第一讲:并行计算概览
1. 什么是并行计算
并行计算可以简单定义为同时利用多个计算资源解决一个计算问题
- 程序运行在多个 CPU 上;
- 一个问题被分解成离散可并发解决的小部分;
- 每一小部分被进一步分解成一组指令序列;
- 每一部分的指令在不同的 CPU 上同时执行;
- 需要一个全局的控制和协调机制;
并行计算主要研究下面几个方面的内容
- 并行架构
- 并行算法
- 并行编程
- 并行性能
- 并行应用
2. 并行计算有哪些优势
- 在自然界,很多复杂的、交叉发生的事件是同时发生的,但是又在同一个时间序列中;
- 与串行计算相比,并行计算更擅长建模、模拟、理解真实复杂的现象
- 节省时间和花费
- 理论上,给一个任务投入更多的资源将缩短任务的完成时间,减少潜在的代价;
- 并行计算机可以由多个便宜、通用计算资源构成;
- 解决更大/更复杂问题:很多问题很复杂,不实际也不可能在单台计算机上解决,例如:Grand Challenges
- 实现并发处理:单台计算机只能做一件事情,而多台计算机却可以同时做几件事情(例如协作网络,来自世界各地的人可以同时工作)
- 利用非本地资源:当本地计算资源稀缺或者不充足时,可以利用甚至是来自互联网的计算资源。
- SETI@home (setiathome.berkeley.edu);
- Folding@home (folding.stanford.edu)
- 更好地发挥底层并行硬件
- 现代计算机甚至笔记本都具有多个处理器或者核心;
- 并行软件就是为了针对并行硬件架构出现的;
- 串行程序运行在现代计算机上会浪费计算资源;
3. 并行计算的主要用途
- 科学和工程计算(大气地球环境、物理学、生物学)
- 工业和商业应用(大数据数据库数据挖掘、石油勘探、医学图像web引擎)
4. 并行计算的主要推动力是什么
应用发展趋势
-
在硬件可达到的性能与应用对性能的需求之间存在正反馈
-
大数据时代,云计算的兴起
架构发展趋势
摩尔定律支持芯片行业的发展:「芯片上的集成晶体管数量每 18 个月增加一倍」。
发展趋势不再是高速的 CPU 主频,而是「多核」。(摩尔定律失效的原因之一)
5. 并行计算的粒度
函数级并行、线程级并行还是进程级并行
- 线程级并行
- 指令级并行利用循环或直线代码段内的隐式并行操作
- 线程级并行显式地表示为利用多个本质上是并行的线程执行
- 线程可被用于单处理器或多处理器上
- ILP 和 TLP 的联系
- 在为 ILP 设计的数据路径中,由于代码中的阻塞或依赖关系,功能单元通常处于空闲状态。
- TLP 用作独立指令的来源,在暂停期间可能会使处理器繁忙。
- 当 ILP 不足时,TLP 被用于占用可能闲置的功能单元。
6. 并行计算的难点
并行编译器的局限
仅做到了有限的并行检测核程序转换
- 执行级的并行,只能检测到basic block;
- 少量的嵌入的 for-loops;
- 分析技术如数据依赖分析、指针分析、流敏感分析等,难以应用到大规模程序中
并行编程困难点
- 找到尽量多的并行点
- 粒度:函数级并行、线程级并行还是进程级并行
- 局部性:并行化后是否能够利用局部数据等
- 负载均衡:不同线程、不同 core之间的负载分布
- 协作和同步
- 性能模型
7. Amdahl’s law
用于度量并行程序的加速效果 \(\begin{gathered} \text { Speedup }=\frac{1 \text { threadexecution time }}{n \text { threadexecution time }} \\ \text { Speedup }=\frac{1}{(1-p)+p / n} \end{gathered}\) 其中,p 表示程序可并发的部分占整个程序的比例。
第二讲:并行架构
1. Flynn’s 并行架构分类
基于指令流和数据流数量的计算机体系结构分类

SISD 架构:单核计算机 SIMD 架构:向量处理器,GPUs MISD 架构:(没有符合的知名系统。。) MIMD 架构:现代并行系统
2. 什么是 pipeline
将计算机指令处理过程拆分为多个步骤,并通过多个硬件处理单元并行执行来加快执行速度。
流水线有助于带宽而不是延迟
- 带宽受限于最慢的流水线阶段
- 加速潜力 = 流水线级数
- MIPS 流水线的 5 个阶段:Fetch->Decode->Execute->Memory->Write Back
- 流水线 CPI < 1
流水线的限制
- 开销防止任意划分
- 阶段之间锁存器的成本限制了阶段内能做什么
- 设置最小数量的阶段
- 冒险阻止下一条指令在其指定的时钟周期内执行
- 结构冒险:尝试同时使用相同的硬件执行两个不同的操作
- 数据冒险:指令取决于仍在流水线中先前指令的结果
- 控制冒险:由于控制流程(分支和跳跃)中的指令和决策获取之间的延迟而造成的
-
超标量增加的冒险的发生
-
更多冲突的指令(时钟周期)
3. 有哪些形式的指令级并行
- 流水线:指令的各个部分重叠
- 超标量执行:同时执行多个操作
- VLIW(极长指令字):让编译器指定哪些操作可以并行运行
- 向量处理:指定相似的操作组
- 乱序执行:允许长时间操作
现代指令级并行的特点
- 动态调度,乱序执行
- 获取一堆指令,确定它们的依赖性并尽可能消除其依赖性,将它们全部扔到执行单元中,向前移动指令以消除指令间的依赖性。
- 如同按顺序执行
- 投机执行
- 猜测分支的结果,若猜测错误必须能够撤销结果
- 猜测的准确性随着流水线中同时运行的指令数量增加而降低
-
巨大的复杂性
-
许多组件的复杂性按 n² 来衡量
4. 什么是 Pthreads
- POSIX 线程概述
- POSIX: Portable Operating System Interface for UNIX
- Pthread: The POSIX threading interface
- Pthread 包括支持创建并行性、同步,不显式支持通信,因为共享内存是隐式的;指向共享数据的指针传递给线程。
- 只有堆上的数据可共享,栈上的数据不可共享。
5. 内存局部性原则有哪些
- 内存系统性能的限制
- 内存系统,而不是处理器速度,往往是许多应用程序的瓶颈。
- 内存系统性能主要由两个参数(延迟和带宽)影响。
- 延迟(Latency)是指从发出内存请求到处理器提供数据的时间。
- 带宽(Bandwidth)是存储系统将数据泵送到处理器的速率。
- 局部性原则
- 程序在任何时刻访问相对较小的地址空间。
- 时间局部性:如果一个项被引用,它很快就会再次被引用(例如循环、重用)。
- 空间局部性:如果引用了某个项,则其地址接近的项很快就会被引用(例如,直线代码、数组访问)。
6. 内存分层
- 局部性原则的优点
- 以最便宜的技术呈现尽可能多的内存。
- 以最快的技术提供的速度提供访问。

7. Caches 在内存分层结构中的重要作用
- 缓存是处理器和 DRAM 之间的小型快速内存元素。作为低延迟高带宽存储,如果重复使用一条数据,缓存可以减少该内存系统的有效延迟。
- 缓存满足的数据引用部分称为缓存命中率。由存储系统上的代码实现的缓存命中率通常决定其性能。
8. 新型存储系统的构成

9. 什么是并行架构
使用多处理器的机器
- 并行结构一般是指并行体系结构和软件架构采取并行编程。主要目的是使更多任务或数据同时运行。并行体系结构是指许多指令能同时进行的体系结构;并行编程一般有以下模式:共享内存模式;消息传递模式;数据并行模式。
- 并行计算机是一组处理元素的集合,它们协同快速地解决一些大问题,能够资源分配、数据访问、通信和同步、高性能和可扩展性。
10. MIMD 的并行架构包括哪些实现类型
MIMP:多指令多数据流,包括共享内存,消息传递
- 对称多处理器:内置多个处理器,共享内存通信,每个处理器运行操作系统的拷贝,例如现在的多核芯片。
- 通过主机的独立 I/O 的非统一共享内存:多处理器,每个都有本地内存,通用可扩展网络,节点上非常轻的 OS 提供简单的服务,调度/同步,用于 I/O 的网络可访问主机。
- 集群:多台独立机接入通用网络,通过消息沟通。
11. MPP 架构的典型例子及主要构成

第三讲:并行编程模型
1. 什么是并行编程模型
并行编程模型是并行计算机体系架构的一种抽象,它便于编程人员在程序中编写算法及其组合。
描述了程序员在编码应用程序中使用什么来指定通信和同步。
- 历史上(70 年代至 90 年代初),每台并行机都是独一无二的,其编程模型和语言也是独一无二的。架构=程序模型+通信抽象+机器,并行架构与编程模型相关。
- 现在,我们将编程模型与底层的并行机器体系结构分离开来。
- 主要编程模型有:共享地址空间、消息传递、数据并行;其他类型有:数据流、收缩阵列。
- 通过扩展「计算机体系结构」以支持通信与合作。旧:指令集架构;新:通信架构。
- 定义:关键抽象、边界和接口;实现接口的组织结构。
- 编译器、库和操作系统是重要的桥梁。
2. 并行编程模型主要包括哪些类型,主要特点是什么
- 并行编程模型及特点
- 消息传递:封装本地数据的独立任务,任务通过交换消息进行交互。
- 结构化通信
- 比共享内存更难编程
- 容易改写为分布式程序
- 共享内存:任务共享公用地址空间,任务通过异步读写此空间进行交互。
- 通信非结构化,显式加载和存储
- 编程自然,在程序正确的情况下,性能可能不佳
- 数据并行:任务执行一系列独立的操作,数据通常在任务之间均匀分区。
- 结构化计算
- 多道程序设计
3. 并行编程模型主要包括哪几部分
- 控制:如何创建并行性;应按什么顺序进行操作;不同的控制线程是如何同步的
- 命名:什么数据是私有的还是共享的;如何访问共享数据
- 操作:什么操作是原子操作
- 成本:我们如何计算运营成本
4. 共享内存模型有哪些实现
- 共享内存模型
- 任何处理器都可以直接引用任何内存位置,由于加载和存储而隐式发生通信;方便;位置透明度;与单处理器时间共享类似的编程模型。
- 在这个编程模型中,任务共享一个公共地址空间,它们异步读写。可以使用各种机制,如锁/信号灯来控制对共享内存的访问。从程序员的角度来看,该模型的一个优点是缺乏数据「所有权」的概念,因此无需明确规定任务之间的数据通信。程序开发通常可以简化。在性能方面的一个重要缺点是,越来越难以理解和管理数据位置。将数据保持在处理器的本地,这样可以节省在多个处理器使用相同数据时发生的内存访问、缓存刷新和总线流量。不幸的是,控制数据位置很难理解,并且超出了普通用户的控制范围。
- 实现
- SAS Machine Architecture
- Scaling Up
5. 造成并行编程模型不能达到理想加速比的原因
-
利用 Amdahl’s Law 定律,分析如下:有的部分不能并行

-
还有其他的问题:
问题出在,如图:
- 线程创建需要开销。
- 数据划分会出现不均衡(负载不均衡)。
- 共享数据会出现 RC 问题、死锁问题:加锁、解锁影响性能。

6. 任务和线程之间的关系
- 分解
- 数据分解:将整个数据集分解为更小、离散的部分,然后并行处理它们
- 任务分解:根据独立子任务的自然集合划分整个任务
- 任务和线程
- 任务由数据及其进程组成,任务调度程序会将其附加到要执行的线程上。
- 任务操作比线程操作便宜得多。
- 通过窃取轻松平衡线程之间的工作量。
- 任务适合列表、树、地图数据结构
- 注意事项
- 任务比线程多
- 更灵活地安排任务
- 轻松平衡工作量
- 任务中的计算量必须足够大,以抵消管理任务和线程的开销。
-
静态调度:任务是独立函数调用的集合,或者是循环迭代
- 动态调度:任务执行长度可变且不可预测 可能需要一个额外的线程来管理共享结构以保存所有任务
7. 什么是线程竞争,如何解决
一般来说,指的是多个线程在同一时间访问同样的内存位置,其中至少有一个线程进行写操作。
解决:
- 使用临界避免同时访问
- 互斥和同步、临界区、原子操作
- 把全局变量变成线程的局部变量
- 共享数据的本地备份
- 在线程栈上声明变量
死锁
- 两个或多个线程等待彼此释放资源;一个线程等待一个永远不会发生的事件,比如挂起的锁。
- 注意事项:始终按相同顺序锁定和解除锁定,并尽可能避免层次结构;使用原子操作
第四讲:并行编程方法论
1. 什么是增量式并行化
- 研究串行程序(或代码段)
- 寻找瓶颈和并行性机会
- 尝试让所有处理器忙于做有用的工作
2. Culler 并行设计流程
主要分四个步骤:(Decomposition)解耦、(Assignment)分派、(Orchestration)配置、(mapping)映射。
图解如下:

Decomposition
定义:将问题分解为可以并行执行的任务。
- 分解不需要静态发生
- 新任务可以在程序执行时被识别
核心思想、目的:创建最少任务且使得所有的机器上的执行单元都处于忙碌状态
关键方面:识别出依赖部分。
负责的对象:一般是程序员来做这件事情。
Assignment
定义:分发任务给线程。
目标:负载均衡,减少通信开销。
特点:静态动态皆可,一般需要程序员来负责,也有非常多语言可以自动对此负责。
Orchestration
定义:结构化通信;增加同步来保证必要的依赖性;在内存中组织数据结构;调度任务
目的:减少通信和同步的开销,保护数据的局部性,减少额外开销
Mapping
定义:将线程映射到硬件执行单元
执行对象:操作系统、编译器、硬件
3. Foster 并行设计流程
分为四个部分:Partitioning、Communication、Agglomeration (归并、组合)、Mapping。
图解:

分解
定义:将计算和数据分成若干部分
三种不同实现方式:按数据分解、按任务分解、流水线
通信
定义:确定在任务之间传递的值values(任务数据依赖图)
分类:
- 局部通信:任务需要来自少量其他任务的值;创建说明数据流的通道
- 全局通信:大量任务提供数据以执行计算;不要在设计早期为他们创建渠道
注意事项
- 通信是并行算法的开销,我们需要将其最小化
- 任务之间的通信操作平衡
- 每个任务仅与一小群邻居通信
- 任务可以同时执行通信
- 任务可以同时执行计算
整合、归并
定义:小任务变大任务
映射
定义:把任务分配到处理器上的过程
- 中心多处理器系统: mapping done by operating system
- 分布式系统: mapping done by user
目标矛盾:最大化处理器利用率;最小化通信
4. 按数据分解和按任务分解的特点
按数据分解
- (数据/域分区/分解)决定数据如何划分给处理器;决定每个处理器如何执行任务
- 将数据划分为多个部分
- 确定如何将计算与数据相关联
按任务分解
- (任务/功能分区/分解)划分任务给处理器;再确定数据的获取
- 将计算划分为多个部分
- 确定如何将数据与计算相关联
5. 并行任务分解过程中应该注意的问题有哪些
- 原始任务至少比目标计算机中的处理器多 10 倍
- 如果不是,则以后的设计选项可能过于受限
- 最大限度地减少冗余计算和冗余数据存储
- 如果不是,则当问题的大小增加时,设计可能无法正常工作
- 基本任务大小大致相同
- 如果不是,则可能很难在处理器之间平衡工作
- 任务数是问题大小递增的函数
- 如果不是,则可能无法使用更多处理器来解决大型问题实例
6. 整合的意义是什么
- 提升性能:(减少通信)消除聚合成合并任务的原始任务之间的通信。
- 保持问题的可并行性
- 简化编程(减小软件工程开销)
在消息传递型的编程模型中,目标通常是为每个处理器创建一个聚合任务。
7. 映射如何决策
决策树:分两种情况:静态任务和动态任务
- 静态任务
- 有解构的通信
- 每个任务的常量计算时间(a) 组合任务以最大限度地减少通信 (b) 为每个处理器创建一个任务
- 每个任务的可变计算时间(a) 周期性地将任务映射到处理者
- 无解构的通信:使用动态负载均衡算法
- 有解构的通信
- 动态任务
- 任务之间的频繁通信:动态负载均衡算法
- 许多短期任务:运行时调度算法
8. 熟悉一些并行设计的例子
棒随着时间的推移而冷却(散热问题)
有限差分
第五讲:OpenMP 并行编程模型
1. 什么是 OpenMP
Open Multi-Processing 开放多处理过程
- 提供针对共享式内存并行编程的 API
- 简化了并行编程在 fortran、C、C++等环境下
一种显式(非自动)编程模型,为程序员提供对并行化程序的控制
2. OpenMP 的主要特点是什么
- OpenMP 通过完全使用线程来实现并行
- 共享内存的编程模型,线程通信主要通过共享内存变量
- 也是因为共享变量可能会导致数据竞争,循环依赖等
3. 熟悉 OpenMP 的关键指令
#pragma omp parallel // 表明之后的结构化代码块被多个线程处理
#pragma omp parallel num_threads(thread_count) // 可自定义线程数量
#pragma omp critical // 只有一个线程能够执行对应代码块,并且第一个线程完成操作前,没有其他的线程能够开始执行这段代码
#pragma omp parallel for // parallel for 指令生成一组线程来执行后面的结构化代码块(必须是for循环)。
-
一些 OpenMP 常用函数
- omp_get_thread_num() 获取当前线程编号
- omp_get_num_threads() 获取当前线程组的线程数量
- omp_set_num_threads() 设置线程数量
-
所有的 OpenMP 指令都有#pragma omp [clause, …]这种形式
-
#pragma omp parallel
-
#paragm omp parallel num_threads (thread_count)
- 介绍一下这个程序运行到这个子句之后的操作,首先程序本身只含有一个线程,在遇到该指令之后,原来的线程继续执行,另外的 thread_count – 1 个线程被启动,这 thread_count 个线程称为一个线程组,原始线程为主线程,额外的 thread_count – 1 个线程为从线程,在并行化代码块的末尾存在一个隐式路障,所有线程都到达隐式路障后从线程结束,主线程继续执行。也就是下图所示的 fork-join 过程
-
#pragma omp parallel for
- parallel for 指令,用于并行化 for 循环,这个指令存在以下限制:
- 不能并行化 while 等其他循环。
- 循环变量必须在循环开始执行前就已经明确,不能为无限循环。
- 不能存在其他循环出口,即不能存在 break、exit、return 等中途跳出循环的语句。
- 在程序执行到该指令时,系统分配一定数量的线程,每个线程拥有自己的循环变量,互不影响,即使在代码中循环变量被声明为共享变量,在该指令中,编译过程仍然会为每一个线程创建一个私有副本这样防止循环变量出现数据依赖,跟在这条指令之后的代码块的末尾存在隐式路障。
- parallel for 指令,用于并行化 for 循环,这个指令存在以下限制:
-
private
-
private 子句可以解决私有变量的问题,该子句就是为每个线程创建一个共享变量的私有副本解决循环依赖,注 private 的括号中可以放置多个变量,逗号分隔
- 关于私有变量还有一下几点 1. 每一个线程都含有自己的私有变量副本 2. 所有线程在 for 循环中不能访问最开始定义的那个全局变量,它们操作的都是自己的私有副本
-
firstprivate
- 告诉编译器,每个线程的私有副本初始化为共享变量的值,只是在每个线程开始执行并行代码块时就分配给私有副本的而不是每次循环迭代分配一次
-
lastprivate
- 告诉编译器,将最后一个离开并行化块的线程的最后一次循环迭代的私有副本赋值给原先的共享变量
-
-
single
- 最先到达的线程执行该子句后面的代码块,其余不执行这个代码块的线程会在代码块的末尾被阻塞(隐式 barriers),等待所有的线程执行到该位置后,继续向后执行,如果在 single 后加上 nowait 指令,则不执行这个代码块的线程不需要等待,继续向后执行
-
master
- 该子句仅有主线程执行后面的代码块,其他线程直接跳过该子句后面的代码块,且不存在隐式 barriers
-
sections
-
#pragma omp sections 在这条指令后的代码块进行串行执行
-
#pragma omp parallel sections 在这条指令后的代码块才是进行并行执行,里面每一个 section 都只需要一个线程去执行,当然如果一个线程足够快允许实现,他可以执行多个 section
#pragma omp parallel sections num_threads(4) { #pragma omp section { ... } } -
-
reduction
- 规约子句
#pragma omp ……reduction<opreation : variable list>-
opreation +、-、* 、& 、 、&& 、 、^ 将每个线程中的变量进行规约操作例如 #pragma omp ……reduction<+ : total>就是将每个线程中的 result 变量的值相加,最后在所有从线程结束后,放入共享变量中,其实这也可以看作是 private 子句的升级版,下面的例子,最后共享的 total 中存入就是正确的值(浮点数数组数字之和),其他操作符的情况可以类比得到
float total = 0.; #pragma omp parallel for reduction(+:total) for (size_t i = 0; i < n; i++) { total += a[i]; } return total; -
#pragma omp barrier
-
4. 熟悉 OpenMP 关键指令的执行过程
-
观察下图中的执行顺序

-
图中的虚线路障是 parallel for 模块所带的隐式路障

第六讲:OpenMP中的竞争和同步
1. OpenMP 中为了保证程序正确性而采用哪些机制
barriers(路障):⼀个同步点,线程组中的每个成员必须在任何成员继续之前到达该同步点,也就是在还有其他线程未到达时,每个线程都将被阻塞
memory fence(内存屏障)
mutual exclusion(互斥):一次只允许单个线程或进程访问共享资源
2. 什么是同步,同步的主要方式有哪些
同步:管理共享资源的过程,以便无论线程如何调度,都以正确的顺序进行读取和写入
方法:barrier、互斥锁、信号量
3. OpenMP Barrier 的执行原理
⼀个同步点,线程组中的每个成员必须在任何成员继续之前到达该同步点,也就是在还有其他线程未到达时,每个线程都将被阻塞
注:parallel for 和 single 都有隐式的 barriers,在它们的代码块结尾的地方,可使用 nowait 禁用掉这个隐式的 barriers
4. OpenMP 中竞争的例子
double area, pni, x;
int i, n;
area = 0.0;
for (i = 0; i <n; i++) {
x = (i + 0.5)/n;
area += 4.0/(1.0 + x*x);
}
pi = area / n;
如果两个线程同时执行 area += 4.0/(1.0 + x*x),可能会在一个线程更新 area 的值之前另一个线程就对 area 进行读操作。
这个for循环的并行会导致竞争的发生,原因是因为多个线程对同一个共享变量访问时间的非确定性导致结果可能出错,多个线程访问area += 4.0 / (1.0 + x*x)就可能导致竞争。
double area, pni, x;
int i, n;
...
area = 0.0;
#pragma omp for
for (i = 0; i <n; i++) {
x = (i + 0.5)/n;
area += 4.0/(1.0 + x*x);
}
pi = area / n;
5. OpenMP 中避免数据竞争的方式有哪些
设置线程专用的范围变量
- 使用 private 子句
- 在线程函数中申明变量
- 在线程堆栈上分配(作为参数传递)
控制关键区域的共享访问,如:互斥和同步
- 变量私有化
- 使用OpenMP的private子句将变量变为私有
- 在线程函数内声明变量,这样变量将属于这个线程
- 在线程堆栈上进行分配
-
将共享变量放置进入临界区
- 互斥访问
- 信号量
- 互斥锁机制
6. OpenMP Critical 与 Atomic 的主要区别是什么
Critical 确保一次只有一个线程执行结构化代码。
atomic 只能用在形如 x = 、x++、x–之类的临界区中,他比普通的临界区执行速度快。
-
#pragma omp critical该指令保护了 1、WorkOne(i)的调用过程,也就是在WorkOne(i)函数内部也是临界区 2、从内存中找到index[i]值的过程 3、将WorkOne(i)的值加到index[i]的过程 4、将内存中index[i]更新的过程 后面跟的语句相当于串行执行。
-
Atomic指令只对一条指令形成临界区,而且语句的格式受到限制1、将WorkOne(i)的值加到index[i] 2、更新内存中index[i]的值 只将单一一条语句设置为临界区。 如果不同线程的index[i]非冲突的话仍然可以并行完成,只有当两个线程的index[i]相等时才会触发使得这两个线程排队执行这条语句
#pragma omp parallel for
{
for(int i = 0; i < n; i++) {
#pragma omp atomic
x[index[i]] += WorkOne(i);
y[i] += WorkTwo(i);
}
}
第七讲:OpenMP性能优化
1. 什么是计算效率
核心利用率的衡量标准,计算公式为加速比/核心数
加速比:Speedup = 串行执行时间/并行执行时间
2. 调整后的 Amdahl 定律如何理解
原来的 Amdahl 定律过于乐观
- 忽略了并行处理的开销,如创建/终止线程。而并行处理开销一般是关于线程数(核心 数)的增函数。
- 忽略了计算量难以均衡地分配到每个核心上,负载不均衡以及核心等待时间都是一种开销。
所以进行Amdahl公式的改进,加上线程开销部分, 为了获得最大的加速比,我们就需要将并行开销尽可能减小,同时使用更多的核,改进后的公式如下所示
n 问题规模
p 核心数
S(n,p) 问题的加速比
Ts(n) 串行部分的时间花费
Tp(n) 并行部分的时间花费
Tr(n,p) 并行开销
S(n,p)<=( Ts(n)+Tp(n) )/( Ts(n)+Tp(n)/p+Tr(n,p) )
最大加速比:
Tp(n)/p:假设并行计算部分可以在核心完美分配
Tr(n,p)趋向于0
加速比是关于问题规模的递增函数
- 如下图表示当我们的问题规模达到一定程度后,并行程序的加速比主要由并行部分来决定,因为随着问题规模的增加,程序串行部分也会逐渐较少,同时并行部分将占据主要时间,可以忽略掉串行时间的影响,加速比主要由并行部分决定
3. OpenMP 中 Loop 调度的几种方式,执行过程
- Static schedule
- 循环执行前把迭代分配给线程
- schedule (static [, chunk])
- 每个分配给线程的迭代块的计算量「chunk」
- 轮循分配 T1,T2,T3,T1,T2,T3……
- 低开销,但可能会负载不平衡
- 适用于可预见和简单的循环

- Dynamic schedule

#pragma omp parallel for shedule(dynamic, 2)
- 循环的执行期间把迭代分配给线程
- schedule (dynamic [, chunk])
- 线程获取任务块chunk
- 当迭代完成后,请求下一组任务
- 较高的线程开销,但可以做到负载均衡
- 适用于不可预知或高度可变的循环
- Guided schedule

- 调度顺序以及任务块大小,如:T1(1 block),T2(0.5 block),T3(0.25 Block),T3(0.125 block)……
- schedule (guided [, chunk])
- 以较大的任务块开始动态调度
- 任务块大小减小,但任务块大小有下界
- 开始时块大小
- number_of_iterations / number_of_threads 总任务/线程数
- 后续块大小
- number_of_iterations_remaining / number_of_threads 当前任务/线程数
- 最好用作动态的特殊情况,以在计算越来越耗时的情况下减少调度开销
- OpenMP 的调度方案,影响着循环迭代映射到线程的方式 动态调度:在执行循环期间分配线程的迭代次数 静态调度:在执行循环前分配线程的迭代次数
- shedule(type[ , chunksize])子句是进行循环调度的指令
4. OpenMP 中 Loop 转换的方式包括哪几种
- Loop fission——循环拆分
- 从具有循环依赖的单循环开始
- 把循环拆成两个或多个循环
- 新的循环可以并行执行
- Loop fusion——循环合并
- 与循环拆分相反
- 合并循环以增加粒度
- 循环合并和操作转换(改变操作使得结果相同但更简单)
- 每个线程的迭代是有开销的
- 比如:同步时使用的 barrier
- 有时候,改变操作以避免 barrier 和 foo 是要执行得更快
- Loop exchange(Inversion)——循环交换(反转)
-
嵌套 for 循环可能具有阻止并行化的数据依赖关系
-
交换的嵌套 for 循环可以
-
使循环可以并行
-
提高操作粒度
-
提高并行程序的局部性
- 直接并行
for (int j =1; j < n; j++) #pragma omp parallel for for (int i = 0; i < m; i++) a[i][j] = 2 * a[i][j-1];并行结果如下,数组每一列数据交给线程组进行并行化,一个线程一次得到的任务只有数组中一个元素,频繁的进行划分可能导致并行开销增大

- Loop exchange 后并行
#pragma omp parallel for for (int i =1; i < n; i++) for (int j= 0; j < m; j++) a[i][j] = 2 * a[i][j-1];并行结果如下,直接将整个数组按行划分给线程,一个线程一次得到的任务有一行的,并行循环粒度较高

-
第八讲:MPI 编程模型,内容要点
1. 什么是 MPI 编程模型
每个独立的处理器都有独立私有的内存,通过互联网络连接起来的分布式内存系统,利用消息传递来编程的模型。
MPI 是一个跨语言(编程语言如 C, Fortran 等)的通讯协议,用于编写并行计算机。支持点对点和广播。MPI 是一个信息传递应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。MPI 的目标是高性能,大规模性,和可移植性。MPI 在今天仍为高性能计算的主要模型。与 OpenMP 并行程序不同,MPI 是一种基于信息传递的并行编程技术。消息传递接口是一种编程接口标准,而不是一种具体的编程语言。简而言之,MPI 标准定义了一组具有可移植性的编程接口。
2. 消息传递性并行编程模型的主要原则是什么
(1)支持消息传递模型的系统的逻辑由 p 个处理器组成,每个处理器都有自己专用的地址空间
(2)限制
- 每个数据元素必须属于某一个处理器的内存空间;因此,必须显式分区和放置数据。
- 拥有数据的进程和想要访问数据的进程的所有交互(只读或读/写)都需要两个进程的协作
(3)这两个约束虽然很繁重,但却使底层成本对程序员非常明确。
(4)消息传递程序通常使用异步或松散同步的范例编写。
-
在异步模式中,所有并发任务都是异步执行的。
-
在松散同步模型中,任务或任务子集同步以执行交互。在这些交互之间,任务完全异步执行
(5)大多数消息传递程序是使用单程序多数据(SPMD)模型编写的。
3. MPI 中的几种 Send 和 Receive 操作包括原理和应用场景
(1)Non-buffered blocking(无缓冲阻塞)
- 强制 send/recv 语句的一个简单方法是 send 操作仅在安全时返回
- 在非缓冲阻塞 send 中,知道在传输过程中遇上匹配的 recv,操作返回
- 空等、死锁问题存在
- 应用场景:用于阻塞非缓冲发送/接收操作的握手。很容易看出,在发送方和接收方没有同时到达通信点的情况下,可能会有相当大的空闲开销。
(2)Buffered blocking(缓冲区阻塞)
- 在缓冲块发送中,发送方只需将数据复制到指定的缓冲区中,并在复制操作完成后返回。数据也被复制到接收端的缓冲区中。
- 缓冲减少了空转的开销,而增加了复制开销。
- 由于接收操作阻塞,使用缓冲仍然可能出现死锁。
应用场景:阻塞缓冲传输协议:(a) 在发送端和接收端有缓冲区的通信硬件存在的情况下; (b) 在没有通信硬件的情况下,发送方中断接收方并将数据存放在接收方的缓冲区中。
注意:
- 缓冲区大小可能对性能影响显著
- 由于接受操作块(send-recv)的存在,使用缓冲块仍然可能出现死锁
(3)Non-blocking (非阻塞)
- 程序员必须确保发送和接收的语义正确。
- 这类非阻塞协议在语义上安全之前从发送或接收操作返回。
- 非阻塞操作通常伴随检查状态操作。
- 如果使用正确,这些原语的通信开销可以与计算开销重叠起来
- 消息传递库通常同时提供阻塞原语和非阻塞原语。
应用场景:非阻塞非缓冲发送和接收操作 (a) 在没有通信硬件的情况下; (b) 在存在通信硬件的情况下。
(4)MPI 的 send
- MPI_Send(标准模式)有缓存使用缓存,无缓存显式等待
- 不会返回,直到可以使用缓存
- MPI_Bsend(缓冲模式)
- 立即返回和可以使用发送缓冲
- Related: MPI_buffer_attach(), MPI_buffer_detach()
- MPI_Ssend(同步模式)需要多次握手
- 不会返回,直到匹配上 recv
- 发送+同步通信语义
- MPI_Rsend(就绪模式)减少通信信息
- 当且仅当匹配的 recv 已经准备好了则可以使用
- 发送者提供了额外的信息系统,可以节省部分开销
- MPI_Isend(非阻塞标准模式)
- 不能立即重用 send 缓冲区
- Related: MPI_Wait(), MPI_Test()
- MPI_Ibsend
- MPI_Issend
- MPI_Irsend
(5)发送和接受消息
int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
- MPI 允许为源和标记指定通配符参数。
- 如果 source 设置为 MPI_ANY_SOURCE,则通信域的任何进程都可以是消息的源。
- 如果标记设置为 MPI_ANY_TAG 标记,则接受带有任何标记的消息。
- 在接收端,消息的长度必须等于或小于指定的长度字段。
- 在接收端,状态变量可用于获取有关 MPI_recv 操作的信息。
- 相应的数据结构包含
typedef struct MPI_Status {
int MPI_SOURCE;
int MPI_TAG;
int MPI_ERROR; };
- 函数返回接收到的数据项的精确计数。
int MPI_Get_count(MPI_Status *status, MPI_Datatype datatype, int *count)
4. MPI 中的关键编程接口
- MPI_Init(int* argc,char*** argv):在调用其他 MPI 例程之前调用,其目的是初始化 MPI 环境。
- MPI_Finalize():在计算结束时调用,它执行各种清理任务以终止 MPI 环境。
- MPI_Comm_size(MPI_COMM_WORLD, &comm_size);
- MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
- int MPI_Get_count(MPI_Status *status, MPI_Datatype datatype, int *count):返回接收到的数据项的精确计数
- 相关进程形成进程组
MPI_Group_incl():进程集形成一个进程组
MPI_Comm_create():为新的进程组创建一个通信子
MPI_Comm_rank():为新的进程组定义序号
MPI_Comm_free():释放进程组的资源
MPI_Group_free():解进程组
5. 什么是通信子
- 通信子定义了一个通信域 - 允许彼此通信的一组进程。
- 有关通信域的信息存储在 MPI_Comm 类型的变量中
- 通信子被用作所有消息传输 MPI 例程的参数。
- 一个进程可以属于许多不同的(可能重叠的)通信域
- MPI 定义了一个名为 MPI_COMM_WORLD 的默认通讯子,其中包括所有进程
6. MPI 中解决死锁的方式有哪些
-
使用非阻塞操作可以避免大多数死锁:为了与计算重叠通信,MPI 提供了一对执行非阻塞发送和接收操作的函数MPI_Isend() 和 MPI_Irecv()。这些操作在操作完成之前返回。函数 MPI_Test 测试其请求标识的非阻塞发送或接收操作是否完成:
int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status) int MPI_Wait(MPI_Request *request, MPI_Status *status) -
可以打断循环等待以避免死锁:if (myrank % 2 == 1) …
-
同时 send 和 recv:MPI_Sendrecv()
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype senddatatype, int dest, int sendtag, void *recvbuf, int recvcount, MPI_Datatype recvdatatype, int source, int recvtag, MPI_Comm comm, MPI_Status *status) int MPI_Sendrecv_replace(void *buf, int count, MPI_Datatype datatype, int dest, int sendtag, int source, int recvtag, MPI_Comm comm, MPI_Status *status)
7. MPI 中的集群通信操作子有哪些,原理是什么
- MPI 提供了一套广泛的函数来执行公共的集体通信操作
- 这些操作都是在通信子对应的一个进程组上定义的
- 在同一个通信子中的处理器必须调用这些操作
- 屏障同步操作在 MPI 中使用:
int MPI_Barrier(MPI_Comm comm)\\阻塞到所有进程完成调用
- one-to-all 广播操作:
int MPI_Bcast(void *buf, int count, MPI_Datatype datatype, int source, MPI_Comm comm)
- all-to-one 规约操作:
int MPI_Reduce(void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int target,
MPI_Comm comm)
-
集群通信操作
- 如果所有进程都需要归约操作的结果,MPI 提供:
int MPI_Allreduce(void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm) -
为了计算前缀和,MPI 提供
int MPI_Scan(void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm) -
gather操作:
int MPI_Gather(void *sendbuf, int sendcount, MPI_Datatype senddatatype, void *recvbuf, int recvcount, MPI_Datatype recvdatatype, int target, MPI_Comm comm) -
MPI 还提供了 MPI_Allgather 函数,其中在所有进程中收集数据。
int MPI_Allgather(void *sendbuf, int sendcount, MPI_Datatype senddatatype, void *recvbuf, int recvcount, MPI_Datatype recvdatatype,MPI_Comm comm) -
对应的散射操作是
int MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype senddatatype, void *recvbuf, int recvcount, MPI_Datatype recvdatatype, int source, MPI_Comm comm)
第九讲:MPI 与 OpenMP 联合编程
1. 如何利用 MPI 实现 Matrix-vector 乘积,不同实现的特点是什么
假设运算为 A*b=c,其中 A 为矩阵,b、c 为向量
(1)Rowwise Block Striped Matrix —— 行分块条形矩阵
-
通过域分解划分
-
原始任务关联:矩阵的行、整个向量
-
此时为 A 的第 i 行乘以 b 得到 c[i],在 All-gather communication 得到结果
-
有时会出现每个进程的结果个数不一样,所以不能使用 MPI_gather(因为要求每个进程的传输个数一样),所以使用 MPI_Allgatherv。
//收集所有任务的数据并将组合数据传送到所有任务 int MPI_Allgatherv(const void * sendbuf,int sendcount,MPI_Datatype sendtype, void * recvbuf,const int * recvcounts,const int * displs, MPI_Datatype recvtype,MPI_Comm comm) sendbuf:要发送内容的起始地址 sendcount:要发送的数量 recvbuf:接收数据要存放的单元的地址 recvcounts:这是一个整数数组,包含从每个进程要接收的数据量,比如{0, 1} 从0号进程接收0个,从1号进程接收1个 displs:这是一个整数数组,包含存放从每个进程接收的数据相对于recvbuf的偏移地址 -
合并与映射
- 任务数量为静态划分、规则化通信、每个任务的执行时间为常量
- 策略:
- 多行合并为一个子任务 —— 减少通信
- 为每个 MPI 进程创建一个任务,分配子任务
(2)Columnwise Block Striped Matrix —— 列分块条形矩阵
- 通过域分解进行划分
- 原始任务关联:矩阵的列、整个向量
- 此时为 A 的第 i 列乘以 b[i]。一般的做法为行列转置,即把结果部分c[i]由不连续存储的列元素变成连续存储的行形式表示,再统计获得最终结果。
- 合并与映射
- 任务数量为静态划分、规则化通信、每个任务的执行时间为常量
- 策略
- 把部分列元素作为一个子任务
- 为每个 MPI 进程创建一个任务,分配子任务
(3)Checkerboard Block Decomposition —— 块划分
-
将原始任务与矩阵 A 的每个元素关联起来
-
每个基本任务执行一次乘法
-
将原始任务聚合成矩形块
-
流程形成二维网格
-
向量 B 在网格第一列的进程之间按块分布
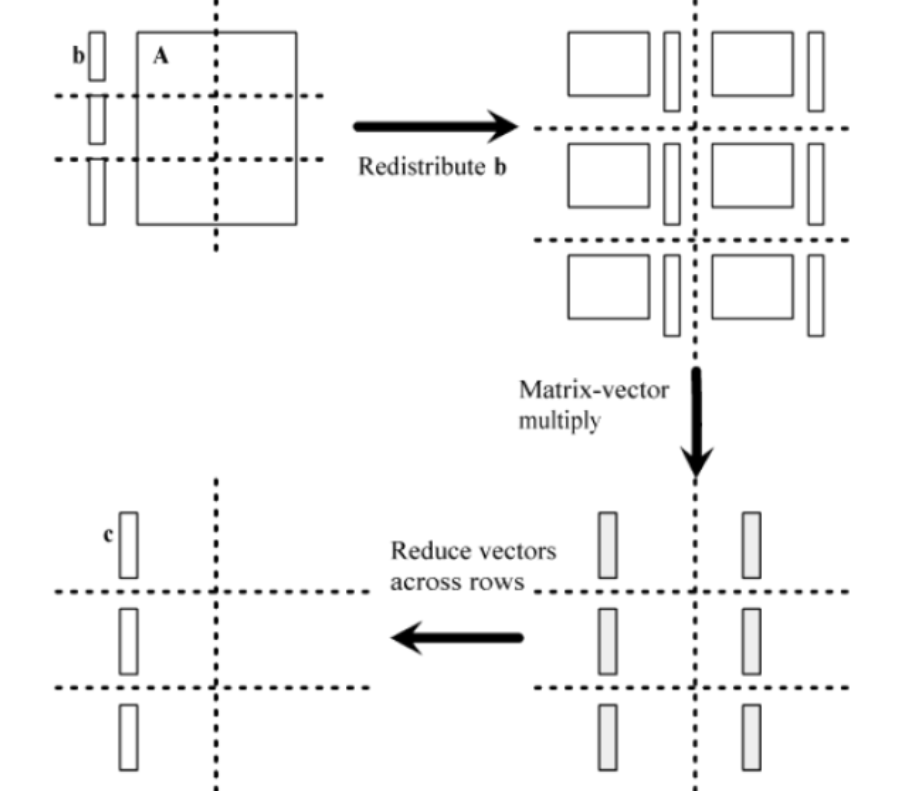
-
再分配向量 b
- 步骤 1:将 b 从进程的第一行移动到进程的第一列
- 如果p是平方数:第一列/第一行进程发送/接收 b 的部分
- 如果p不是平方数:在进程0 gather b,进程0广播到第一行的进程
- 步骤 2:把第一行映射到其他行
- 步骤 1:将 b 从进程的第一行移动到进程的第一列
2. MPI 和 OpenMP 结合的优势是什么
MPI + OpenMP 可以执行的更快
- 更低的通讯开销
- mk个进程的消息传递, versus
- m个进程,每个进程k个线程的消息传递
- 更多的部分可以并行
- 通讯开销与计算开销重合的部分更多
- 混合了轻量级线程和重量级进程
3. 如何利用 MPI+OpenMP 实现高斯消元
- 稀疏系统
- 高斯消元并不适用于稀疏系统
- 系数矩阵逐渐填充非零元素
- 增加存储要求
- 增加总操作数
- 迭代法
- 迭代法:生成一系列近似解值的算法
- 需要的存储量比直接方法少
- 由于它们避免了零元素的计算,因此可以节省大量的计算。
- 方法
- MPI 执行配置操作的指令
- 专注于将 OpenMP 指令添加到大多数计算密集型功能中
double det = 1;
for (int i = 0; i < n; ++i) {
int k = i;
for (int j = i + 1; j < n; ++j)
if (abs(a[j][i]) > abs(a[k][i])) k = j;
if (abs(a[k][i]) < EPS) {
det = 0;
break;
}
swap(a[i], a[k]);
if (i != k) det = -det;
det *= a[i][i];
for (int j = i + 1; j < n; ++j) a[i][j] /= a[i][i];
for (int j = 0; j < n; ++j)
if (j != i && abs(a[j][i]) > EPS)
for (int k = i + 1; k < n; ++k) a[j][k] -= a[i][k] * a[j][i];
}
第十讲:GPGPU、CUDA 和 OpenCL 编程模型
1. CUDA 的含义是什么
CUDA: Compute Unified Device Architecture(计算统一设备架构)
为跨各种处理器的数据并行编程提供内在可扩展的环境。
2. CUDA 的设计目标是什么,与传统的多线程设计有什么不同
目标:提供环境
-
为跨多种处理器的数据并行编程提供内在可扩展的环境。
-
使 SIMD 硬件对通用程序员可访问。否则,大部分可用的执行硬件都会被浪费掉!
目标:可扩展性
- Cuda 表达了许多可以按任何顺序运行的独立计算块
- Cuda 编程模型的大部分固有可扩展性源于“线程块”的批量执行
- 在同代GPU之间,许多程序在具有更多“核心”的GPU上实现线性加速
目标:SIMD编程
- 硬件架构师喜欢 SIMD,因为它允许非常节省空间和节能的实施
- 但是,CPU 上的标准 SIMD 指令不灵活,难以使用,编译器难以定位
- Cuda 线程抽象将以增加硬件为代价提供可编程性
与传统多线程设计的区别
- 使用单程序多数据(SPMD)编程模型编写的 GPU 程序(内核)。
- SPMD 独立执行同一程序的多个实例,其中每个程序处理数据的不同部分。
- 对于数据并行的科学和工程应用,将 SPMD 与循环条带挖掘相结合是一种非常常见的并行编程技术。
- 消息传递接口(MPI)用于在分布式集群上运行 SPMD。
- POSIX 线程(p 线程)用于在共享内存系统上运行 SPMD。
- 内核在 GPU 中运行 SPMD
- 在向量相加的示例中,每个数据块都可以作为一个独立的线程执行。
- 在现代 CPU 上,创建线程的开销是如此之高,以至于块需要很大。
- 在实践中,通常有几个线程(大约相当于 CPU 核心的数量),每个线程都有大量的工作要做。
- 对于 GPU 编程,线程创建的开销较低,因此我们可以在每次循环迭代中创建一个线程。
3. 什么是 CUDA kernel
运行在设备上的 SPMD 核函数。
一个 kernel 结构如下:Kernel<<<Dg, Db, Ns, S>>>(param1, param2, ...)
- Dg:grid 的尺寸,说明一个 grid 含有多少个 block,为 dim3 类型,一个 grid 最多含有 65535*65535*65535 个 block,Dg.x,Dg.y,Dg.z 最大值为 65535;
- Db:block 的尺寸,说明一个 block 含有多上个 thread,为 dim3 类型,一个 block 最多含有 1024个 threads,Db.x 和 Db.y 最大值为 1024,Db.z 最大值 64; (举个例子,一个 block 的尺寸可以是:
1024*1*1 | 256*2*2 | 1*1024*1 | 2*8*64 | 4*4*64等) - Ns:可选参数,如果 kernel 中由动态分配内存的 shared memory,需要在此指定大小,以字节为单位;
- S:可选参数,表示该 kernel 处在哪个流当中。
4. CUDA 的编程样例
CUDA 的操作概括来说包含 5 个步骤:
- CPU 在 GPU 上分配内存:cudaMalloc;
- CPU 把数据发送到 GPU:cudaMemcpy;
- CPU 在 GPU 上启动内核(kernel),它是自己写的一段程序,在每个线程上运行;
- CPU 把数据从 GPU 取回:cudaMemcpy;
- CPU 释放 GPU 上的内存:cudaFree。
其中关键是第 3 步,能否写出合适的 kernel,决定了能否正确解决问题和能否高效的解决问题。
5. CUDA 的线程分层结构
Cuda 对线程做了合适的规划,引入了 grid 和 block 的概念,block 由线程组成,grid 由 block 组成,一般说 blocksize 指一个 block 放了多少 thread;gridsize 指一个 grid 放了多少个 block。
Cuda 编程模型中的并行性被表示为一个 4 层的层次结构。
- 流(Stream)是按顺序执行的 Grid 列表。Fermi GPU 并行执行多个流。
- 网格(Grid)是一组最多$2^{32}$个执行同一内核的线程块。
- 线程块是一组最多 1024(512 per-Fermi)Cuda 线程。
- 每个 cuda 线程都是一个独立的、轻量级的标量执行上下文。
- 32 个线程组成的组形成在 lockStep SIMD 中执行的Warps。
CUDA Thread
- 逻辑上,每个 CUDA 线程:
- 有自己的控制流程和 PC,注册文件,调用堆栈。
- 可以随时访问任何 GPU 全局内存地址。
- 可通过以下五个整数在网格中唯一标识:线程标识。{x,y,z},块标识。{x,y}。
- 非常精细的粒度:不要指望任何一个线程都能完成昂贵的计算中的很大一部分。
CUDA Warp
- CUDA 处理器的逻辑 SIMD 执行宽度。
- 一组同时执行的 32 个 CUDA 线程。
- 当Warp中的所有线程从同一台 PC 执行指令时,执行硬件的使用效率最高。
- 如果Warp中的线程发散(执行不同的 PC),则某些执行流水线将未使用(预测)。
- 如果Warp访问中的线程对齐了 DRAM 的连续块,则将访问合并(合并)为单个高带宽访问。
- 通过将线程索引除以 32 来唯一标识。
- 从技术上讲,Warp 的大小在未来的体系结构中可能会发生变化
- 但许多现有的程序将会中断。
Cuda Thread Block
- 线程块是虚拟化的多线程内核。
- 在内核调用时动态配置标量线程、寄存器和_共享内存的数量。
- 由 CudaThread 的一个数字(1-1024)组成,这些线程共享整数标识符 blocladx。{x,y}。
- 执行中等粒度的数据并行任务。
- 受 GPU DRAM 容量限制的不可缓存工作集。
- 块中的所有线程共享(小型)指令缓存。
- 块中的线程通过屏障-内部同步,并通过快速的片上共享内存进行通信
Cuda Grid
- 一组执行相关计算的线程块。
- 单个内核调用中的所有线程都具有相同的入口点和函数参数,最初仅在 block Idx 中有所不同。{x,y}。
- 网格中的线程块可以执行它们想要的任何代码,例如 Switch(block Idx.x)不会受到额外的惩罚。
- 性能、可移植性/可扩展性要求每个网格有多个数据块:在每个 SM 上执行 1-8 个数据块。
- 内核调用的线程块必须是并行子任务。
- 程序必须对块执行的任何交错有效。
- 内存系统的灵活性在技术上允许线程块以任意方式进行通信和同步。
- 共享队列索引:好的!生产者-消费者:风险!
Cuda Stream
- 按顺序执行的一系列命令(内核调用、内存传输)。
- 要同时执行多个内核调用或内存传输,应用程序必须指定多个流。
- 并发内核执行只会发生在 Fermi 和更高版本上
- 在 pre-Fermi 设备上,内存传输将与内核同时执行。
6. CUDA 的内存分层结构
- 每个 CUDA 线程都可以私有地访问可配置的寄存器数量
- 每个线程块都可以私有地访问可配置数量的暂存盘内存
- 所有网格中的线程块共享对大型「全局」内存池的访问权限,这些内存池与主机 CPU 的内存分开。
- 全局内存保存应用程序的持久状态,而线程本地和块本地内存是临时的
- 在 Fermi 上,全局内存缓存在 768KB 共享 L2 中。
- 由于 CUDA 的图形分层,内存层次结构中存在其他只读组件。
- 64 KB cuda 常量内存与全局内存驻留在同一 DRAM 中,但通过特殊的只读 8 KB per SM 缓存进行访问。
- cuda 纹理内存也驻留在 dram 中,可以通过小的 per-sm 只读缓存进行访问,但也包括插值硬件。
- 此硬件对于图形性能至关重要,但仅偶尔对通用工作负载有用。
- 系统中的每个 CUDA 设备都有自己的全局内存,独立于主机 CPU 内存-通过 cudaMalloc()/cudafree()和 Friend()分配。
- 主机 <-> 设备内存传输是通过 cudaMemcpy()通过 PCI-E 进行的,并且是非常昂贵的
- 通过多个 CPU 线程管理多个设备
7. CUDA 中的内存访问冲突
- 共享内存被存储:它由 32 个(16 个,pre-Fermi)独立可寻址的 4 字节宽内存组成
- 地址交错:float *p 指向 bank k 中的浮点数,p+1 指向 bank (k+1) mod 32 中的浮点数
- 每个 bank 可以满足每个周期的单个 4 字节访问
- 当两个线程(在同一个 warp 中)尝试在给定周期内访问同一个 bank 时,就会发生 bank 冲突
- GPU 硬件会串行执行这两个访问,warp 的指令将需要一个额外的周期来执行
- 存储区冲突是二阶性能影响:即使是对片上共享内存的串行访问也比对片外 DRAM 的访问要快
使用块共享内存
原子内存操作
强制内存一致性
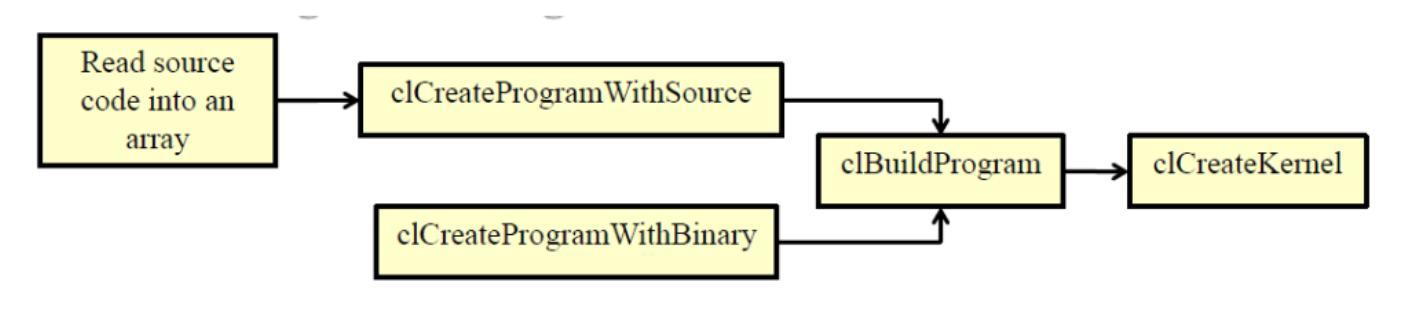
8. OpenCL 运行时编译过程
编译程序和创建内核的开销很大:每个操作只需执行一次(在程序开始时),通过设置不同的参数,内核对象可以被多次重用。
Running time
- 加载 OpenCL 内核程序并创建一个 program 对象
- 为指定的 device 编译 program 中的 kernel
- 创建指定名字的 kernel 对象
- 为 kernel 创建内存对象
- 为 kernel 设置参数
- 在指定的 device 上创建 command queue
- 将要执行的 kernel 放入 command queue
- 将结果读回 host
第十一讲:MapReduce 并行编程模型
MapReduce
- 一种简单而强大的接口,可实现大规模计算的自动并行化和分布,并可在大型商品 PC 集群上实现高性能。
- 更简单地说,MapReduce 是一种并行编程模型及其相关实现
1. 为什么会产生 MapReduce 并行编程模型
- 全社会数据产生的速度非常快
- 大数据的呈现出指数增长速度
动机:大规模数据处理。
- 要处理大量数据(>1TB)。
- 希望跨数百/数千个 CPU 并行化。
- 想让这件事变得简单
2. MapReduce 与其他并行编程模型如 MPI 等的主要区别是什么
OpenMP采用共享存储,意味着它只适应于SMP,DSM机器,不适合于集群;MPI虽适合于各种机器,但它的编程模型复杂。
与OpenMP,MPI相比,MapReduce的优势:自动并行;容错;MapReduce学习门槛低。
-
MapReduce job可以起很多instance,各个instance在计算的过程中互不干扰。比如,用户起了10000个instance,如果集群资源不足,Job不需要等待,可以先执行1000个instance,剩余的等到集群有资源的时候再计算。
-
MapReduce job没有instance间通信开销。
-
如果MapReduce Job的某个instance计算failed,调度系统会自动重试,再次计算,并不影响其他结果,也不需要所有instance重新计算。
与MPI相比,MapReduce的缺点是:MapReduce job的计算的中间结果是以文件形式存储,效率较低。
3. MapReduce 的主要流程是什么
- 使用特殊 map()和 reduce()函数处理数据。
- 对输入中的每个项调用 map()函数,并发出一系列中间键/值对。
- 将与给定键关联的所有值组合在一起。
- 对每个唯一的键及其值列表调用 reduce()函数,并发出一个添加到输出中的值
- 对输入中的每个项调用 map()函数,并发出一系列中间键/值对。
Map
- 将来自数据源的记录(文件的行数、数据库的行数等)作为 键*值 对输入到 map 函数中:例如(文件名、行)。
- map()从输入生成一个或多个中间值以及输出键
Reduce
- 映射阶段结束后,给定输出键的所有中间值将合并到一个列表中。
- Reduce()将这些中间值组合为同一输出键的一个或多个终值
4. MapReduce 的简单实现,如 Hello World 例子

5. MapReduce 具有哪些容错措施
- Master 检测工人故障。
- 重新执行已完成和正在进行的 map()任务。
- 重新执行正在进行的 reduce()任务。
- Master 在 map()中注意到特定的输入键/值导致崩溃,并在重新执行时跳过这些值。
- 效果:可以解决第三方库中的错误!
6. MapReduce 存在哪些优化点
- 在 map 完成之前,不能开始 reduce。
- 单个慢速磁盘控制器可以对整个过程进行速率限制。
- Master 冗余地执行「缓慢移动」的 map 任务;使用第一次复制的结果来完成。
- 「组合器」函数可以像映射器一样在同一台计算机上运行。
- 导致在实际减少阶段之前出现一个小减少阶段,以节省带宽
7. MapReduce 可以解决的问题有哪些
大大降低了并行编程的复杂性
- 降低同步复杂性。
- 自动划分数据。
- 提供故障透明度。
- 处理负载平衡
MapReduce解决的典型问题
- 阅读大量数据。
- Map:从每条记录中提取您关心的内容。
- 洗牌和排序。
- 减少:聚合、汇总、筛选或转换。
- 写下结果。
- 大纲保持不变,但映射并减少更改以适应问题
第十二讲:基于 Spark 的分布式计算
它扩展了广泛使用的 MapReduce 计算模型。高效的支撑更多计算模式,包括交互式查询和流处理。spark 的一个主要特点是能够在内存中进行计算,及时依赖磁盘进行复杂的运算,Spark 依然比 MapReduce 更加高效。
1. Spark 与 Hadoop 的区别和联系
区别:
1)应用场景不同
Hadoop和Spark两者都是大数据框架,但是各自应用场景是不同的。Hadoop是一个分布式数据存储架构,它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,降低了硬件的成本。Spark是那么一个专门用来对那些分布式存储的大数据进行处理的工具,它要借助hdfs的数据存储。
2)处理速度不同
hadoop的MapReduce是分步对数据进行处理的,从磁盘中读取数据,进行一次处理,将结果写到磁盘,然后在从磁盘中读取更新后的数据,再次进行的处理,最后再将结果存入磁盘,这存取磁盘的过程会影响处理速度。spark从磁盘中读取数据,把中间数据放到内存中,完成所有必须的分析处理,将结果写回集群,所以spark更快。
3)容错性不同
Hadoop将每次处理后的数据都写入到磁盘上,基本谈不上断电或者出错数据丢失的情况。Spark的数据对象存储在弹性分布式数据集 RDD,RDD是分布在一组节点中的只读对象集合,如果数据集一部分丢失,则可以根据于数据衍生过程对它们进行重建。而且RDD 计算时可以通过 CheckPoint 来实现容错。
联系:
两者完全可以结合在一起,hadoop提供分布式集群和分布式文件系统,spark可以依附在hadoop的HDFS代替MapReduce弥补MapReduce计算能力不足的问题。
2. 传统 MapReduce 的主要缺点是什么
MapReduce 在单程计算方面很好,但对于多路算法效率较低。没有有效的数据共享原语。
- 步骤之间的状态转到分布式文件系统。
- 由于复制和磁盘存储而速度较慢
3. Spark 中的 RDD 如何理解
- RDD 是 Spark 的核心数据模型,但是个抽象类,全称为 Resillient Distributed Dataset,即弹性分布式数据集。
- RDD 在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同节点上,从而让 RDD 中的数据可以被并行操作。(分布式数据集)
- RDD 通常通过 Hadoop 上的文件,即 HDFS 文件或者 Hive 表,来进行创建;有时也可以通过应用程序中的集合来创建。
- RDD 最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的 RDDpartition,因为节点故障,导致数据丢了,那么 RDD 会自动通过自己的数据来源重新计算该 partition。这一切对使用者是透明的。
- RDD 的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark 会自动将 RDD 数据写入磁盘。(弹性)
4. Spark 样例程序
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")
第十三讲:离散搜索与负载均衡
1. 深度优先搜索的主要流程
从图中某顶点 v 出发:
1)访问顶点 v;
2)依次从 v 的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和 v 有路径相通的顶点都被访问;
3)若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
回溯发生在以下情况:
-
节点没有子节点(“死端”)
-
节点的所有子节点都已探索
2. 深度优先搜索的复杂度
假设状态空间树中的平均分支因子(每个节点的子节点数(平均值))为 b,搜索一棵深度为 k 的树需要检索:$1+b+b^{2}+\cdots+b^{k}=\frac{b^{k+1}-b}{b-1}+1=\theta\left(b^{k}\right)$个结点。
空间复杂度为 Θ(k)
3. 并行深度优先搜索的主要设计思想
每个处理器处理一个子树。
半拆分:理想情况下,堆栈被拆分为两个相等的部分,以便每个堆栈的搜索空间相同。
截止深度:为了避免发送非常少量的工作,不会给出超过指定堆栈深度的节点。
-
发送堆栈底部附近的结点:适用于均匀搜索空间;分配成本低。
-
发送截止深度附近的结点:使用强启发式(尝试分配搜索空间中可能包含解决方案的部分)可以获得更好的性能。
-
发送底部和截止深度之间的一半结点:适用于均匀不规则的搜索空间。
4. 动态负载均衡的三种方法,以及每种方法的额外开销复杂度
均衡负载
- Asynchronous round robin(ARR),异步循环,每个进程维护一个计数器并以循环方式发出请求。
- Global round robin(GRR),全局循环,系统维护一个全局计数器,并以循环方式在全局发出请求。
- Random polling(RP),随机轮询,请求随机选择的工作流程。
额外开销复杂度
串行复杂度$W$,并行复杂度$pW_p$,额外开销:$T_O=pW_p-W$
我们将$v(p)$定义为每个处理器在收到至少一个工作请求之后的工作请求总数;假设任意点的最大工作量是$W$;则工作请求总数为$O(V(p)\text{log}W)$。
ARR:V(p) = O(p²)在最坏情况下
GRR:V(p) = p
RP:最坏情况下 V(p)是无穷的。 平均状况下 V(p) = O(plogp)
ARR:W = O(p²logp)
GRR:最坏情况下 W = O(p²logp)
RP:W = O(plog²p)
ARR 性能较差,因为它会发出大量的工作请求。
GRR 调度由于计数器上的争用而性能较差,尽管它发出的请求数最少。
RP 是一个理想的折衷办法。
5. 最优搜索的处理过程
最佳优先搜索算法在广度优先搜索的基础上,用启发估价函数对将要被遍历到的点进行估价,然后选择代价小的进行遍历,直到找到目标节点或者遍历完所有点,算法结束。

6. 并行最优搜索的主要思想和实现方式
主要思想:
单个优先队列:通信开销太大;访问队列是一个性能瓶颈;不允许问题大小随处理器数量而扩展
多个优先队列:每个进程维护一个单独的未检查子问题优先队列;每个进程检索具有最小下限的子问题以继续搜索;有时进程会将未经检查的子问题发送给其他进程
-
核心数据结构是开放列表(通常作为优先级队列实现)。
-
每个处理器锁定此队列,提取最佳节点,然后解锁它。
- 生成节点的后续节点,估计其启发式函数,并在适当锁定后根据需要将节点插入开放列表。
- 当我们找到一个成本高于开放列表中最佳启发式值的解决方案时,就发出终止信号。
- 因为我们一次扩展多个节点,所以我们可能会扩展无法通过顺序算法扩展的节点。
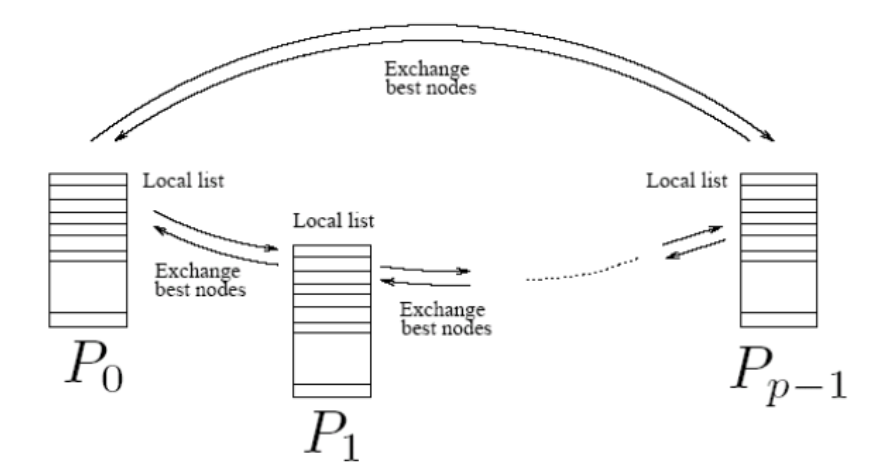
实现方式(通信策略):随机通信、环通信、blackboard通信
环通信:
blackboard通信:
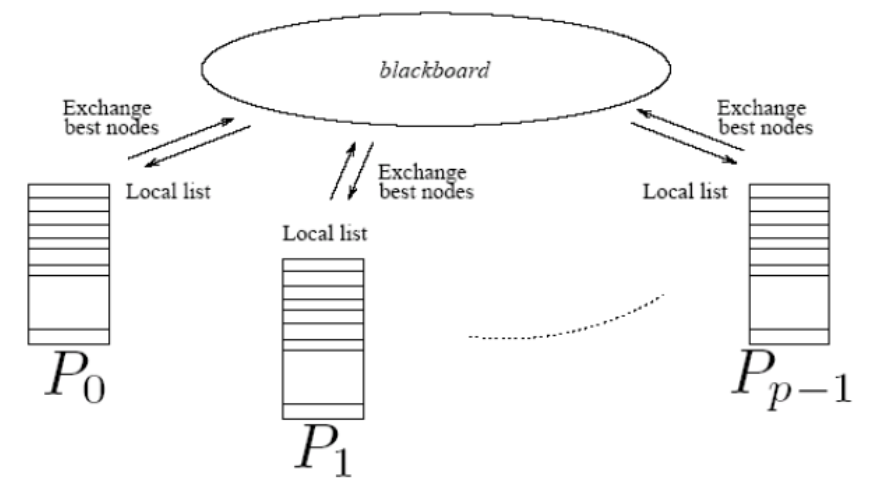
7. 什么是加速比异常,主要分哪几类
由于处理器探索的搜索空间是在运行时动态确定的,实际工作可能会有很大的差异。
使用 P 处理器产生大于 P 的加速比的执行被称为加速比异常。使用 P 处理器的小于 P 的加速比被称为减速比异常。
DFS的顺序和并行公式搜索的节点数的差异会造成影响。
第十四讲:并行图算法
1. 最小生成树的串行和并行算法原理
串行:Prim
-
求 MST 的 Prim 算法是一种贪婪算法。
-
首先选择一个任意的顶点,将它包含到当前的 MST 中。
-
通过插入最接近其中一个的顶点来增长当前 MST 顶点已经在当前 MST 中。
算法流程
- 在连通网的顶点集合 V 中,任选一个顶点, 构成最小生成树的初始顶点集合 U;
- 在 U 和 V-U 中各选一个顶点,使得该边的权值最小,把该边加入到最小生成树的边集 TE 中, 同时将 V-U 中的该顶点并入到 U 中; 每次选择一个点未经过, 一个点经过, 避免了产生环.
- 反复执行第(2)步,直至 V-U=Ø 为止。
并行
- 该算法在 n 个外部迭代中工作,很难同时执行这些迭代。
- 内循环相对容易并行化
- 假设 p 为进程数,n 为顶点数。
- 邻接矩阵采用一维分块的方式进行分块,距离向量 d 进行相应的分块。
- 在每个步骤中,处理器选择本地最近的节点,然后进行全局约简以选择全局最近的节点。
- 这个节点被插入到 MST 中,并选择广播给所有处理器。每个处理器本地更新其 d 向量的一部分。
2. Prim 并行算法的复杂度。
并行算法每次迭代的时间复杂度为$O(n/p+\text{log}\ p)$
- 选取最近点$O(n/p+\text{log}\ p)$
- 广播$O(\text{log}\ p)$
- 本地更新距离矩阵$O(n/p)$
总时间复杂度为$O(n^2/p+n\text{log}\ p)$
3. 单元最短路径算法的原理
最短路径问题: 如果从图中某一顶点(称为源点)到达另一顶点(称为终点)的路径可能不止一条,如何找到一条路径使得沿此路径上各边上的权值总和达到最小。
边上权值非负情形的单源最短路径问题 => Dijkstra 算法
Dijkstra 算法:本质上是贪心算法。
算法流程
- 初始化:
S ← { v 0 };dist[j] ← Edge[0][j], j = 1, 2, ..., n-1; - 求出最短路径的长度:
dist[k] ← min { dist[i] }, i in V- S;S ← S U { k }; - 修改:
dist[i] ← min{ dist[i], dist[k] + Edge[k][i] }, 对于每一个i in V- S; - 判断:若
S = V, 则算法结束,否则转 2。
4. 单源最短路径算法的并行算法的复杂度。
并行算法每次迭代的时间复杂度为$O(n/p+\text{log}\ p)$
- 选取最近点$O(n/p+\text{log}\ p)$
- 广播$O(\text{log}\ p)$
- 本地更新距离矩阵$O(n/p)$
总时间复杂度为$O(n^2/p+n\text{log}\ p)$
5. 基于 Dijkstra 的并行 All-pair 最短路径算法的复杂度
两种并行策略
- (源分区)在不同的处理器上执行 n 个最短路径问题中的每一个
- 并行时间:$O(n^3/p)$
- 由于$p\leq n$,当$p=n$时,可以达到$O(n^2)$
- (源并行)使用最短路径问题的并行公式来增加并发性
- $T_p=\text{computation}+\text{communication}$
- $T_p=O(n^3/p)+O(n\ \text{log}\ p)$
- 由于$p>n$,当$p=O(n^2\text{log}\ n)$时,可以达到$O(n\ \text{log}\ n)$
6. Floyd 并行算法的复杂度
\[d_{i, j}^{(k)}= \begin{cases}w\left(v_{i}, v_{j}\right) & \text { if } k=0 \\ \min \left\lbrace d_{i, j}^{(k-1)}, d_{i, k}^{(k-1)}+d_{k, j}^{(k-1)}\right\rbrace & \text { if } k \geq 1\end{cases}\]一维块映射

二维块映射
 \(O\left(n^{2} / p\right)+O(3 n \log (\sqrt{p}) / \sqrt{p})\\=O\left(n^{3} / p\right)+O\left(n^{2} \log p / \sqrt{p}\right)\)
当$p=n^2$的时候,可以达到$P(n^2\ \text{log}\ n)$
\(O\left(n^{2} / p\right)+O(3 n \log (\sqrt{p}) / \sqrt{p})\\=O\left(n^{3} / p\right)+O\left(n^{2} \log p / \sqrt{p}\right)\)
当$p=n^2$的时候,可以达到$P(n^2\ \text{log}\ n)$
第十五讲:性能优化之一(任务分派和调度)
1. 负载均衡主要有哪些方式,分别有什么特点
静态分派(Static assignment)
在每个线程运行前,每个线程被分派的任务规模已经被确定。即预先分派每个线程执行的任务。这可以在编译期间分派,也可以在运行期间依据运行参数分派(比如数据大小,线程数量)。
特点:简单;零运行时开销;但不一定能够很好地负载均衡。
半静态分派(「Semi-static」 assignment)
周期性地进行预测并再动态分派,在相邻再分配的时间间隔内, 为静态分派。
特点:运行时开销不大;负载均衡效果一般。
动态分派(Dynamic assignment)
程序在运行时动态地分派任务。
特点:确保负载均衡良好;但增加了运行开销。
2. 静态、动态负载均衡适用的场景是什么
静态分派:任务的开销(执行时间)和任务的数量是可预测的。
半静态分派:任务的开销在较近的未来是可预测的。
动态分派:任务的开销和数量是不可预测的。
3. 如何选择任务的粒度
- 大量的小粒度任务保证了良好的动态负载均衡效果
- 大粒度任务减少了分派管理的开销
选择小粒度:任务数量比处理器多。
选择大粒度:希望尽可能少的任务,以尽量减少管理分配的开销。
理想的粒度取决于工作量和机器。
4. Cilk_spawn 的原理是什么
cilk_spawn func (args);
语义:调用 func,但与标准函数调用不同,调用者可以继续异步执行 func。
cilk_spawn 关键字修饰函数调用语句,以告知Cilk运行系统该函数可能(但不是必须)和调用者并行执行。
这个关键字表明了其修饰的函数可能和当前执行的代码(strand)并行执行,即派生出一个新的线程。
注意,cilk_spawn 抽象没有指定如何或何时计划执行派生调用。只是它们可以与调用者并发运行(以及由调用者生成的所有其他调用)。
5. Cilk_sync 的原理是什么
语义:当当前函数生成的所有调用都已完成时返回。(与派生调用「同步」)
注意:在包含 cilk_spawn 的每个函数的末尾都有一个隐式 cilk_sync(含义:当一个 Cilk 函数返回时,与该函数相关的所有工作都完成了)。
cilk_sync 确实是调度上的一个约束。所有派生调用必须在 cilk_sync 返回之前完成。
6. Cilk_spawn 的调度方式有哪些,各自有什么特点
继续执行:下次执行儿子
-
在执行任何迭代之前,调用方线程派生都可以用于所有迭代。
- 如果没有窃取,执行顺序与删除 cilk_spawn 的程序非常不同。
- 子线程可供其他线程进行窃取(“子线程窃取”)。
孩子优先:后续再执行当前线程
-
调用方线程只创建一个要窃取的项(表示所有剩余迭代的延续)。
-
如果没有发生串列,线程将从工作队列中不断弹出 continuation,并为新的 continuation(更新值为 i)排队。
- 执行顺序与删除派生的程序相同。
- 当前线程可供其他线程进行窃取。
7. Cilk_spawn 中任务在不同线程之间 steal 的过程
人均出列
- 工作队列实现为 dequeue(双端队列)
- 本地线程从「尾部」(底部)推送/弹出
- 远程线程从「头部」(顶部)窃取
- 存在高效的无锁 dequeue 实现
随机选择被窃取目标
- 空闲线程随机选择一个线程尝试从队列顶部窃取
- 从 dequeue 头中窃取……
- 减少与本地线程的争用:本地线程访问 dequeue 的部分与窃取线程不同!
- 偷工作开始调用树:这是一个「大」的作品,所以执行偷的成本摊销(分摊)再未来计算
- 最大化局部性:(结合 run-child-first 政策)本地线程作用于本地调用树的一部分
8. Cilk_sync 的几种实现方式
descriptor:对于每个由cilk_spawn和cilk_sync界定的代码块,创建一个descriptor,来描述这个代码块任务的完成情况。
- id: 标识代码块
- spawn: work 数量
- done: 完成的 work 数量
不偷:如果线程没有窃取任何工作,那么在同步点上就不做任何事。相同的控制流是串行执行的。
stalling join:启动 fork 的线程必须预先形成同步因此,它等待所有生成的工作完成。
贪心策略:当启动fork的线程处于空闲状态时,它将试图窃取新的工作;到达join点的最后一个线程在同步后继续执行。
第十五讲:性能优化之一(局部性、通信和竞争)
1. 吞吐量和延迟的定义
延迟:一个操作实现需要的时间。
吞吐量:单位时间内成功地传送数据的数量。
Throughput = 1 / latency
2. 提高程序吞吐有哪些方法
减少通信时间:异步消息传递
减少占用时间(数据通过系统最慢组件的时间):流水线
降低网络延迟
3. 通信时间和通信代价的定义
通信时间 = 程序通信时间+占有时间+网络延迟
- overhead:处理器用于通信的时间
- occupancy: 数据通过系统最慢组件的时间
通信代价 = 通信时间 - 重叠
- overlap:与其他作业同时进行的通信部分可以是计算或其他通信
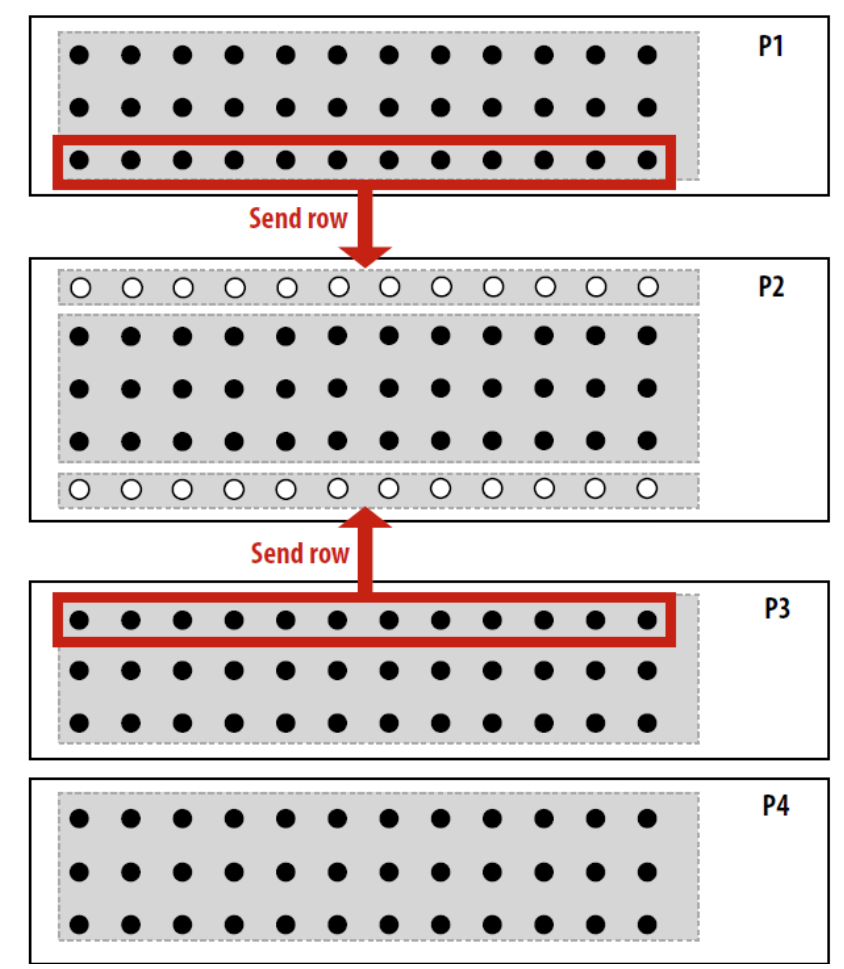
4. 什么是人为通信,什么是天然通信,结合具体的例子说明
天然通信:根据指定的分配(假设无限容量缓存、最小粒度传输等),必须在处理器之间移动才能执行算法的信息。必须发生在并行算法中。通信基于算法。
例子:
网格运算器,行与行之间结点的通信。
人为通信:所有其他通信(人为沟通源于系统实现的实际细节)。
例子:
-
系统需要更小的粒度:所以系统需要更多的通信(程序加载一个 4 字节浮点值,但整个 64 字节高速缓存线必须是内存传输(比需要多 16 倍的通信)
-
系统可能有操作规则造成不必要的通信:(程序存储 16 个连续的 4 字节浮点值,但整个 64 字节高速缓存行,首先从内存加载,然后存储到内存(2x 开销)
- 数据在分布式内存中的位置不佳(数据不驻留在访问数据最多的处理器附近)
- 有限的复制容量(由于本地存储(例如,缓存)太小,无法在访问之间保留相同的数据,因此多次与处理器通信)
5. 减少通信的方法有哪些
- 好的任务分配,降低运算密度。运算密度 = 计算量 / 通信量
- 通过改变遍历顺序来提高时间局部性
- 通过融合循环提高时间局部性
- 通过共享数据提高算术强度
- 利用空间局部性
- 控制通信/数据传输的粒度
- 控制缓存一致性的粒度
- 减少人工通信:blocked data layout
6. 减少竞争的方式有哪些
-
分布式工作队列可以减少争用
-
cuda编程:确定线程块的大小,以便GPU可以在每个GPU内核上安装几个线程块
-
在大型并行机器上创建粒子数据结构网格
- 单元格上并行化
- 粒子层次并行化
- 使用细粒度锁
- 计算部分结果+合并
附录
1. cuda编程
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
// 两个向量加法kernel,grid和block均为一维
__global__ void add(float* x, float * y, float* z, int n)
{
// 获取全局索引
int index = threadIdx.x + blockIdx.x * blockDim.x;
// 步长
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
{
z[i] = x[i] + y[i];
}
}
int main()
{
int N = 1 << 20;
int nBytes = N * sizeof(float);
// 申请host内存
float *x, *y, *z;
x = (float*)malloc(nBytes);
y = (float*)malloc(nBytes);
z = (float*)malloc(nBytes);
// 初始化数据
for (int i = 0; i < N; ++i)
{
x[i] = 10.0;
y[i] = 20.0;
}
// 申请device内存
float *d_x, *d_y, *d_z;
cudaMalloc((void**)&d_x, nBytes);
cudaMalloc((void**)&d_y, nBytes);
cudaMalloc((void**)&d_z, nBytes);
// 将host数据拷贝到device
cudaMemcpy((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy((void*)d_y, (void*)y, nBytes, cudaMemcpyHostToDevice);
// 定义kernel的执行配置
dim3 blockSize(256);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
// 执行kernel
add << < gridSize, blockSize >> >(d_x, d_y, d_z, N);
// 将device得到的结果拷贝到host
cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyDeviceToHost);
// 检查执行结果
float maxError = 0.0;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(z[i] - 30.0));
std::cout << "最大误差: " << maxError << std::endl;
// 释放device内存
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
// 释放host内存
free(x);
free(y);
free(z);
return 0;
}
2. 减少通信代价的方式有哪些
- 减少发送方/接收方的通信开销
- 发送更少的消息,使消息更大(摊销开销)
- 合并(合)并成大的许多小消息
- 减少延迟
- 应用程序编写器:重构代码以利用局部性
- 硬件实现:改进通信架构
- 减少争用
- 复制竞争资源(例如,本地副本、细粒度锁)
- 错开对争用资源的访问
- 增加沟通/计算重叠
- 应用程序编写器:使用异步通信(例如,异步消息)
- 硬件实现:流水线,多线程,预取,无序执行
- 应用程序中需要额外的并发性(并发性多于执行单元的数量)
3. Cache 冲突包含哪些种类
- cold miss: 有限的复制容量(由于本地存储(例如缓存)太小,无法在访问之间保留相同的数据,因此多次与处理器通信)。在顺序程序中不可避免
- capacity miss: 工作集大于缓存。可以通过增加缓存大小来避免/减少。
- conflict miss: 缓存管理策略导致的遗漏。可以通过改变应用程序中的缓存关联或数据访问模式来避免/减少。
- communication miss: 由于并行系统中固有的或人为的通信
参考资料:wu-kan.github.io