辑解释,成本高,参数过多且难调。
LLMs for Sequential Optimization Tasks: from Evaluation to Dialectical Improvement
https://openreview.net/forum?id=hlFD8pl4qD
rating:2228,withdraw
(这个写作很有意思,故事背景是黑格尔辩证法)
目标
序列优化问题(SOP)。
动机
不给任何人工干预,仅把LLM当成黑盒,它能否独立完成整个优化闭环?
贡献
| 名称 | 作用 | 关键创新 |
|---|---|---|
| WorldGen | 动态评测平台 | 即时生成“从未见过”的n维优化地形,难度可调,彻底避免数据污染与刷榜。 |
| ACE | 推理框架 | 把黑盒LLM变成“会自我批判、会迭代升级”的优化专家,零额外训练,只靠测试时的“正反合”辩证循环提升性能。 |
方法
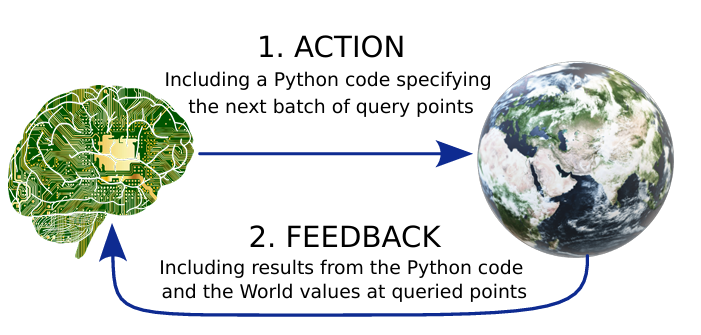
WorldGen
核心思想:优化的本质是在一个 $n$ 维世界中找到最优点,数学上表示为寻找
\[f(x_1,x_2,\ldots,x_{n-1})\]的极值。
交互循环:为了让 LLM 智能体有效执行任务,我们通过图 2 所示的循环为其提供对生成世界的访问权限。每一轮中,智能体可选择一个批次的查询点,每个点是一个向量 $v_i\in\mathbb{R}^{n-1}$;世界随后返回对应的函数值 $f(v_i)$ 给智能体,结束本轮交互。下一轮,LLM 利用这些反馈决定下一批查询点。
用辩证法提升 LLM 在 SOP 中的表现
动机: vanilla LLM 在非平凡 SOP 上表现不佳,我们能否不经过重训练、微调或后训练就提升其性能?
核心思想:借鉴黑格尔辩证法,我们将 LLM 智能体抽象为立论生成器(Thesis Generator),并引入驳论生成器(Antithesis Generator)与合题模块(Synthesis Block),形成“正反合”迭代循环:
- Thesis 提出初始解;
- Antithesis 批判并指出漏洞或替代视角;
- Synthesis 融合两者,产生更精炼的解。
该结构促使系统持续演化,最终得到更优结果。基于此,我们提出 ACE(Act–Critique–Evolve)框架,其三个组件为:
- Actor:生成立论(初始策略/查询点);
- Critic:生成驳论(批判与改进建议);
- Synthesizer:融合并输出升级后的立论,进入下一轮。
审稿人意见
不明确的框架、模糊的方法论以及意义存疑的问题。
Evaluating LLMs for Combinatorial Optimization: One-Phase and Two-Phase Heuristics for 2D Bin-Packing
https://openreview.net/forum?id=9i3PS60x4z
rating:2022, 不可见了
(锐评,不如大作业)
省流:用类似EoH的方式做装箱问题。
AutoFloorplan: Evolving Heuristics for Chip Floorplanning with Large Language Models and Textual Gradient-Guided Repair
https://openreview.net/forum?id=DS2iool3nv
rating:4424, Reject
研究对象
芯片布局。
贡献
- 提出AutoFloorplan框架 结合大语言模型(LLMs)与进化算法,自动生成并优化布局启发式算法。
- 文本梯度引导修复机制(Textual Gradient-Guided Repair)
当LLM生成的算法违反布局约束(如模块重叠或越界)时,系统不会直接丢弃,而是:
- 分析错误原因;
- 生成自然语言的“文本梯度”反馈;
- 指导LLM修复算法逻辑。
- 双循环结构
- 外循环:进化搜索,生成多样化的布局算法;
- 内循环:文本梯度修复,提升算法合法性与性能。
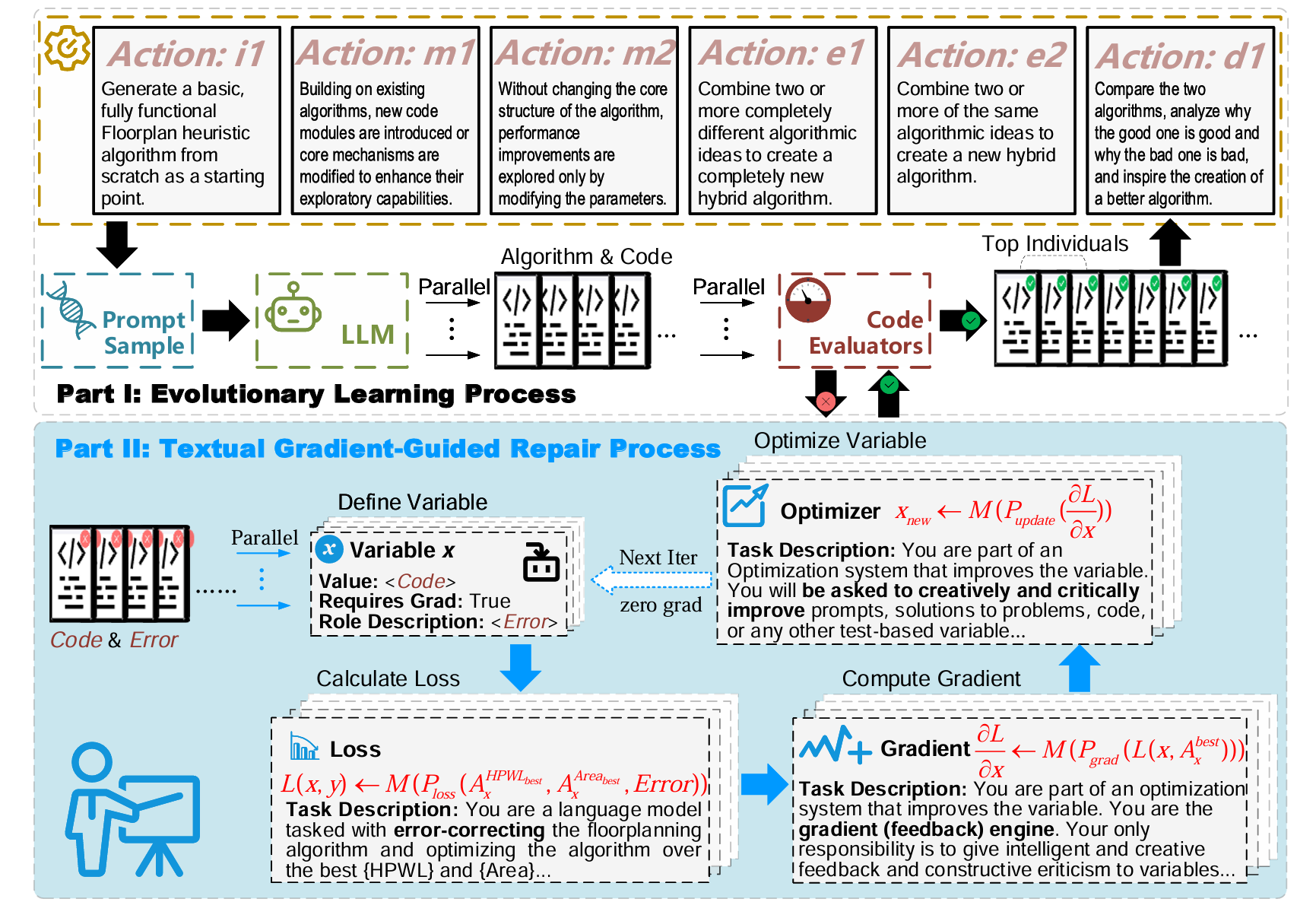
审稿人意见
没什么创新,就是EoH+TextGrad,做芯片布局问题。